
服务注册中心状态DOWN问题排查
作者:wls1036
来源:SegmentFault 思否社区
DOWN
DOWN调用该服务就报404错误,因为应用配置了健康检查,怀疑是健康检查没有通过,进入后台调用接口查看检查结果$ curl http://localhost:8080/management/health
{"description":"Remote status from Eureka server","status":"DOWN"}
eureka:
client:
enabled: true
healthcheck:
enabled: true
fetch-registry: true
register-with-eureka: true
instance-info-replication-interval-seconds: 10
registry-fetch-interval-seconds: 10
eureka.client.healthcheck.enabled设置为false后,注册中心恢复正常,因此可以肯定是健康检查的问题。但是在后台没有任何错误,甚至将日志级别调整到最低也未发现错误信息,这个给排查带来很大的困难。排查
对比两个服务的配置文件 对比两个服务的网络数据包 将服务在本地运行(依赖的太多,最终没运行起来)
Remote status from Eureka server可以拿这个作为关键字在idea中进行全局搜索(在maven导入的时候需要把源码一起导入)或者你可以可以在github上搜索,都可以找到这个关键字出处。最终找到位于org.springframework.cloud.netflix.eureka.EurekaHealthIndicator.getStatus中,如下private Status getStatus(Builder builder) {
Status status = new Status(this.eurekaClient.getInstanceRemoteStatus().toString(),
"Remote status from Eureka server");
DiscoveryClient discoveryClient = getDiscoveryClient();
if (discoveryClient != null && clientConfig.shouldFetchRegistry()) {
long lastFetch = discoveryClient.getLastSuccessfulRegistryFetchTimePeriod();
if (lastFetch < 0) {
status = new Status("UP",
"Eureka discovery client has not yet successfully connected to a Eureka server");
}
else if (lastFetch > clientConfig.getRegistryFetchIntervalSeconds() * 2000) {
status = new Status("UP",
"Eureka discovery client is reporting failures to connect to a Eureka server");
builder.withDetail("renewalPeriod", instanceConfig.getLeaseRenewalIntervalInSeconds());
builder.withDetail("failCount", lastFetch / clientConfig.getRegistryFetchIntervalSeconds());
}
}
return status;
}
状态是从org.springframework.cloud.netflix.eureka.EurekaHealthCheckHandler.getStatus中获取 EurekaHealthCheckHandler包含org.springframework.boot.actuate.health.CompositeHealthIndicator,主要由CompositeHealthIndicator执行具体的健康检查逻辑 CompositeHealthIndicator包含一系列的健康检查组件,会依次执行每个组件进行检查(调用health方法)
观察getStatus方法,确实返回了DOWN状态
➜ watch org.springframework.cloud.netflix.eureka.EurekaHealthCheckHandler getStatus "{returnObj}" -x 2
Affect(class count: 1 , method count: 1) cost in 107 ms, listenerId: 4
method=org.springframework.cloud.netflix.eureka.EurekaHealthCheckHandler.getStatus location=AtExit
ts=2021-03-24 09:38:03; [cost=13.776747ms] result=@ArrayList[
@InstanceStatus[
UP=@InstanceStatus[UP],
DOWN=@InstanceStatus[DOWN],
STARTING=@InstanceStatus[STARTING],
OUT_OF_SERVICE=@InstanceStatus[OUT_OF_SERVICE],
UNKNOWN=@InstanceStatus[UNKNOWN],
$VALUES=@InstanceStatus[][isEmpty=false;size=5],
name=@String[DOWN],
ordinal=@Integer[1],
],
]
观察CompositeHealthIndicator的health方法
➜ watch org.springframework.boot.actuate.health.CompositeHealthIndicator health "{returnObj,target.indicators}" -x 2
Press Q or Ctrl+C to abort.
