BoTNet:Bottleneck Transformers for Visual Recognition
【GiantPandaCV导语】
基于Transformer的骨干网络,同时使用卷积与自注意力机制来保持全局性和局部性。模型在ResNet最后三个BottleNeck中使用了MHSA替换3x3卷积。属于早期的结合CNN+Transformer的工作。简单来讲Non-Local+Self Attention+BottleNeck = BoTNet
引言
本文的发展脉络如下图所示:
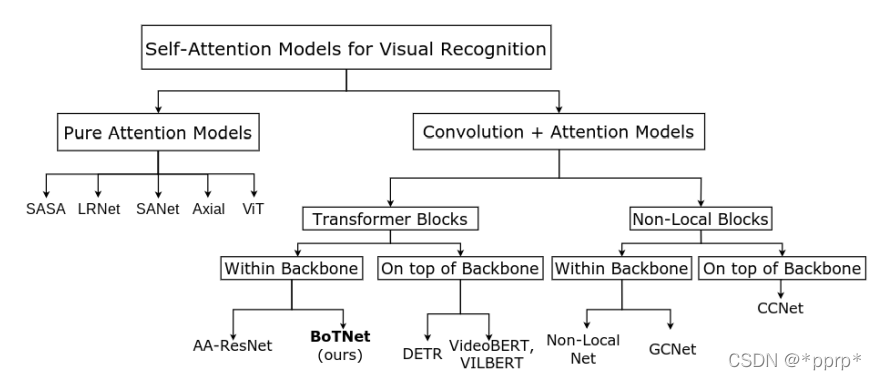
实际上沿着Transformer Block改进的方向进行的,与CNN架构也是兼容的。具体结构如下图所示:
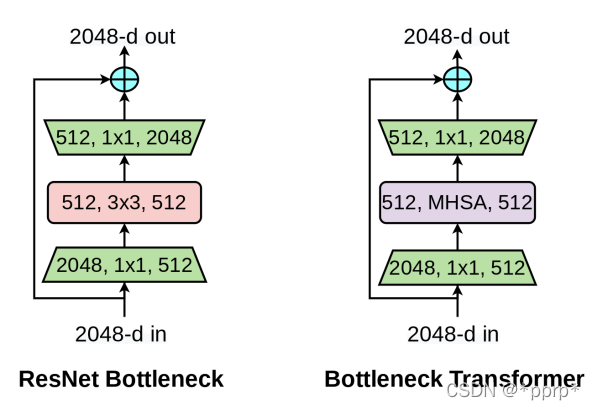
两者都遵循了BottleNeck的设计原则,可以有效降低计算量。
设计Transformer中self attention存在几个挑战:
图片尺寸比较大,比如目标检测中分辨率在1024x1024 内存和计算量的占用高,导致训练开销比较大。
本文设计如下:
使用卷积识别底层特征的抽象信息。 使用self attention处理通过卷积层得到的高层信息。
这样可以有效处理大分辨率图像。
方法
BoTNet中MHSA模块如下图所示:
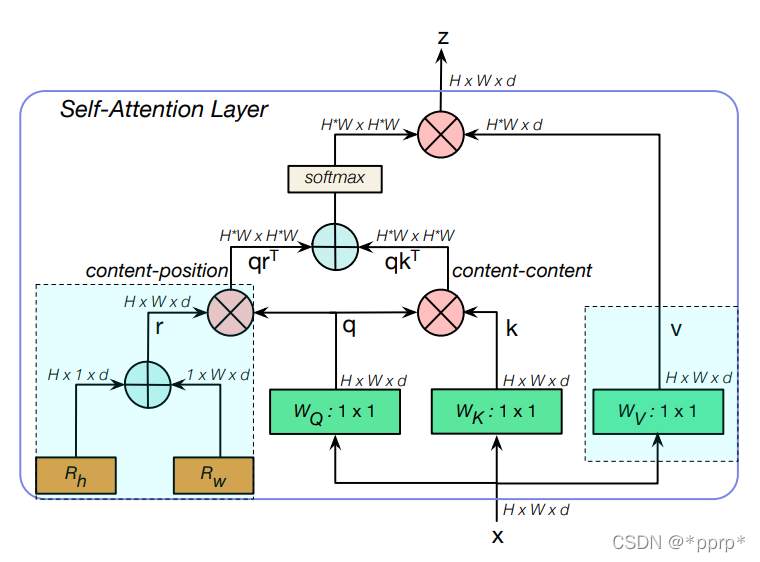
上边的这个MHSA Block是核心创新点,其与Transformer中的MHSA有所不同:
