万字长文丨微众银行严强:数字经济时代,隐私保护的道与术

编辑 | 周舟 佳慧
核心观点:
数据生产者与数据消费者之间不再是“买卖”关系。
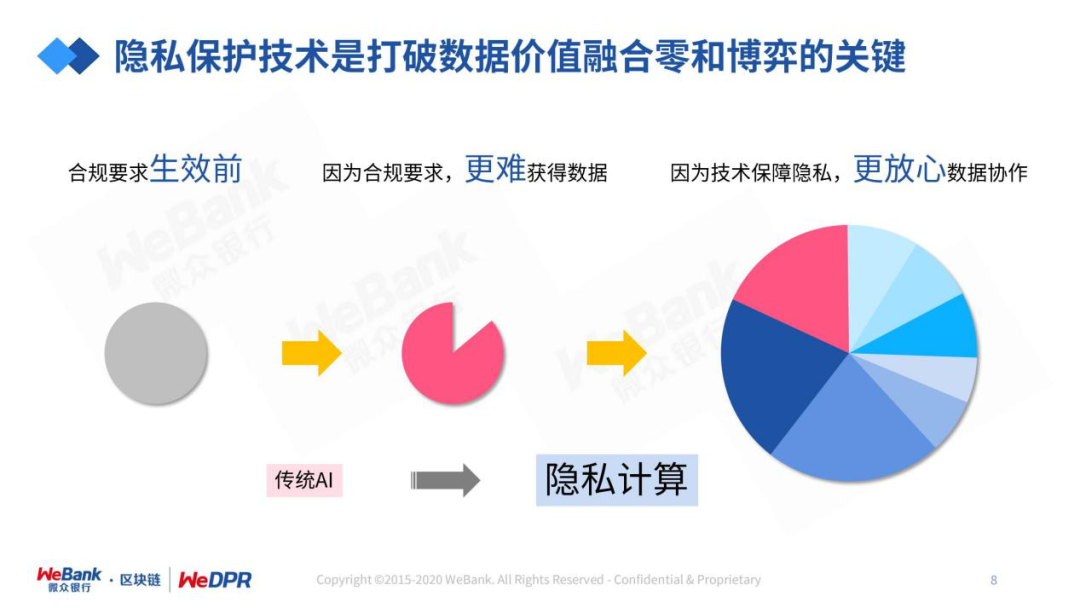
