
清华大学开源了一项神器,已经在GitHub爆了
今天给分享一个非常实用的开源项目,具体的内容往下看!
开源最前线(ID:OpenSourceTop) 猿妹 整编
整理自:https://github.com/pwxcoo/chinese-xinhua
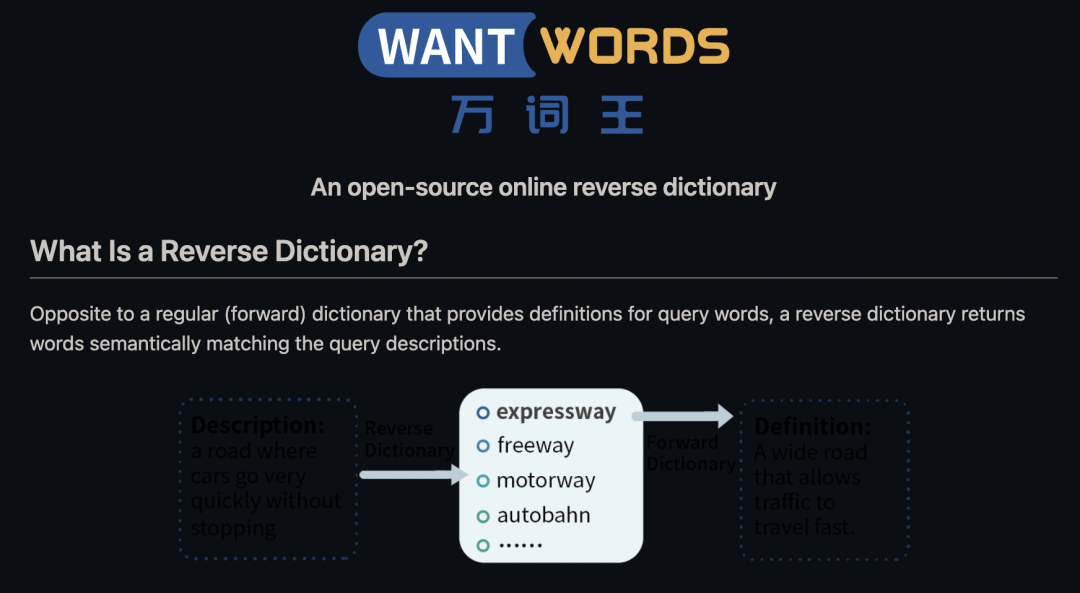
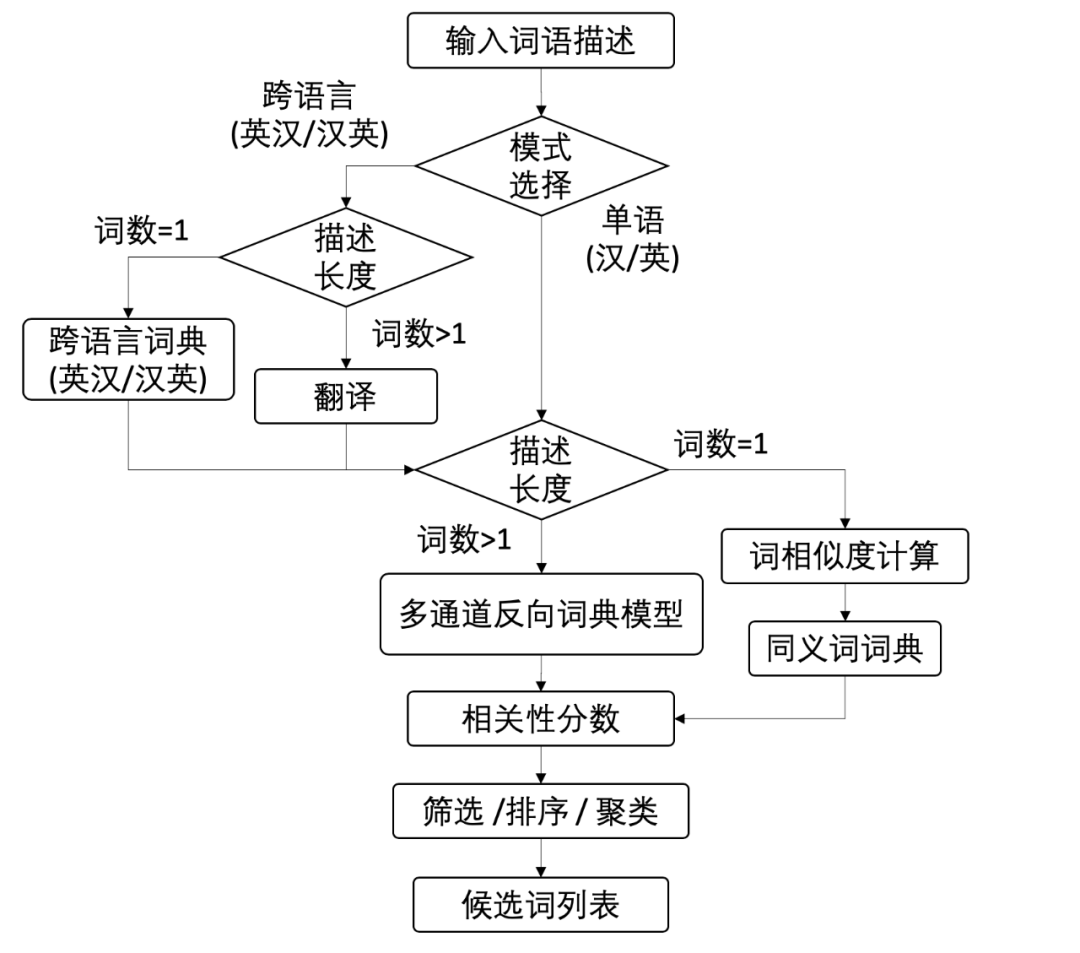
解决“舌尖现象”(tip-of-the-tongue,又称话到嘴边说不出来),即暂时性忘词的问题
帮助语言学习者学习、巩固词汇
改善选词性失语者患者的生活质量,该病的症状是可以识别并描述一个物体,但是无法记起该物体的名字