Affect(class count: 2 , method count: 1) cost in 194 ms, listenerId: 6
method=org.springframework.boot.actuate.health.CompositeHealthIndicator.health location=AtExit
ts=2021-03-24 09:46:04; [cost=11.390849ms] result=@ArrayList[
@Health[
status=@Status[DOWN],
details=@UnmodifiableMap[isEmpty=false;size=7],
],
@LinkedHashMap[
@String[discoveryClient]:@Holder[org.springframework.cloud.client.discovery.health.DiscoveryCompositeHealthIndicator$Holder@47625d8a],
@String[diskSpaceHealthIndicator]:@DiskSpaceHealthIndicator[org.springframework.boot.actuate.health.DiskSpaceHealthIndicator@3f01e628], @String[redisHealthIndicator]:@RedisHealthIndicator[org.springframework.boot.actuate.health.RedisHealthIndicator@17b54981], @String[dbHealthIndicator]:@DataSourceHealthIndicator[org.springframework.boot.actuate.health.DataSourceHealthIndicator@10534a8a], @String[refreshScopeHealthIndicator]:@RefreshScopeHealthIndicator[org.springframework.cloud.health.RefreshScopeHealthIndicator@2284c82d], @String[configServerHealthIndicator]:@ConfigServerHealthIndicator[org.springframework.cloud.config.client.ConfigServerHealthIndicator@4ec50d1a],
@String[hystrixHealthIndicator]:@HystrixHealthIndicator[org.springframework.cloud.netflix.hystrix.HystrixHealthIndicator@5c5c6962],
],
]
org.springframework.cloud.client.discovery.health.DiscoveryCompositeHealthIndicator$Holder
org.springframework.boot.actuate.health.DiskSpaceHealthIndicator
org.springframework.boot.actuate.health.RedisHealthIndicator
org.springframework.boot.actuate.health.DataSourceHealthIndicator
org.springframework.cloud.health.RefreshScopeHealthIndicator
org.springframework.cloud.config.client.ConfigServerHealthIndicator
org.springframework.cloud.netflix.hystrix.HystrixHealthIndicator
AbstractHealthIndicator所以只要观察这个就行观察AbstractHealthIndicator health方法
➜ watch org.springframework.boot.actuate.health.AbstractHealthIndicator health "{returnObj,target}" -x 2
...
method=org.springframework.boot.actuate.health.AbstractHealthIndicator.health location=AtExit
ts=2021-03-24 09:50:55; [cost=7.652594ms] result=@ArrayList[
@Health[
status=@Status[DOWN],
details=@UnmodifiableMap[isEmpty=false;size=1],
],
@RedisHealthIndicator[
VERSION=@String[version],
REDIS_VERSION=@String[redis_version],
redisConnectionFactory=@JedisConnectionFactory[org.springframework.data.redis.connection.jedis.JedisConnectionFactory@4c91526e],
],
]...
public abstract class AbstractHealthIndicator implements HealthIndicator {
@Override
public final Health health() {
Health.Builder builder = new Health.Builder();
try {
doHealthCheck(builder);
}
catch (Exception ex) {
builder.down(ex);
}
return builder.build();
}
}
builder.down(ex);我们只需观察这个方法就能知道报什么错➜ watch org.springframework.boot.actuate.health.Health$Builder down "{params}" -x 2
....
@RedisConnectionFailureException[org.springframework.data.redis.RedisConnectionFailureException: Cannot get Jedis connection; nested exception is redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool],
],
]
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
#redis\u4e3b\u673a
host=redis
#redis\u7aef\u53e3
port=6379
#\u6388\u6743\u5bc6\u7801
password=*****
#\u8d85\u65f6\u65f6\u95f4\uff1a\u5355\u4f4dms
timeout=100000
# curl redis
curl: (6) Could not resolve host: redis
$svc_name.$namespace.svc.cluster.local
# curl redis.k2-infrastructure.svc.cluster.local
Failed to connect to redis.k2-infrastructure.svc.cluster.local port 80: No route to host
解决方案
$namespace.svc.cluster.local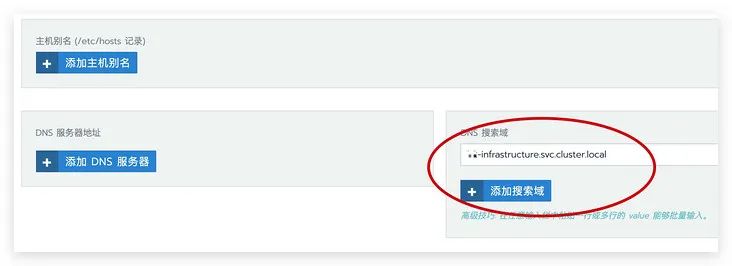
dnsConfigapiVersion: apps/v1
kind: Deployment
...
spec:
....
spec:
....
dnsPolicy: ClusterFirst
dnsConfig:
searches:
- xx-infrastructure.svc.cluster.local
status: {}

评论