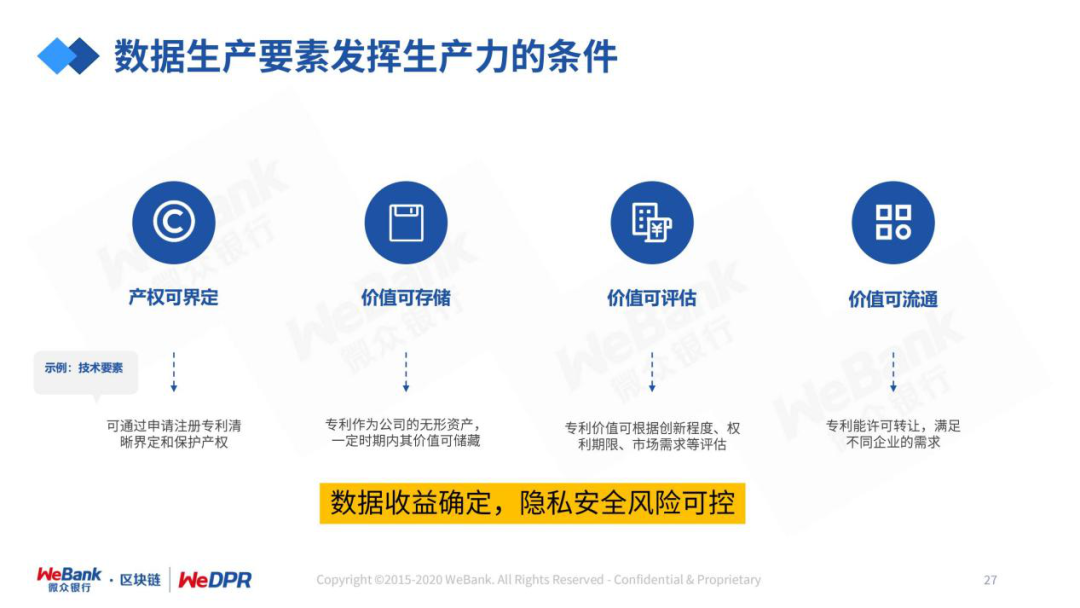
隐私保护技术是打破数据价值融合“零和博弈”的关键。
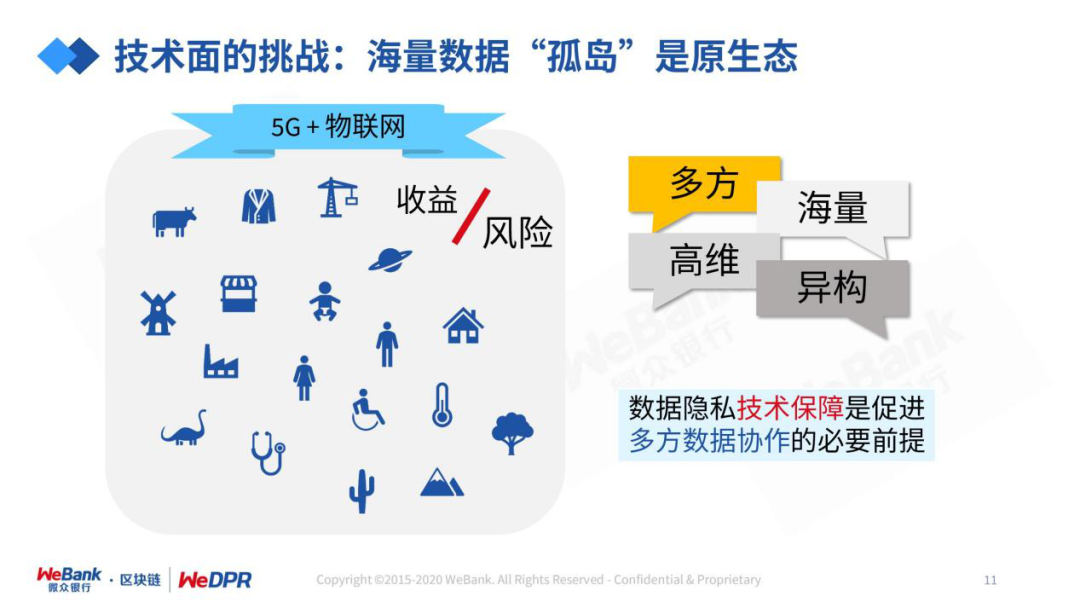
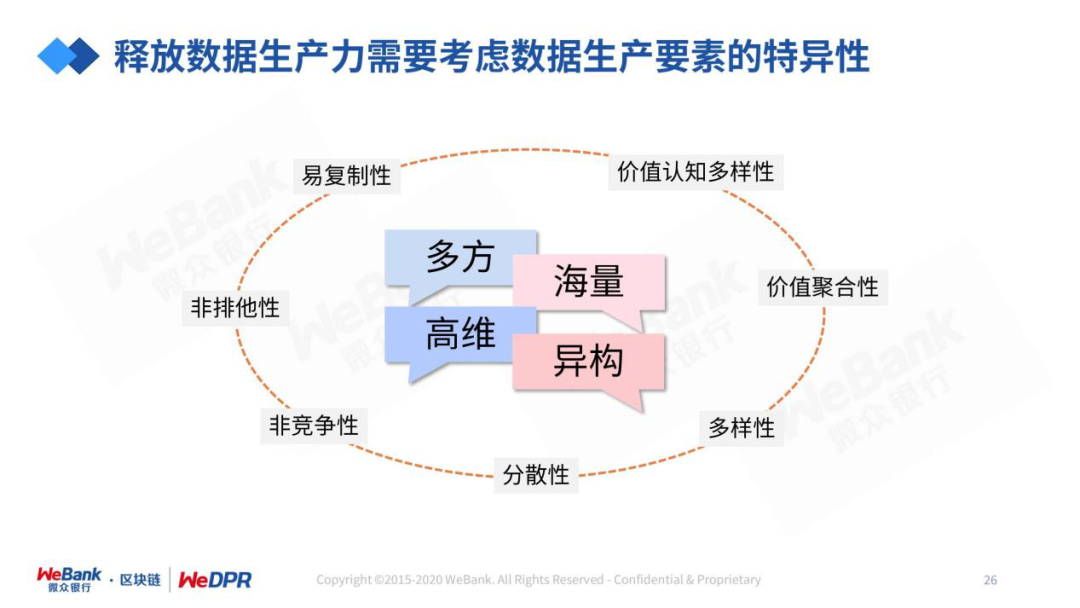
