
表妹去面试被问到索引,结果梅开二度
hello大家好 我是大家的学习成长小伙伴Captain
表妹:亲爱的面试官,感谢您上次能够理解我家中的鸡蛋,而且还不计前嫌,再一次给我面试的机会,这次我一定好好抓住
面试官:嗯行,挺好,上次我们聊到了数据mysql,聊了下索引,感觉你也不是很熟悉的样子,那我们换个角度吧
表妹:啊啊啊!!好的,亲爱的面试官(本来都好好准备了引擎了,结果不问了,放马过来吧
面试官:你说说平时你是怎么解决慢查询,怎么加速SQL查询的
表妹:简单啊,加索引,用啥查就加啥索引就可以了
面试官:还有吗,就这些吗
表妹:就这些啊(天真的眼神看着面试官
面试官:那你说说索引都有哪些啊,底层都是怎么存储的,怎么加速查询的
表妹:我比较熟悉的索引就主键索引、普通索引、唯一索引和Hash索引,底层存储结构就是两种B+树和Hash(Innodb引擎),加速查询主要是由于B+树的特殊结构,可以降低树的层次减少IO次数,就可以查询出数据
而Hash存储就是和HashMap一样的,这种的查询优点就是善于单值查询,缺点就是不擅长区间查询,而B+树便可以解决这个问题
面试官:不错,你能给我分析一下B+树为什么可以解决区间查询吗
表妹:(坏了,这个昨天光吃鸡蛋了,忘了问了)那个,面试官,我突然想起来,家里还有几块紫薯在煮着,我得赶紧回去,要不紫薯变黑薯了
面试官:行吧,你先回去吧,下次再继续面试,这次记得把该关的都关完了

于是乎,表妹回来了,以质问的语气问我:喂,你这家伙,昨天怎么给我讲索引的时候,没给我说索引的底层的B+树的原理啊,害的我今天出丑
这不能怪我啊,你问我的时候,我本来想继续给你讲下去的,可是你却一直在那里吃鸡蛋,吃着鸡蛋还看着鱿鱼游戏,光喊一二三木头人了,你都没寻思听我讲话了诶
算了算了,我就不责怪你了,你今天必须把索引给我讲明白,不讲明白今天没玩,妹妹看似很生气的说到
索引种类
主键索引
主键索引,不允许null,这个是底层构建B+树的依据,可以提高查询效率,并提供唯一性约束,一张表中只能有一个主键,被标志为自动增长的字段一定是主键,但是主键并不一定自动增长,一般把主键定义在无意义的字段上,主键的数据类型也最好是数值
B+树的构建就是根据主键索引来构建,如果我们未指定主键,MySQL会自动创建一个列来作为主键索引
普通索引
最普通的索引,没有任何限制,该唯一索引指向的是主键索引,通过唯一索引找到主键索引,然后去主键索引构建的B+树中回表查询具体数据,如果只需要主键字段,则不需要回表即可满足条件
唯一索引
特性就是唯一,可以为null,可以把唯一性约束放在一个或者多个列上,这些列或列的组合必须有唯一的。但是,唯一性约束所在的列并不是表的主键列。
唯一性约束强制在指定的列上创建一个唯一性索引。在默认情况下,创建唯一性的非聚簇索引,但是,也可以指定所创建的索引是聚簇索引。
存在唯一键冲突的时候的避免策略
insert ignore
会忽略数据库中已经存在的数据(根据主键或者唯一索引判断),如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据.
