//(5)获取fromdir目录下的各文件信息,比如文件大小、文件名等. if (lstat(fromfile, &fst) < 0) ereport(ERROR, (errcode_for_file_access(), errmsg("could not stat file \"%s\": %m", fromfile)));
// fsync_fname()会忽略试图打开不可读文件或试图在不允许/不需要的系统上进行fsync目录的错误。 // 其他所有错误都是致命的。 intfsync_fname(constchar *fname, bool isdir) { int fd; int flags; int returncode;
// 开始文件数据复制。nbytes已经复制好的数据. flush_offset = 0; for (offset = 0;; offset += nbytes) { /* If we got a cancel signal during the copy of the file, quit */ CHECK_FOR_INTERRUPTS(); /* * 我们稍后会对这些文件进行fsync,但是在复制过程中,要经常刷新它们,以避免在缓存中产生垃圾信息, * 并希望在fsync到来之前让内核开始写这些文件。 */ if (offset - flush_offset >= FLUSH_DISTANCE) { ////// 缓冲指定大小的内核缓冲区数据 pg_flush_data(dstfd, flush_offset, offset - flush_offset); flush_offset = offset; }
pgstat_report_wait_start(WAIT_EVENT_COPY_FILE_READ); nbytes = read(srcfd, buffer, COPY_BUF_SIZE); pgstat_report_wait_end(); if (nbytes < 0) ereport(ERROR, (errcode_for_file_access(), errmsg("could not read file \"%s\": %m", fromfile))); if (nbytes == 0) break; errno = 0; pgstat_report_wait_start(WAIT_EVENT_COPY_FILE_WRITE); if ((int) write(dstfd, buffer, nbytes) != nbytes) { /* if write didn't set errno, assume problem is no disk space */ if (errno == 0) errno = ENOSPC; ereport(ERROR, (errcode_for_file_access(), errmsg("could not write to file \"%s\": %m", tofile))); } pgstat_report_wait_end(); }
if (offset > flush_offset) pg_flush_data(dstfd, flush_offset, offset - flush_offset);
// 关闭tofile文件句柄 if (CloseTransientFile(dstfd) != 0) ereport(ERROR, (errcode_for_file_access(), errmsg("could not close file \"%s\": %m", tofile))); //关闭fromfile文件句柄 if (CloseTransientFile(srcfd) != 0) ereport(ERROR, (errcode_for_file_access(), errmsg("could not close file \"%s\": %m", fromfile))); // 是否掉buffer内存缓冲区 pfree(buffer); }
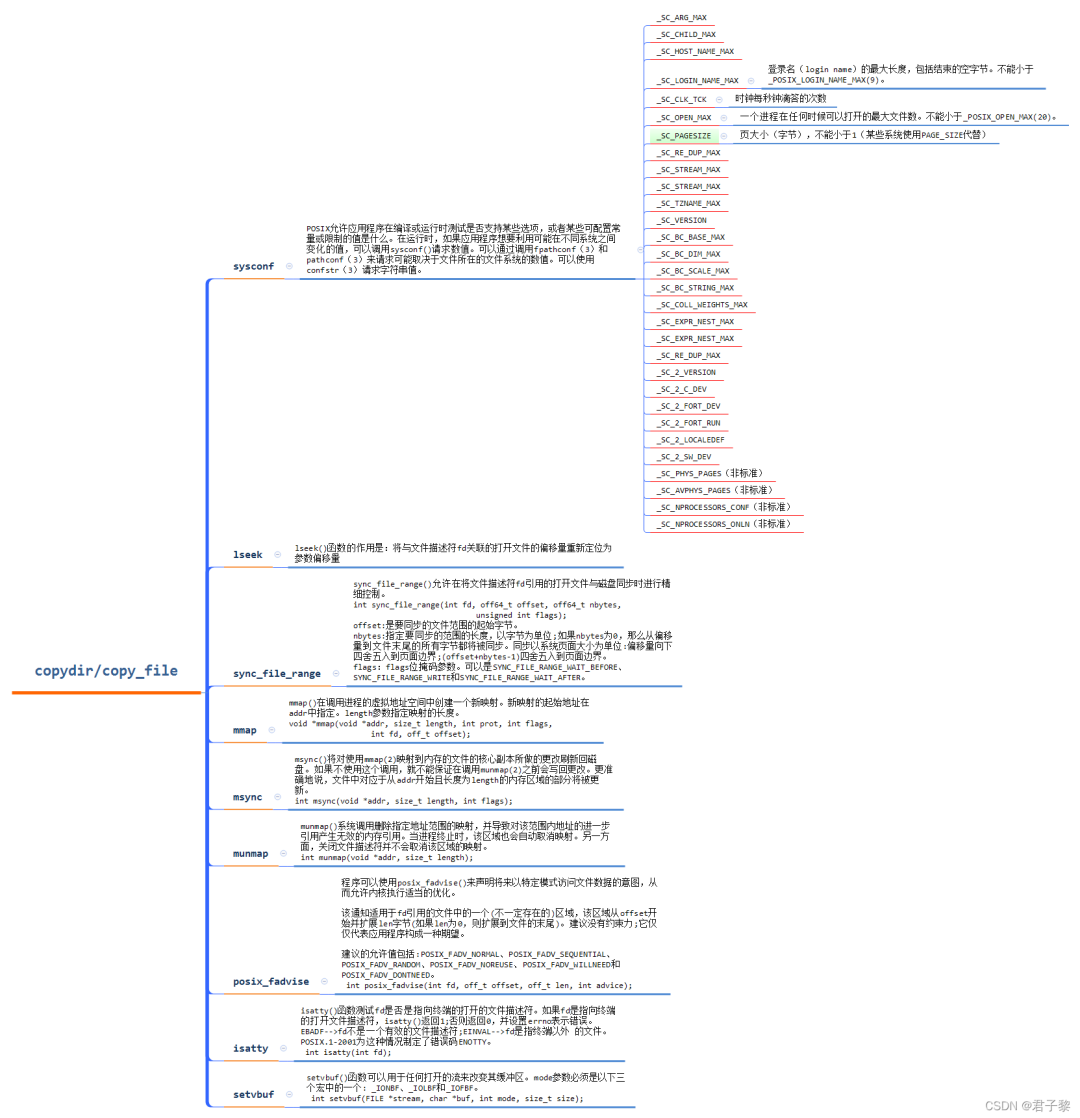
/* fetch pagesize only once */ if (pagesize == 0) pagesize = sysconf(_SC_PAGESIZE);
/* align length to pagesize, dropping any fractional page */ if (pagesize > 0) nbytes = (nbytes / pagesize) * pagesize;
/* fractional-page request is a no-op */ if (nbytes <= 0) return;
