
MySQL:SELECT COUNT 小结

作者 | 翁智华
背景
今天团队在做线下代码评审的时候,发现同学们在代码中出现了 select count(1) 、 select count(*),和具体的select count(字段)的不同写法,本着分析的目的在会议室讨论了起来,那这几种写法究竟孰优孰劣呢,我们一起来看一下。
讨论归纳
先来看看MySQL官方对SELECT COUNT的定义:
传送门:https://dev.mysql.com/doc/refman/5.6/en/aggregate-functions.html#function_count
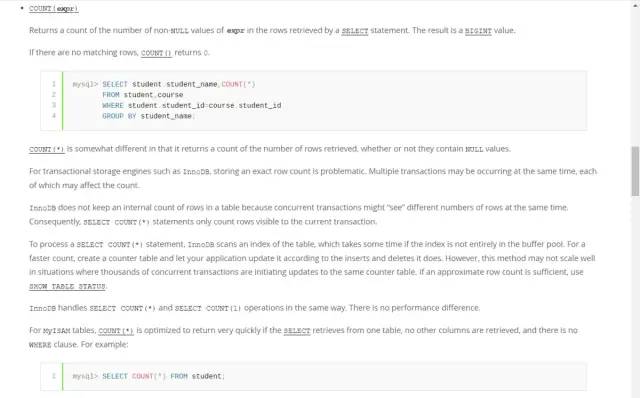
大概可以分下面这几个步骤讨论。
COUNT(expr)的分析
COUNT(expr)函数返回的值是由SELECT语句检索的行中expr表达式非null的计数值,一个BIGINT的值。如果没有匹配到数据,COUNT(expr)将返回0,通常有下面这三种用法:
1、COUNT(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
2、COUNT(*) 则不同,它执行时返回检索到的行数的计数,不管这些行是否包含null值,
3、COUNT(1)跟COUNT(*)类似,不将任何列是否null列入统计标准,仅用1代表代码行,所以在统计结果的时候,不会忽略列值为NULL的行。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
所以执行以下数据会出现这样的结果(这边是故意给component字段设置了几个null值):
select COUNT(*),COUNT(1),COUNT(component) from worklog;
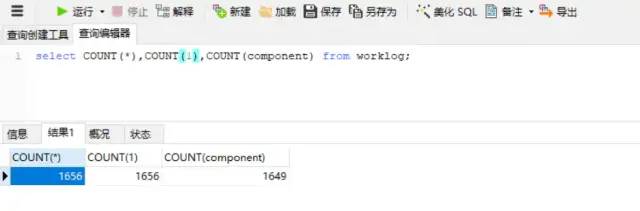
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(字段)只包括字段那一列,在统计结果的时候,会忽略列值为null的计数,即某个字段值为NULL时,不统计。
关于 COUNT(*) 和 COUNT(1)
先看看COUNT(*),MyISAM 引擎会把一个表的总行数记录了下来,所以在执行 COUNT(*)的时候会直接返回数量,执行效率很高。对于InnoDB这样的事务性存储引擎, 因为增加了版本控制(MVCC)的原因,同时有多个事务访问数据并且有更新操作的时候,每个事务需要维护自己的可见性,那么每个事务查询到的行数也是不同的,所以不能缓存具体的行数,他每次都需要count计算一下所有的行数。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
至于 COUNT(1) 和 COUNT(*)有什么区别呢,根据官网的内容(即上述截图倒数第二段),两种实现上其实一样:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
因为COUNT(*) 不care返回值是否为空都会将改行纳入计算,所以他count了所有行数,而 COUNT(1) 中的 1 ,则是遇到了行的时候为恒真表达式,所以 COUNT(*) 还是 COUNT(1) 都是对所有的结果集进行 count,他们本质上没有什么区别。姑且认为 COUNT(*)≈ COUNT(1)。
我们再来看看的COUNT(字段),他的查询就简单粗暴了,就是进行全表扫描,然后判断拿到的字段的值是不是为NULL,不为NULL则累加。
相比COUNT(*),COUNT(字段)多了一个步骤就是判断所查询的字段是否为NULL,所以他的性能要比COUNT(*)和COUNT(1)慢。
总结