我们需要尊重“数据孤岛”作为数据产业的原生态。
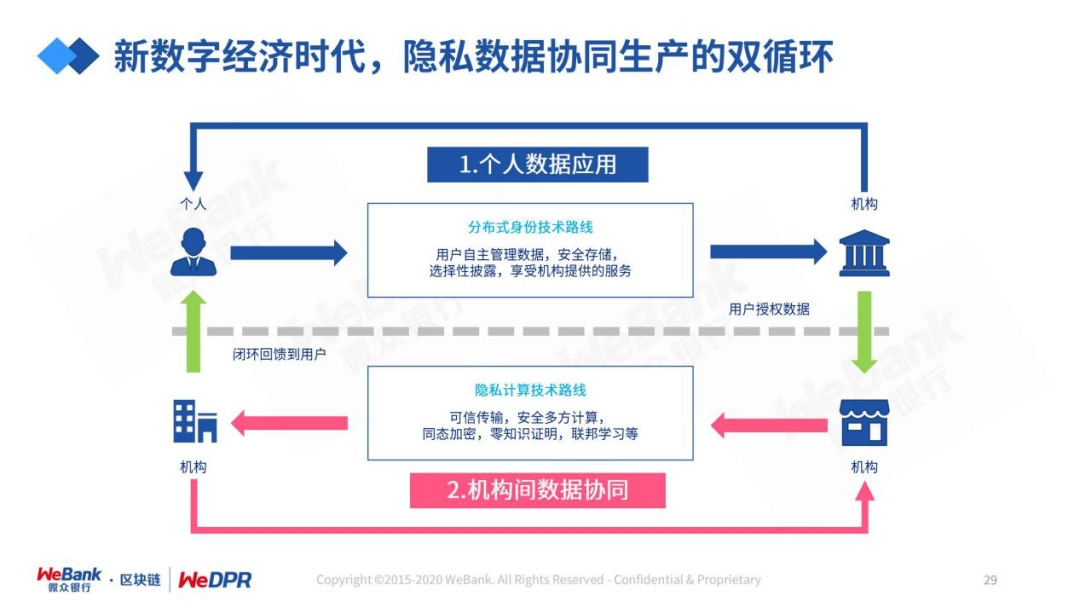
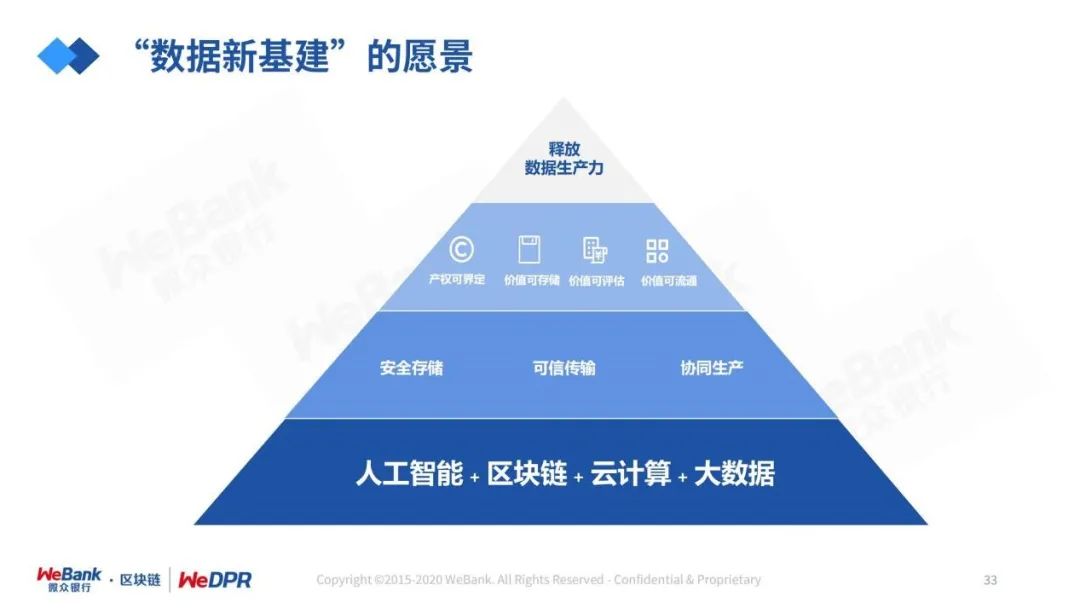
发展健康的数据产业生态,我们需要打通隐私数据协同生产的“双循环”。