/* * mmap很可能会失败,尤其是在32位平台上,那里可能根本没有足够的地址空间。 * 如果是这样,就悄悄地进入下一个实现。 */ if (nbytes <= (off_t) SSIZE_MAX) p = mmap(NULL, nbytes, PROT_READ, MAP_SHARED, fd, offset); else p = MAP_FAILED;
if (p != MAP_FAILED) { int rc;
rc = msync(p, (size_t) nbytes, MS_ASYNC); if (rc != 0) { ereport(data_sync_elevel(WARNING), (errcode_for_file_access(), errmsg("could not flush dirty data: %m"))); /* NB: need to fall through to munmap()! */ }
rc = munmap(p, (size_t) nbytes); if (rc != 0) { /* FATAL error because mapping would remain */ ereport(FATAL, (errcode_for_file_access(), errmsg("could not munmap() while flushing data: %m"))); }
if (rc != 0) { /* don't error out, this is just a performance optimization */ ereport(WARNING, (errcode_for_file_access(), errmsg("could not flush dirty data: %m"))); }
return; } #endif }
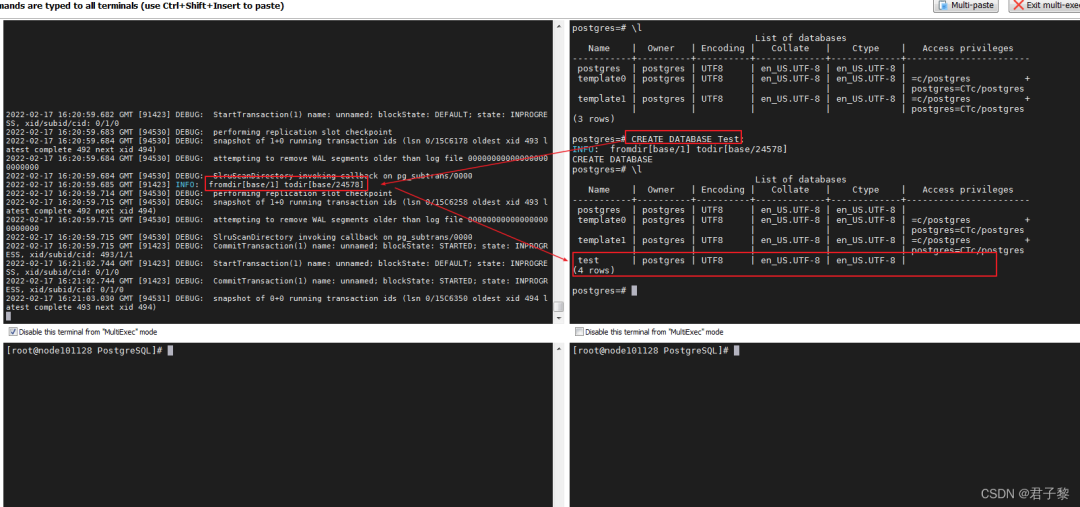
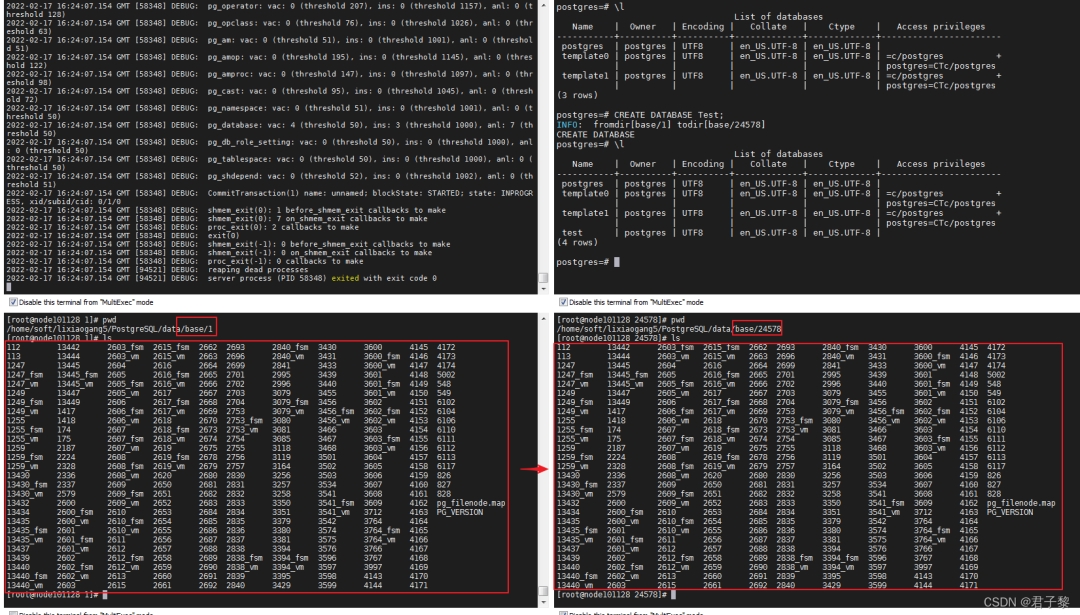
4. 哪些地方使用copydir()、copy_file() ?
在PostgreSQL数据库中,当“创建数据库(CREATE DATABASE 数据库名)、修改数据库属性(ALTER DATABASE SET TABLESPACE)和数据库资源管理器的例程(DATABASE resource manager's routines)”时候,都会使用到copydir()函数。