replace into
首先尝试插入数据到表中。如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据,否则,直接插入新数据。使用replace into,你必须具有delete和insert权限
insert on duplicate key update
如果在insert into 语句末尾指定了on duplicate key update,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE;如果不会导致重复的问题,则插入新行,跟普通的insert into一样。使用insert into,你必须具有insert和update权限
如果有新记录被插入,则受影响行的值显示1;如果原有的记录被更新,则受影响行的值显示2;如果记录被更新前后值是一样的,则受影响行数的值显示0
全文索引
fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like
MySQL可以通过建立全文索引,利用查询关键字和查询列内容之间的相关度进行检索,可以利用全文索引来提高匹配的速度。比如实现全匹配模糊查询。
mysql的全文索引性能非常不稳定,不建议生产环境使用。需要使用全文检索的地方,建议使用ES
空间索引
MyISAM 存储引擎支持空间数据索引R树,可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
组合索引
多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合
索引的优缺点
大大加速数据的检索速度
减少磁盘IO,最根本也是提高了速度
创建和维护索引需要耗费时间,表中的数据进行增加、修改和删除的时候,索引也需要动态维护
索引需要占据额外的存储空间,所以这并不意味着索引越多越好,有些小表可能进行全表扫描速度更快,因为使用索引需要进行回表查询,就是先通过索引找到主键索引,再通过主键索引去构建的B+树中去查找整条数据
索引底层结构
我们就分析最常用的两种索引结构B+树索引和Hash索引,而myisam和innodb引擎中的B+树又是有点区别的,这个我们下面会介绍
在了解B+树之前,先看下B树
B树
B树,多路查找树,体态矮胖,可以更少的进行磁盘IO,想象一下,树的每一层代表一次磁盘IO

描述一棵B树时需要指定它的阶数,阶数表示了一个节点最多有多少的孩子节点,一般使用字母m表示阶数。
当m取2时,就是我们常见的二叉搜索树。
一棵m阶的B数定义如下:
(1)每个节点最多有m-1个关键字
(2)根节点最少可以只有一个关键字
(3)非根节点至少有Math.ceil(m/2)-1个关键字
(4)每个节点的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它
(5)所有叶子节点都位于同一层,或者说根节点到每个叶子节点的路径长度都相同
B树,最大的优点就是比平常的二叉树更矮胖,而这样就可以利用更矮胖的结构存储更多的数据,这样也就会让IO次数减少,B树的特点在于叶子节点和非叶子节点都会存储数据,而存储的是不同的数据,这也就意味着整棵树会组成全量的数据
也就是可能还没有查询到最底层就可能已经拿到想要的数据了,不仅存储着数据,还起着索引的结构
B+树
B+树是对B树的变形,最大的区别是非叶子节点不保存数据,而只用于存储索引,所有的数据都保存到叶子节点中

B树是所有节点(包含叶子节点)组成了所有的数据,而B+树是所有数据均存储到叶子节点上
同时B+树的所有叶子节点都有相邻叶子节点的指针,也就是所有叶子节点组成了一个链表
看到这两句话,不知道大家有没有一种豁然开朗的感觉嘞
第一句,所有数据都存储到叶子节点,而非叶子节点都不会存储相应的全部数据,也就是mysql一张表的一条数据,非叶子节点都只会存储其中的一个索引字段,而不是该对象的所有字段
这意味着什么呢,这也就意味着每个相同存储大小的节点,可以存储更多的索引数据了,比如一个节点1KB,按照B树只能存储100条数据,而按照B树可以存储1000条数据,造成的直接后果就是这个树变得更矮更胖了!