由于处理对象不是一维的,而是类似CNN模型,所以有非常多特性与此相关。 归一化这里并没有使用Layer Norm而是采用的Batch Norm,与CNN一致。 非线性激活,BoTNet使用了三个非线性激活 左侧content-position模块引入了二维的位置编码,这是与Transformer中最大区别。
由于该模块是处理BxCHW的形式,所以难免让人想起来Non Local 操作,这里列出笔者以前绘制的一幅图:
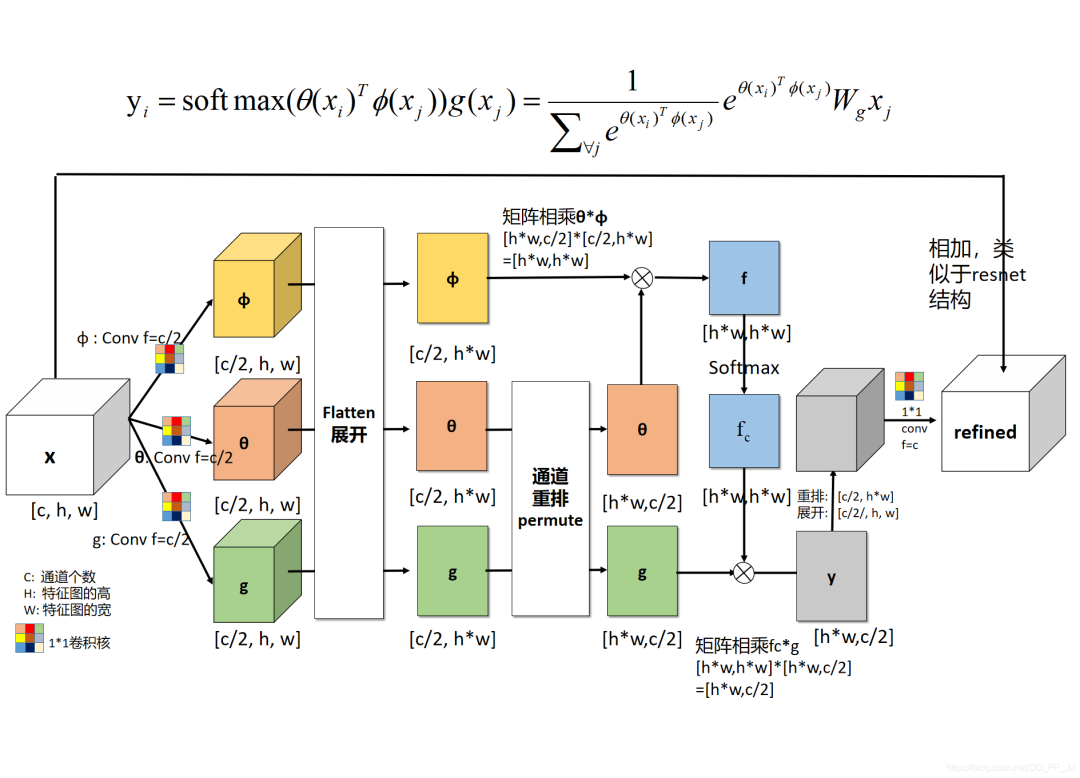
可以看出主要区别就是在于Content-postion模块引入的位置信息。
BoTNet细节设计:
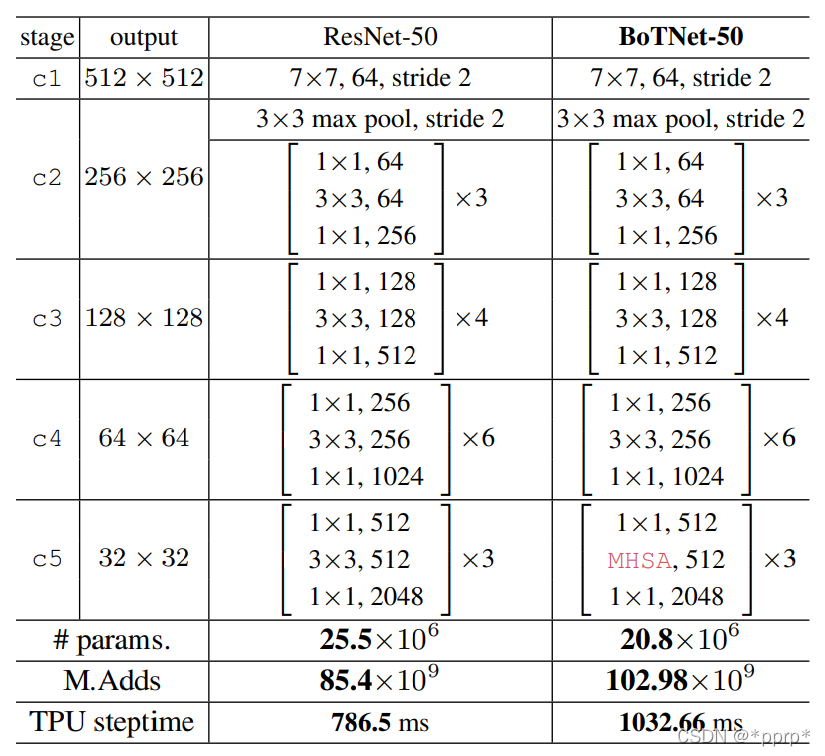
整体的设计和ResNet50几乎一样,唯一不同在于最后一个阶段中三个BottleNeck使用了MHSA模块。具体这样做的原因是Self attention需要消耗巨大的计算量,在模型最后加入时候feature map的size比较小,相对而言计算量比较小。
实验
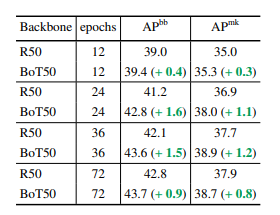
在目标检测和分割领域性能对比
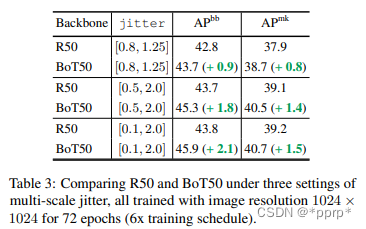
分辨率改变对BoTNet帮助更大
消融实验-相对位置编码
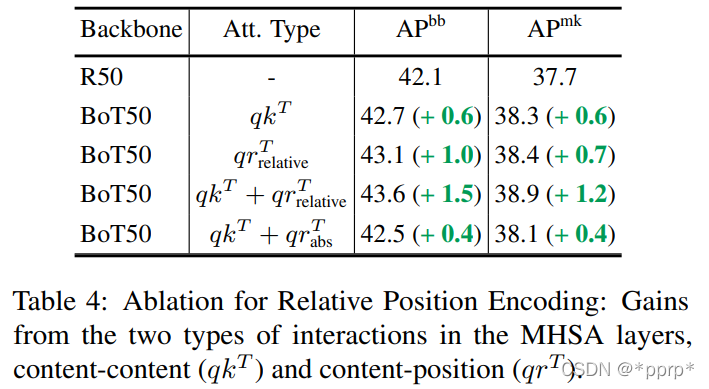
BoTNet对ResNet系列模型的提升
