
MySQL 去重的 3 种方法,还有谁不会?!

阅读本文大概需要 2.8 分钟。
来自:blog.csdn.net/xienan_ds_zj/article/details/103869048
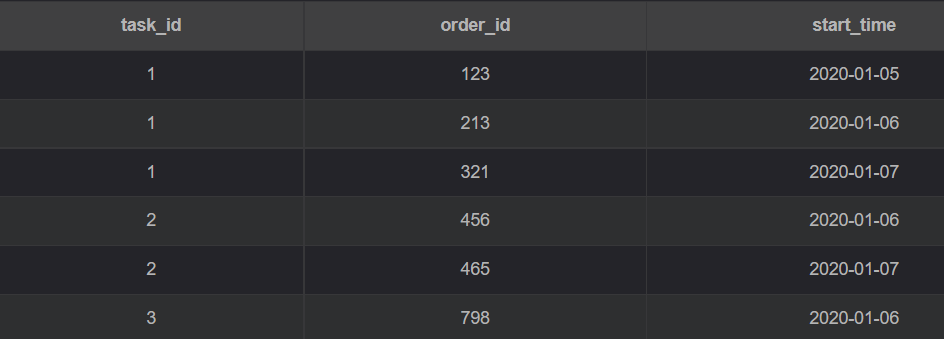
task_id: 任务id;
order_id: 订单id;
start_time: 开始时间
注意:一个任务对应多条订单
-- 列出 task_id 的所有唯一值(去重后的记录)-- select distinct task_id-- from Task;-- 任务总数select count(distinct task_id) task_numfrom Task;
distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重。比如distinct后面有两个字段,那么 1,1 和 1,2 这两条记录不是重复值 。
-- 列出 task_id 的所有唯一值(去重后的记录,null也是值)-- select task_id-- from Task-- group by task_id;-- 任务总数select count(task_id) task_numfrom (select task_idfrom Taskgroup by task_id) tmp;
-- 在支持窗口函数的 sql 中使用select count(case when rn=1 then task_id else null end) task_numfrom (select task_id, row_number() over (partition by task_id order by start_time) rnfrom Task) tmp;
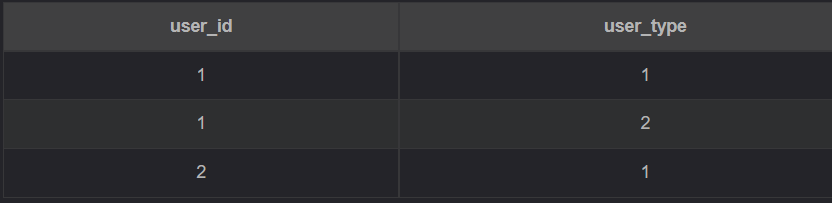
-- 下方的分号;用来分隔行select distinct user_idfrom Test; -- 返回 1; 2select distinct user_id, user_typefrom Test; -- 返回1, 1; 1, 2; 2, 1select user_idfrom Testgroup by user_id; -- 返回1; 2select user_id, user_typefrom Testgroup by user_id, user_type; -- 返回1, 1; 1, 2; 2, 1select user_id, user_typefrom Testgroup by user_id;-- Hive、Oracle等会报错,mysql可以这样写。-- 返回1, 1 或 1, 2 ; 2, 1(共两行)。只会对group by后面的字段去重,就是说最后返回的记录数等于上一段sql的记录数,即2条-- 没有放在group by 后面但是在select中放了的字段,只会返回一条记录(好像通常是第一条,应该是没有规律的)
推荐阅读:
内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取! 朕已阅 
评论