明白了不,更矮更胖也就意味着可以通过更少的IO次数来获得想要的数据
第二句,B+树的所有叶子节点都有相邻叶子节点的指针,也就是所有叶子节点组成了一个链表,这样做的优点就是支持范围查询,再回想一下B树的结构,B树也不是不支持范围查询,而是会效率很低,它需要来回的IO,才能把周围的数据都找出来,这样是很糟糕的设计
而B+树的结构就可以直接通过底层的指针便可以找到周边的数据了,就是一个排好序的链表,只需要找到其中的部分的有序数据,只需要找到开头和结尾便可以确定所有的数据了
关于数据结构,这里我给大家推荐一个网站,可以学习下各种数据结构,观看数据组成原理:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B树和B+树的对比
B+树的磁盘IO更低,查询效率更高
B+树的非叶子节点并不会存储整条数据,而是存储数据的索引,这句话是针对于MySQL表来说,因此非叶子节点可以用同样的存储空间,存储更多的索引数据,也就使得B+树更加的矮胖,可以一次性读入内存中的关键字也就越多,磁盘的IO次数也就降低了,查询效率也就更高
查询效率更加稳定
非叶子节点并不是最终指向文件内容的节点,也就意味着如果需要获取更多数据,都需要通过非叶子节点索引找到叶子节点,也就是任何关键字的查找都需要走一条从根节点到叶子节点的路径,所以查询效率也更加稳定
B+树遍历效率更高
由于B+树特有的结构,只需要遍历所有叶子节点的数据便可以实现整棵树的遍历
B+树更好的支持范围查询
范围查询在现在系统中是必不可少的,B+树的叶子节点都有相应的指针指向前后节点,组成链表,所以更好的支持范围查询。而B树效率则会很低
上面说了这么多种树,为的就是给大家理解mysql底层索引和数据的存储结构跟上Captain的步伐,继续冲
Hash索引
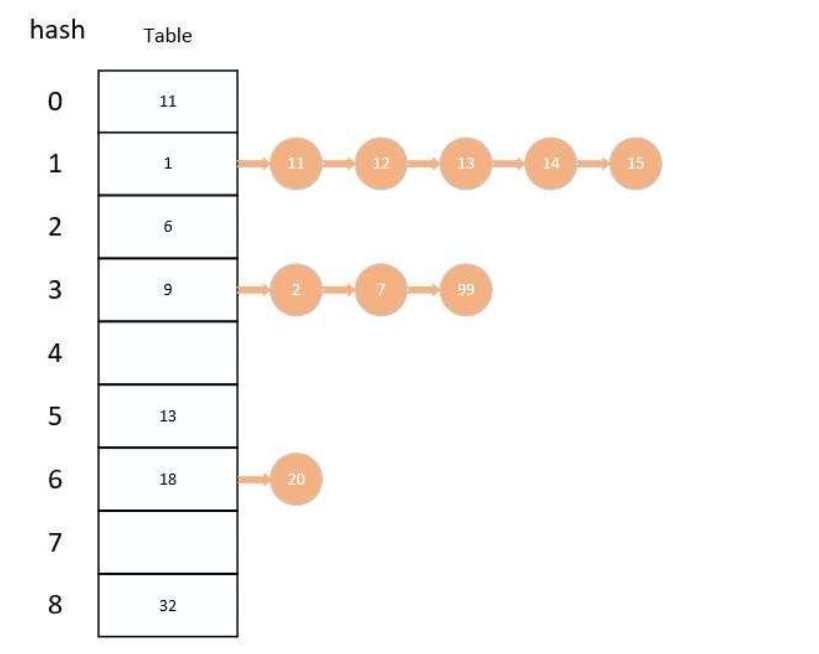
上面这是大家最熟悉的HashMap的结构,就是通过数组+链表的形式来存储数据,存储数据的方式就是通过对每一个数据进行Hash运算,通过Hash运算就可以得到一个位置的数据,我们当然也需要根据数组的大小来锁定这个Hash取值的范围
比如我们数组大小是16,我们就可以通过Hash运算得到一个这个范围的数据,然后把这个数据放到相应的数组的位置,如果该位置为空,就直接把数据放到这里。而不为空,就涉及到hash冲突的处理了,这里就不多讲了,就是以数组元素作为链表的头节点往后延伸链表
哈希索引,存储结构就是这种,而这种的最大优点就是查询速度非常快,查询复杂度O(1),查询方式就是通过计算查询索引的hash值,直接找到数组位置即可,然后按照数组位置进行一个一个的对比,直到找到相应的索引就行
所以啊,最快的就是直接数组第一个元素就是,直接就找出来了,否则的话,就一个一个对比下,直到找到即可
自适应哈希索引
在mysql中还有一个自适应哈希索引,这个东西是mysql自己内部优化的,我们无法操作这个

在使用B+树的时候,每个数据都需要经过多次的IO进行查询,如果某些数据需要经常性的访问到,那这些数据就会被放到innodb的buffer pool中
哎,放到buffer pool中,放到buffer pool中我们下次直接取就可以了,关自适应哈希索引什么事情啊
我们知道数据的读取都是以页page为单位的,所以buffer pool中缓存数据的时候也是存储的数据所在的页,并不是只缓存相应的数据,那这部分缓存的数据也是缓存的页,那每次查询的时候还是得从缓存中通过B+树中查询,所以这样也是可以优化的
经常使用的数据就直接把相应的数据的位置放到自适应哈希索引中即可了,下一次再查询的时候就不需要再去缓存中通过B+数的结构把数据给挖出来
求赞
Captain希望有一天能够靠写作养活自己,现在还在磨练,这个时间可能会持续很久,但是,请看我漂亮的坚持
感谢大家能够做我最初的读者和传播者,请大家相信,只要你给我一份爱,我终究会还你们一页情的。
Captain会持续更新技术文章,和生活中的暴躁文章,欢迎大家关注【Java贼船】,成为船长的学习小伙伴,和船长一起乘千里风、破万里浪
哦对了,后续所有的文章都会更新到这里
https://github.com/DayuMM2021/Java
