
这些线程安全的坑,你在工作中踩了么?
我们知道多线程能并发的处理多个任务,有效地提高复杂应用程序的性能,在实际开发中扮演着十分重要的角色
但是使用多线程也带来了很多风险,并且由线程引起的问题往往在测试中难以发现,到了线上就会造成重大的故障和损失
下面我会结合几个实际案例,帮助大家在工作做规避这些问题
多线程问题
首先介绍下使用的多线程会有哪些问题
使用多线程的问题很大程度上源于多个线程对同一变量的操作权,以及不同线程之间执行顺序的不确定性
《Java并发编程实战》这本书中提到了三种多线程的问题:安全性问题、活跃性问题和性能问题
安全性问题
例如有一段很简单的扣库存功能操作,如下:
public int decrement(){
return --count;//count初始库存为10
}
在单线程环境下,这个方法能正确工作,但在多线程环境下,就会导致错误的结果
--count看上去是一个操作,但实际上它包含三步(读取-修改-写入):
读取count的值
将值减一
最后把计算结果赋值给count
如下图展示了一种错误的执行过程,当有两个线程1、2同时执行该方法时,它们读取到count的值都是10,最后返回结果都是9;意味着可能有两个人购买了商品,但库存却只减了1,这对于真实的生产环境是不可接受的

像上面例子这样由于不恰当的执行时序导致不正确结果的情况,是一种很常见的并发安全问题,被称为竞态条件
decrement()方法这个导致发生竞态条件的代码区被称为临界区
避免这种问题,需要保证读取-修改-写入这样复合操作的原子性
在Java中,有很多方式可以实现,比如使用synchronize内置锁或ReentrantLock显式锁的加锁机制、使用线程安全的原子类、以及采用CAS的方式等
活跃性问题
活跃性问题指的是,某个操作因为阻塞或循环,无法继续执行下去
最典型的有三种,分别为死锁、活锁和饥饿
死锁
最常见的活跃性问题是死锁
死锁是指多个线程之间相互等待获取对方的锁,又不会释放自己占有的锁,而导致阻塞使得这些线程无法运行下去就是死锁,它往往是不正确的使用加锁机制以及线程间执行顺序的不可预料性引起的

如何预防死锁
1.尽量保证加锁顺序是一样的
例如有A,B,C三把锁。
Thread 1的加锁顺序为A、B、C这样的。 Thread 2的加锁顺序为A、C,这样就不会死锁。
tryLock(long time, TimeUnit unit)方法,该方法可以按照固定时长等待锁,因此线程可以在获取锁超时以后,主动释放之前已经获得的所有的锁。可以避免死锁问题活锁
饥饿
举例说明
线程不安全类
案例1
ConcurrentModificationException的异常,也就是常说的fail-fast机制List<Integer> list = new ArrayList<>();
list.add(0);
list.add(1);
list.add(2); //list: [0,1,2]
System.out.println(list);
//线程t1遍历打印list
Thread t1 = new Thread(() -> {
for(int i : list){
System.out.println(i);
}
});
//线程t2向list添加元素
Thread t2 = new Thread(() -> {
for(int i = 3; i < 6; i++){
list.add(i);
}
});
t1.start();
t2.start();
 进到抛异常的ArrayList源码中,可以看到遍历ArrayList是通过内部实现的迭代器完成的
进到抛异常的ArrayList源码中,可以看到遍历ArrayList是通过内部实现的迭代器完成的checkForComodification()方法检查modCount和expectedModCount是否相等,若不相等则抛出ConcurrentModificationException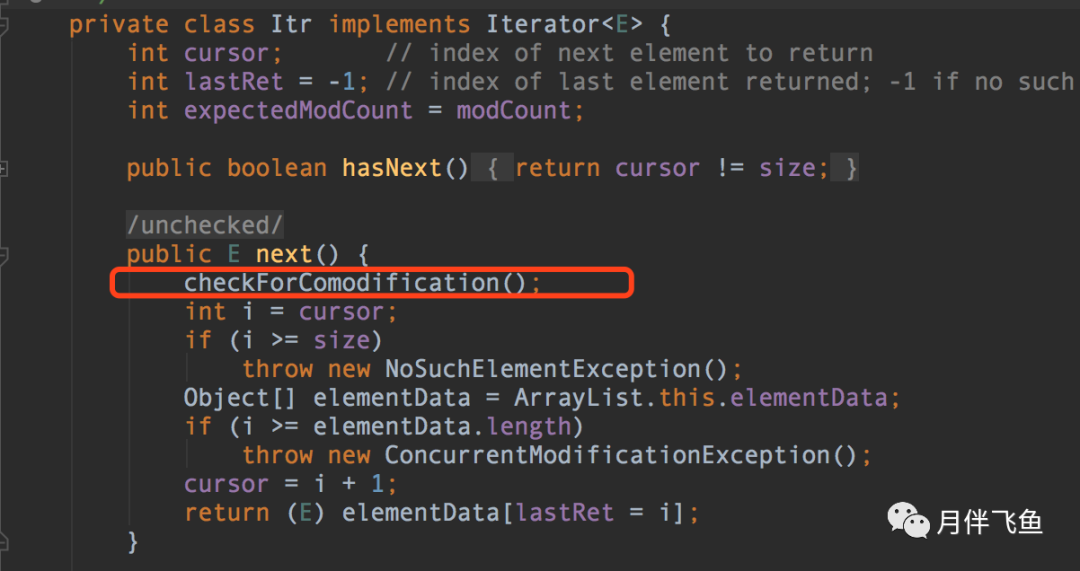
 modCount是ArrayList的属性,表示集合结构被修改的次数(列表长度发生变化的次数),每次调用add或remove等方法都会使modCount加1