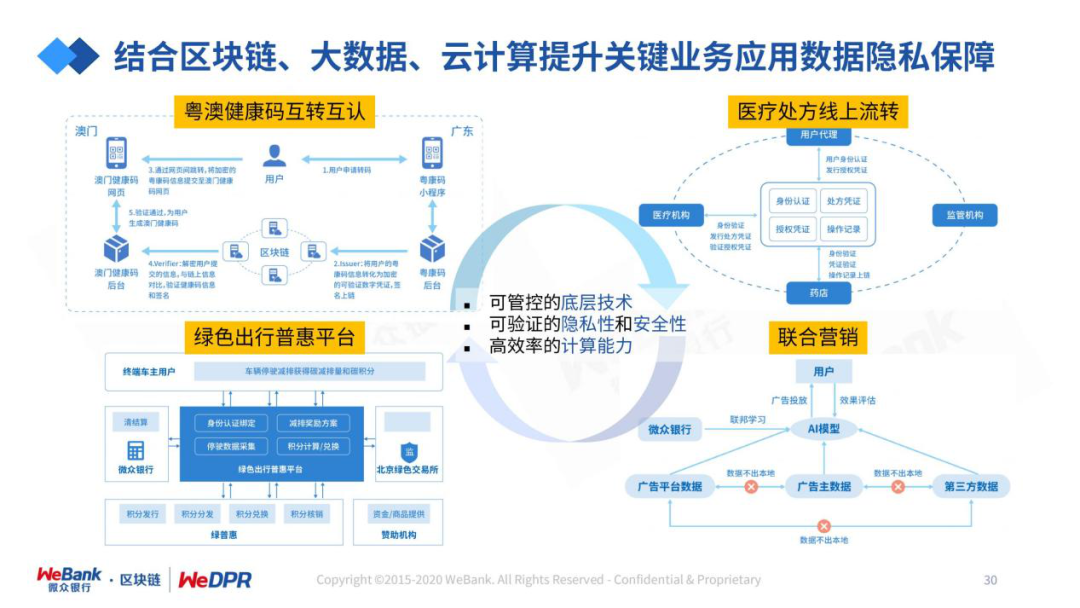
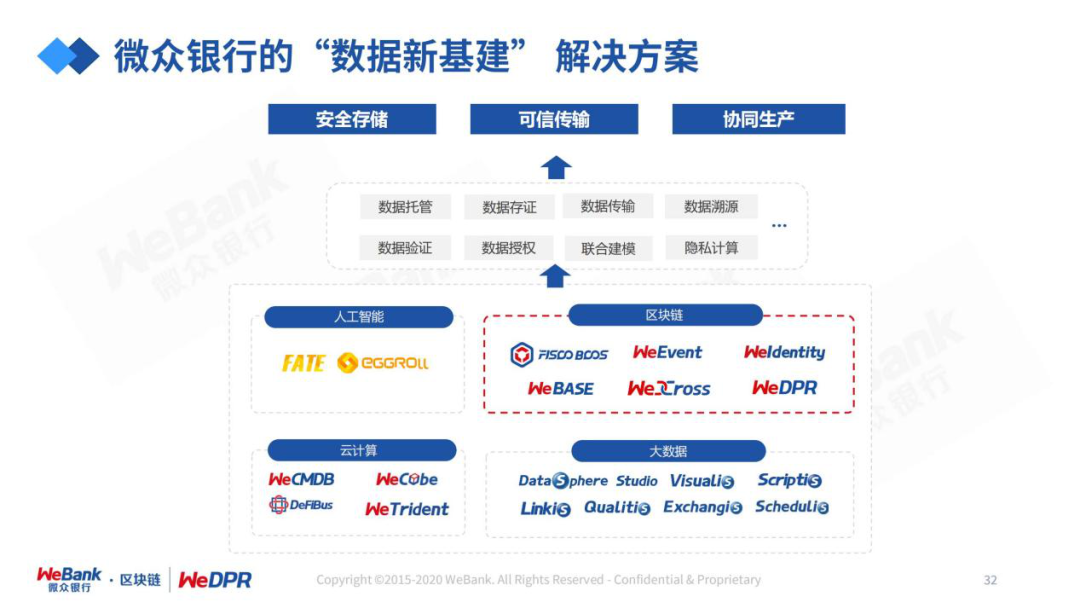
区块链是承载数据信任和价值的最佳技术,对于隐私计算和AI应用中常见的数据品质等难题