综上,COUNT(1)和 COUNT(*)表示的是直接查询符合条件的数据库表的行数。而COUNT(字段)表示的是查询符合条件的列的值,并判断不为NULL的行数的累计,效率自然会低一点,
除了查询得到结果集有区别之外,相比COUNT(1) 和 COUNT(字段)来讲,COUNT(*)是SQL92定义的标准统计数的语法,是官方提供的标准方案,基于此,MySQL数据库对他进行过很多优化。
注:SQL92,是数据库的一个ANSI/ISO标准。它定义了一种语言(SQL)以及数据库的行为(事务、隔离级别等)。
下面是对一张具有3400W数据的表的统计过程,comid是整型,可以对比下执行效率差异:
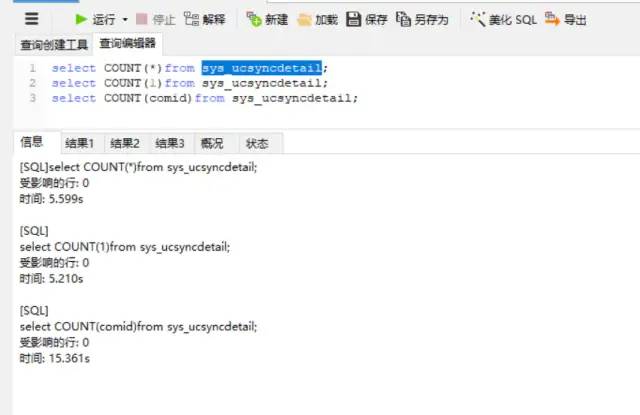
使用建议
根据总结的内容,从效率层面说,COUNT(*)≈ COUNT(1) > COUNT(字段),又因为 COUNT(*)是SQL92定义的标准统计数的语法,我们建议使用 COUNT(*)。
我们再来看看MySQL数据库做了哪些优化:以MySQL中比较常用的执行引擎InnoDB和MyISAM为例子。
1、MyISAM不支持事务,MyISAM中的锁是表级锁;
因为MyISAM的锁是表级锁,所以同一张表上面的操作是串行执行的,MyISAM把表的总行数单独记录下来,如果只是使用COUNT(*)对表进行查询的时候,可以直接返回这个记录的数值就可以了。
这样表中总行数记录即可提供给COUNT(*)查询使用,又因MyISAM数据库是表级锁,数据库行数不会被并行修改,所以行数是准确无误的。
如果您正在学习Spring Boot,推荐一个连载多年还在继续更新的免费教程:http://blog.didispace.com/spring-boot-learning-2x/
2、InnoDB支持事务,其中大部分操作都是行级锁。
这样就不能愉快的做这种缓存操作了,因为表的行数可能会被并发修改,缓存记录下来的总行数就不准确了。
在InnoDB中,使用COUNT(*)查询行数的时候,不需要进行扫表,只要获取记录行数而已。所以官方在针对InnoDB的 SELECT COUNT(*) FROM语句执行过程,会自动选择一个成本较低的索引进行的话,这样就可以大大节省时间。
InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值,非聚簇索引要比聚簇索引小很多,MySQL会优先选择最小的非聚簇索引来扫表,这样可以保证COUNT(*)的最优效率。
当查询语句中包含WHERE以及GROUP BY条件,会有一些其他的因素影响,所以要综合考虑。
判断数据在否,COUNT怎么用?
上面那种很获取COUNT数的场景多用于数据分页,数据统计的场景,有很多的情况则是直接判断数据是否存在,这种情况下,其实是不关心有多少数据。但是我们CoreReview的时候还是会很经常看到这种做法:
select COUNT(*) from test_ucsyncdetail where comid > 520;
int count = testDao.CountByComId(comId);
if(count>0){
//存在,则执行存在分支的代码
}else{
//不存在,则执行存在分支的代码
}
更好的写法应该是这样:
select 1 from test_ucsyncdetail where comid > 520 limit1;
Object tda = testDao.checkExit(comId);
if(tda !=null){
//存在,则执行存在分支的代码
}else{
//不存在,则执行存在分支的代码
}
规避了SQL使用COUNT表达式扫表的操作,而是改用SELECT 1 ... LIMIT 1,数据库查询时遇到一条就返回,不会再继续查找和执行,如果存在传输回一条结果为1的数据 ,否则为null,业务代码中直接判断是否非空即可
往期推荐
关注我回复「加群」,加入Spring技术交流群