
全面升级!FastReID V1.0正式开源:Beyond reID

极市导读
FastReID V1.0于1月18日发布,本次更新最大的特点是将 FastReID 扩展到了更多的任务上,并在这些任务上均达到了 SOTA 结果。本文介绍了其在知识蒸馏、自动超参搜索、任务支持方面的改进。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
FastReID 从20年6月发布以来,收到了很多用户的反馈,当初的 V0.1 版本存在大量需要优化的部分。经过了最近半年的持续优化,终于在 21年1月18日低调地发布了 FastReID V1.0。这次更新包括非常多的方面,最大的特点是将 FastReID 扩展到了更多的任务上,并在这些任务上均达到了 SOTA 结果。
tldr: 经过对各个模块的优化,我们更新了FastReID V1.0 版本,不仅实现了更快的分布式训练和测试,提供模型一键转码(模型一键导出 caffe/onnx/tensorRT)等功能外,而且还实现了模型蒸馏,自动超参搜索以及更多任务的扩展,比如人脸识别,细粒度检索等等。
下面简单介绍一下 FastReID V1.0 的各项改进。
Embedding 知识蒸馏
深度神经网络一般有较多的信息冗余,同时大模型会导致模型的推理速度变慢,会消耗更多计算资源,并且降低整个系统的响应速度。所以在模型部署的时候需要考虑模型压缩,减小模型的参数量。目前有较多的压缩方式,比如剪枝,量化和蒸馏等。其中蒸馏是一种比较流行的范式,可以保证模型不需要进行结构修改的情况下,得到较大的性能提升。为此,我们在FastReID中支持了模型蒸馏,可以时小模型部署获得更大的精度提升。
虽然蒸馏发展了数十年,我们通过大量的实验发现 Hinton 的 Distilling the Knowledge in a Neural Network[1](https://arxiv.org/abs/1503.02531) 还是最 solid 的选择。同时将原本的蒸馏 loss 优化为具有对称性的 JS Div loss,最后修改蒸馏的 soft label 生成方式。
不同于 softmax 分类 loss,在 embedding 任务中通常会使用效果更好的 margin-based softmax,比如 arcface 等等, 这时直接使用基于 margin 的 logits 生成 soft label 效果很不好,所以将 soft label 修改为去掉 margin 的 logits 输出。
除了可以对 label 进行蒸馏之外,也可以对 feature 进行蒸馏。通过实验了一大堆不 work 的特征蒸馏方法之后,发现 overhaul-distillation[2](https://github.com/clovaai/overhaul-distillation) 可以在 loss 蒸馏的基础上进一步对网络进行提升,所以也将该方法加入到了 FastReID 中。由于overhaul需要对 backbone 进行一些修改,获得 relu 之前的 feature,为此,构建了一个新的 project 而不是直接去 FastReID 里面修改 backbone。
最后我们在 dukeMTMC[3] 上进行实验,使用 r101_ibn 作为 teacher model, r34 作为 student model,可以获得如下的效果提升。
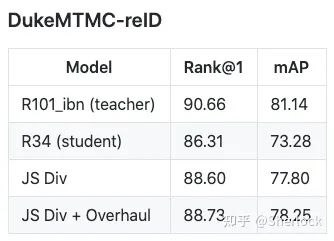
蒸馏的使用也非常简单,只需要首先按照正常的方式训练一个 teacher model,如果只想使用 loss 蒸馏,可以使用 Distiller 作为 meta_arch。如果希望加上 overhaul,也只需要使用 DistillerOverhaul作为 meta_arch 就可以。最后再指定 teacher model 的配置文件和训好的 weights 就可以了。
下面用 R101_ibn 作为 teacher model,R34 作为 student model 举一个例子
# teacher model training
python3 projects/FastDistill/train_net.py \
--config-file projects/FastDistill/configs/sbs_r101ibn.yml \
--num-gpus 4
# loss distillation
python3 projects/FastDistill/train_net.py \
--config-file projects/FastDistill/configs/kd-sbs_r101ibn-sbs_r34.yaml \
--num-gpus 4 \
MODEL.META_ARCHITECTURE Distiller
KD.MODEL_CONFIG projects/FastDistill/logs/dukemtmc/r101_ibn/config.yaml \