,都可以通过区块链进行互补或提升效果。




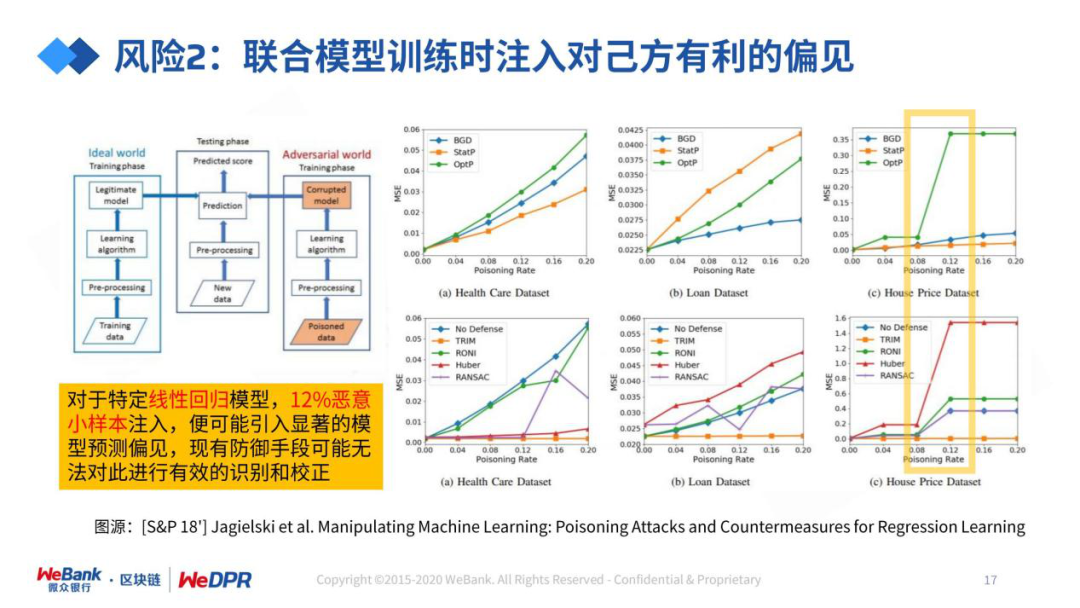

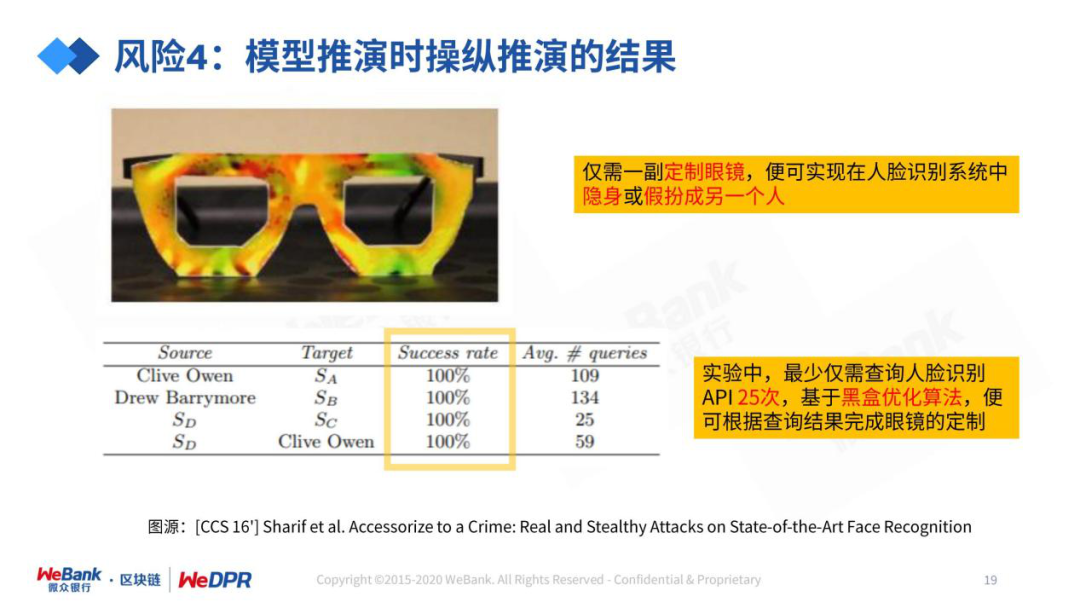
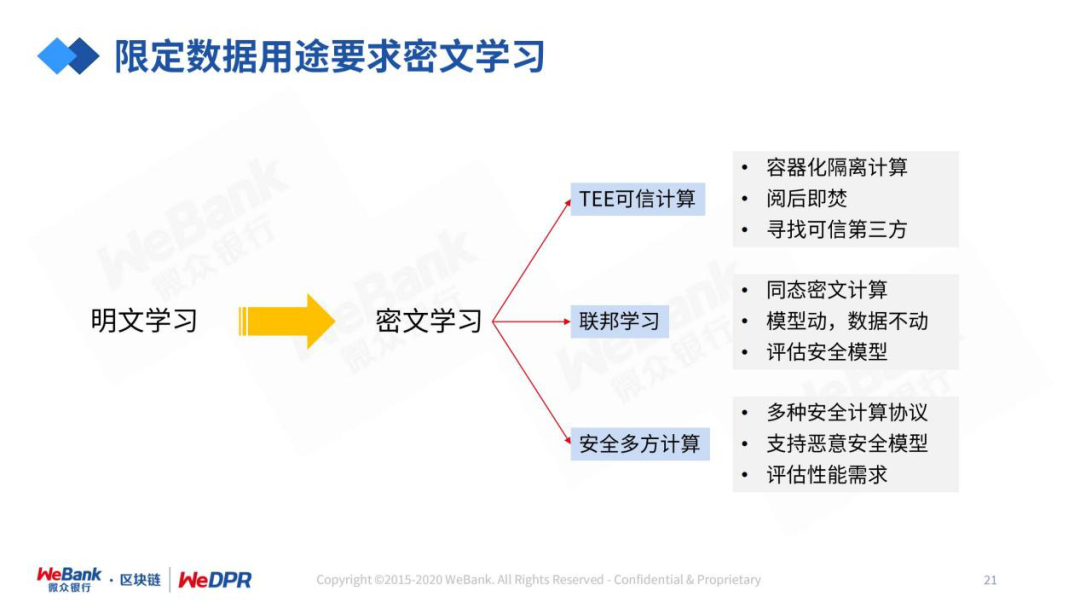