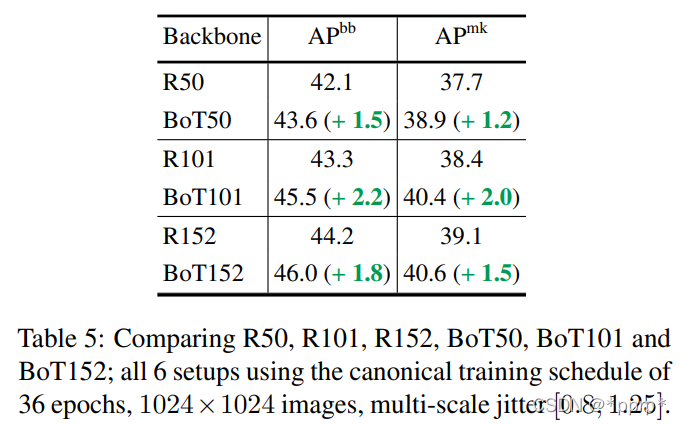
BoTNet与更大的图片适配
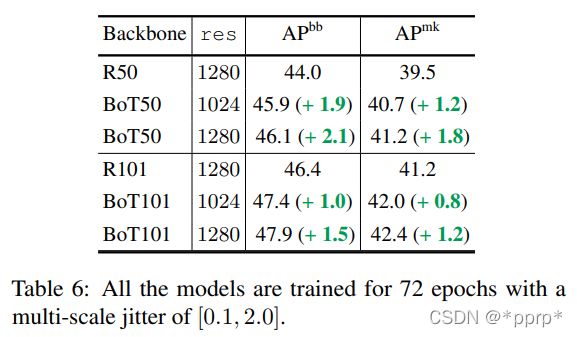
BoTNet与Non-Local Net的比较
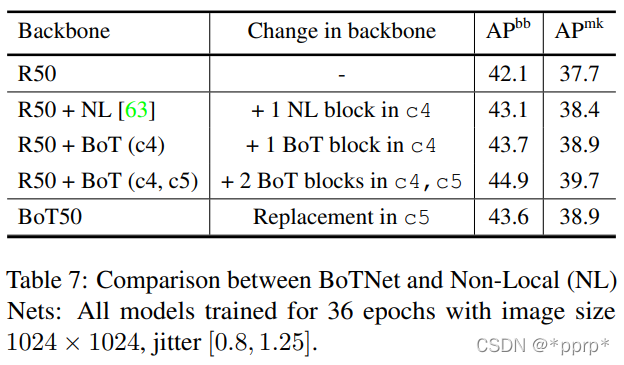
与ImageNet上结果比较
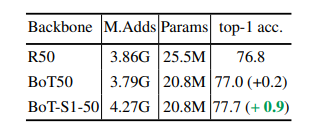
模型放缩的影响
显卡香气飘来,又是谷歌的骚操作,将EfficientNet方法放在BoTNet上:
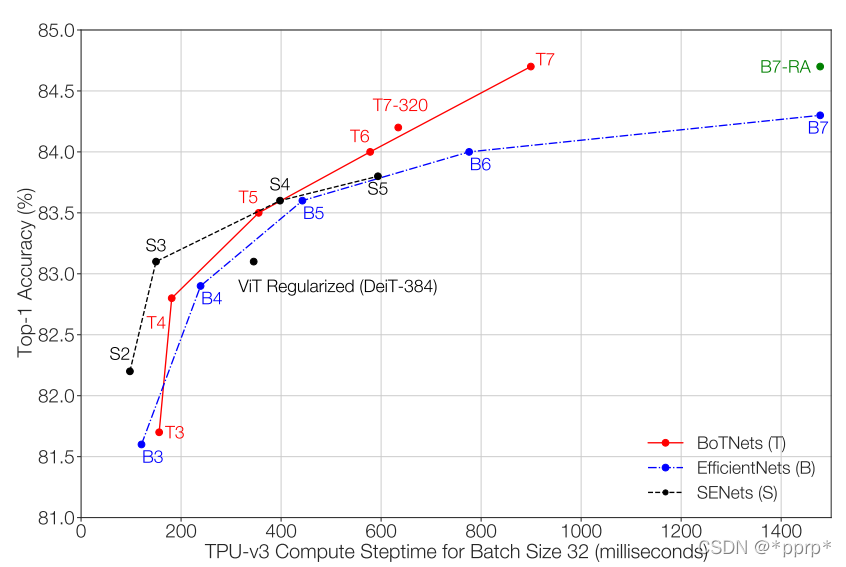
可以看出与期望相符合,Transformer架构带来的性能上限要高于CNN,虽然模型大小比较小的时候性能比较弱,但是模型量变大以后其性能就有了保证。
代码
核心模块:MHSA (由第三方进行实现)
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, heads, n_dims // heads, 1, height]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, heads, n_dims // heads, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k)
content_position = (self.rel_h + self.rel_w).view(1, self.heads, C // self.heads, -1).permute(0, 1, 3, 2)
content_position = torch.matmul(content_position, q)
energy = content_content + content_position
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2))
out = out.view(n_batch, C, width, height)
return out
参考
https://arxiv.org/abs/2101.11605
https://zhuanlan.zhihu.com/p/347849929
https://github.com/leaderj1001/BottleneckTransformers/blob/main/model.py
跑不动ImageNet,想试试Vision Transformer的同学可以看看这个仓库,
https://github.com/pprp/pytorch-cifar-model-zoo
在CIFAR10上测试:
python train.py --model 'botnet' --name "fast_training" --sched 'cosine' --epochs 100 --cutout True --lr 0.1 --bs 128 --nw 4
目前可以在100个epoch内达到验证集91.1%的准确率。