KD.MODEL_WEIGHTS projects/FastDistill/logs/dukemtmc/r101_ibn/model_best.pth
# loss+overhaul distillation
python3 projects/FastDistill/train_net.py \
--config-file projects/FastDistill/configs/kd-sbs_r101ibn-sbs_r34.yaml \
--num-gpus 4 \
MODEL.META_ARCHITECTURE DistillerOverhaul
KD.MODEL_CONFIG projects/FastDistill/logs/dukemtmc/r101_ibn/config.yaml \
KD.MODEL_WEIGHTS projects/FastDistill/logs/dukemtmc/r101_ibn/model_best.pth自动超参搜索
炼丹一直困扰着各位调参侠,特别是每次遇到新的场景,就需要重新调参来适应新的数据分布,非常浪费时间。所以决定在 FastReID 中加入了自动超参搜索的功能来解放各位调参侠的双手,让大家可以更好的划水。
通过一系列调研,最后决定使用 ray-tune[4] (https://docs.ray.io/en/master/tune/index.html)这个超参搜索的库。在集成到 FastReID 中间也遇到了非常多的坑,不过最后成功地在 FastReID 中实现了自动超参搜索的功能。
使用方式非常简单,如果你想用 Bayesian 超参搜索跑 12 组试验,可以使用下面的代码就可以开始自动分布式训练,如果有4张卡,那么可以4个试验同步一起跑
python3 projects/FastTune/tune_net.py \
--config-file projects/FastTune/configs/search_trial.yml \
--num-trials 12 --srch-alog "bohb"
另外需要搜索的超参空间需要在 projects/FastTune/tune_net.py 中进行配置,更具体的使用方式可以参考 tutorial(https://github.com/JDAI-CV/fast-reid/issues/293)。
唯一不足的是还不能用pytorch的分布式数据并行,后续有时间会进一步优化,希望这能够成为大家打比赛刷分,做业务的利器。
最多最全的任务支持
我们刚刚发布 FastReID V0.1 时,它只是作为一个目标重识别的 toolbox,支持重识别的业务模型和 research。
后面考虑到各种识别任务的模型结构都长得差不多,所以希望 FastReID 只需要稍微 customize 就能够支持各种不同的任务。
但是每种任务都有自己的一些特殊性,把这些特殊性全部往 FastReID 里面塞肯定是不现实的。为了不引入冗余性,通过对每种 task 单独构建 project 的方式对 FastReID 进行扩展,同时也相当于提供了一些扩展任务的参考写法和 example,毕竟文档一直没有时间写(逃~)。
最后呈现在 FastReID 的 projects 中一共可以支持 image classification (FastCls), attribute recognition (FastAttr), face recognition (FastFace) 和 fine-grained image retrieval (FastRetri) 4 种比较常见的识别任务,同时我们也分别跑了几个 benchmark 以保证代码的实现是正确的。
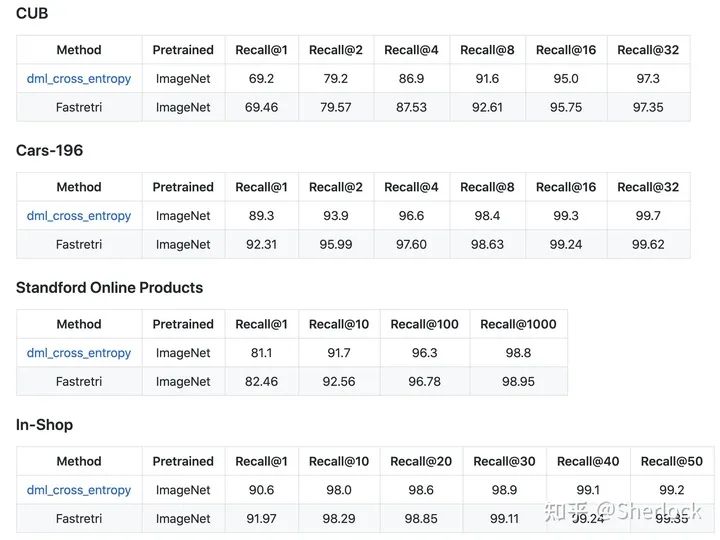
Image Retrieval

Face Recognition
同时大家在 customize 自己的 project 时,也可以将这些 projects 中的东西进行排列组合来实现新的功能,比如将 FastDistill 和 FastFace 组合在一起,就可以实现人脸识别中的模型蒸馏。
总结
一套好的 codebase 对于大家做实验和做业务都起着事半功倍的效果,大家也越来越发现代码的工程质量不仅影响业务模型的研发效率和性能,同时还对研究工作有着影响。
FastReID 不仅仅希望能给 ReID 社区提供稳定高效的代码实现,同时也希望大家能够基于 FastReID 去做算法研究,同时扩展到更多其他任务上。
也希望大家能够踊跃地在 GitHub 上提 issue 和 PR,让我们一起把 FastReID 越做越好。
在此感谢 JD AI 的同事和老师的支持,正是因为大家的努力让 FastReID 变得更好,科研项目也都在 FastReID 上取得了更好的性能。
JDAI-CV/fast-reidgithub.com
也欢迎大家关注 JDAI-CV 中的其他项目
JDAI-CV/centerXgithub.com
JDAI-CV/FaceX-Zoogithub.com
JDAI-CV/Partial-Person-ReIDgithub.com
Reference
推荐阅读