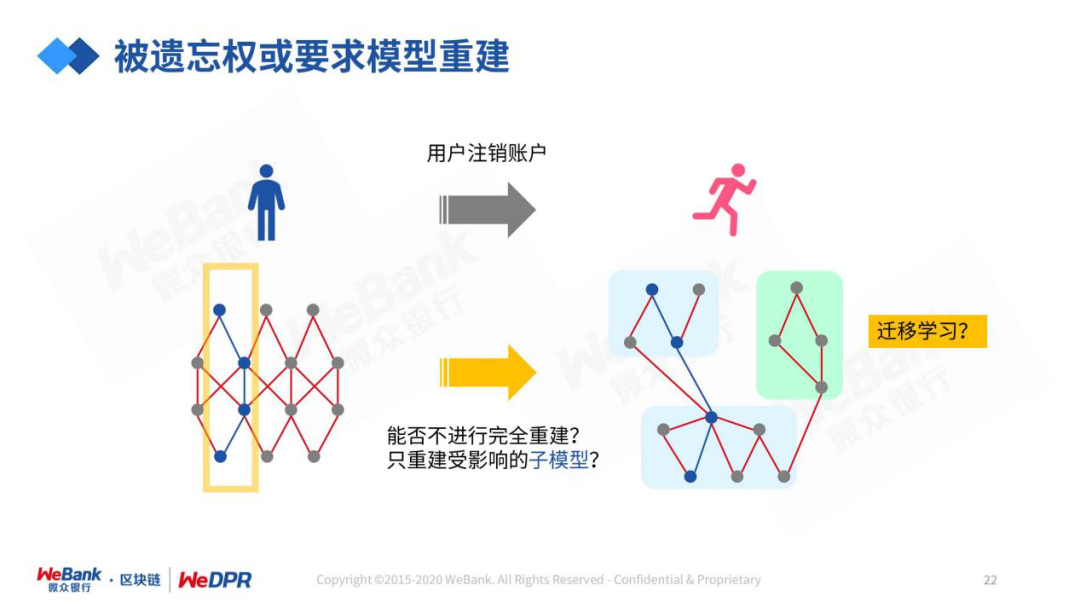




评论
 下载APP
下载APP编辑 | 周舟 佳慧
核心观点:
数据生产者与数据消费者之间不再是“买卖”关系。
隐私保护技术是打破数据价值融合“零和博弈”的关键。
我们需要尊重“数据孤岛”作为数据产业的原生态。
发展健康的数据产业生态,我们需要打通隐私数据协同生产的“双循环”。
区块链是承载数据信任和价值的最佳技术,对于隐私计算和AI应用中常见的数据品质等难题,都可以通过区块链进行互补或提升效果。