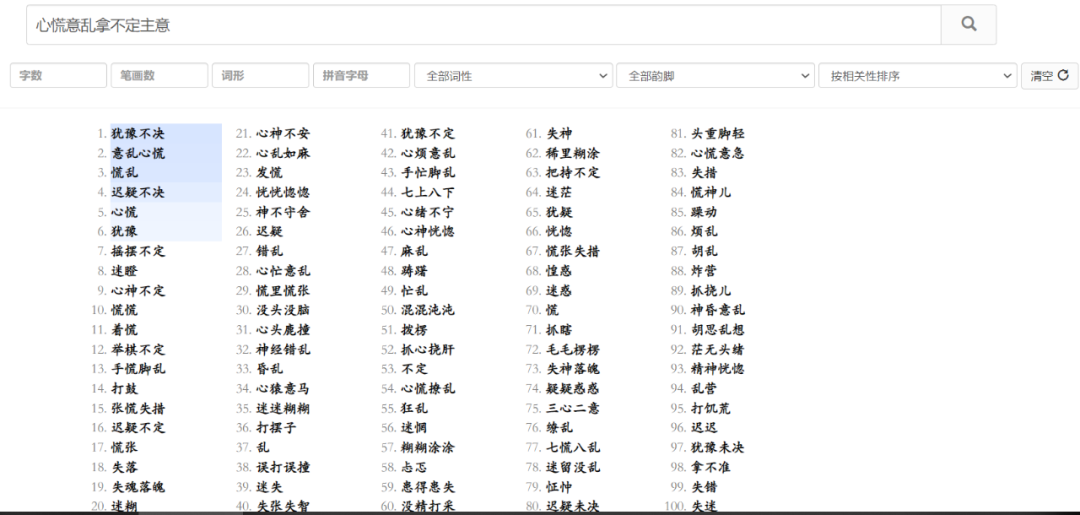
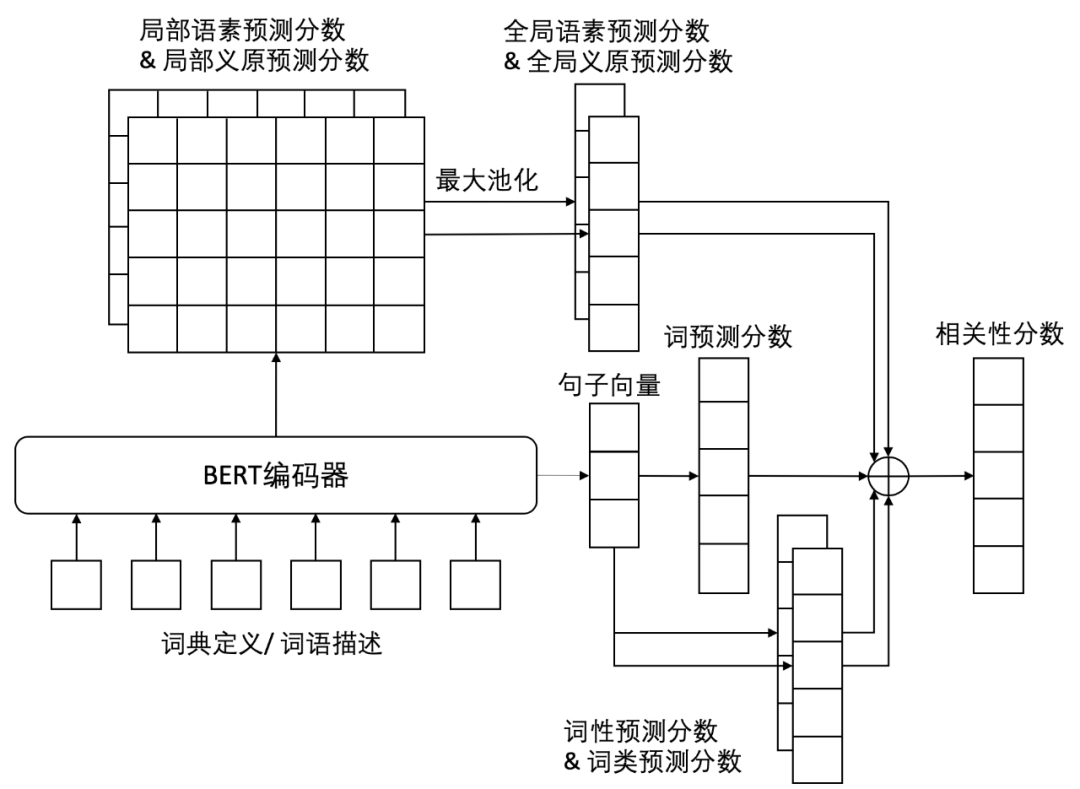
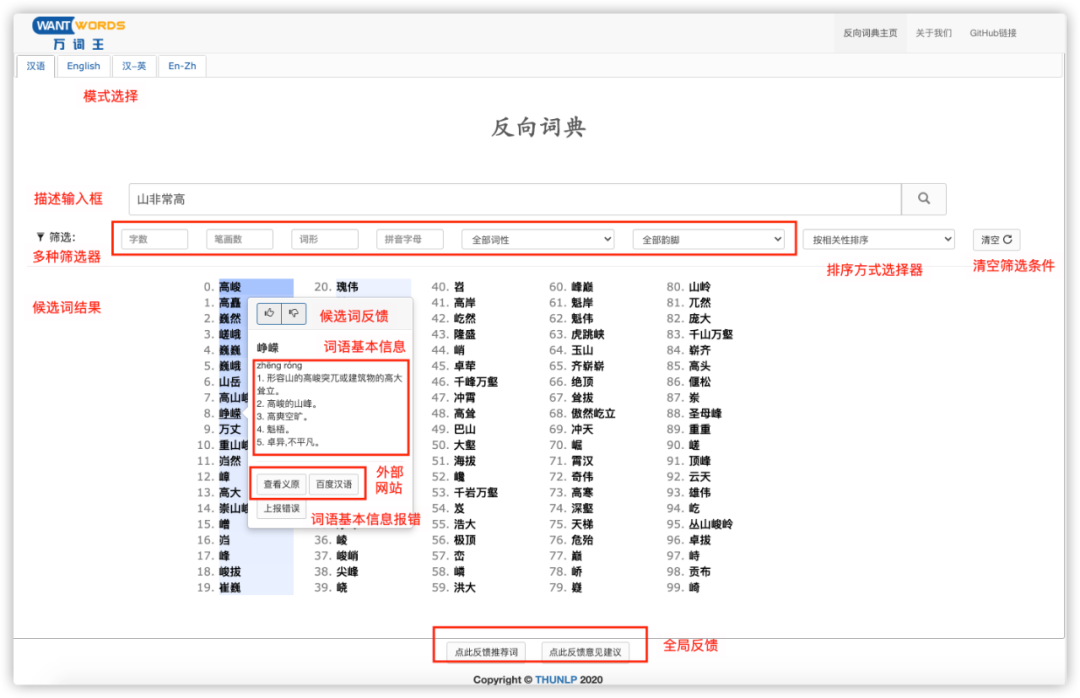
清华大学计算机系自然语言处理与社会人文计算实验室(THUNLP)成立于20世纪70年代末,最初在黄昌宁教授的带领下从事中文信息处理方面的研究工作,是国内开展自然语言处理研究最早、深具影响力的科研单位,同时也是中国中文信息学会(全国一级学会)计算语言学专业委员会的挂靠单位。实验室学术带头人为孙茂松教授,实验室教师队伍还包括刘洋教授和刘知远副教授。实验室面向以中文为核心的自然语言处理前沿基础课题开展系统深入的研究工作,研究领域涵盖计算语言学的核心问题以及社会计算和人文计算,近年来在973、863、国家自然科学基金等项目的支持下,实验室师生在IJCAI、AAAI、ACL、EMNLP等国际顶级会议和期刊上发表多篇高水平学术论文,与CMU、NUS、Google等国际名校和企业有长期良好的合作关系,培养的优秀毕业生大多到清华大学、谷歌、百度、阿里、微软等著名高校和企业工作。
WantWords由THUNLP开发和维护,项目指导教师为孙茂松教授和刘知远副教授,开发团队成员包括岂凡超,张磊,杨延辉。
评论