modCount是ArrayList的属性,表示集合结构被修改的次数(列表长度发生变化的次数),每次调用add或remove等方法都会使modCount加1expectedModCount=modCount)
List<Integer> list = new ArrayList<>();
list.add(0);
list.add(1);
list.add(2);
System.out.println(list);
//线程t1遍历打印list
Thread t1 = new Thread(() -> {
synchronized (list){ //使用synchronized关键字
for(int i : list){
System.out.println(i);
}
}
});
//线程t2向list添加元素
Thread t2 = new Thread(() -> {
synchronized (list){
for(int i = 3; i < 6; i++){
list.add(i);
System.out.println(list);
}
}
});
t1.start();
t2.start();
案例2
public static final SimpleDateFormat SDF_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
//两个线程同时调用SimpleDateFormat.parse方法
Thread t1 = new Thread(() -> {
try {
Date date1 = SDF_FORMAT.parse("2019-12-09 17:04:32");
} catch (ParseException e) {
e.printStackTrace();
}
});
Thread t2 = new Thread(() -> {
try {
Date date2 = SDF_FORMAT.parse("2019-12-09 17:43:32");
} catch (ParseException e) {
e.printStackTrace();
}
});
t1.start();
t2.start();
}
 建议将SimpleDateFormat作为局部变量使用,或者配合ThreadLocal使用
建议将SimpleDateFormat作为局部变量使用,或者配合ThreadLocal使用//初始化
public static final ThreadLocal<SimpleDateFormat> SDF_FORMAT = new ThreadLocal<SimpleDateFormat>(){
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
//调用
Date date = SDF_FORMAT.get().parse(wedDate);
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime time = LocalDateTime.now();
System.out.println(formatter.format(time));
锁的正确释放
Lock lock = new ReentrantLock();
...
try{
lock.tryLock(timeout, TimeUnit.MILLISECONDS)
//业务逻辑
}
catch (Exception e){
//错误日志
//抛出异常或直接返回
}
finally {
//业务逻辑
lock.unlock();
}
...
正确使用线程池
案例1
public void request(List<Id> ids) {
for (int i = 0; i < ids.size(); i++) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
}}
案例2
Executors.newFixedThreadPool(int); //创建固定容量大小的线程池
Executors.newSingleThreadExecutor(); //创建容量为1的线程池
Executors.newCachedThreadPool(); //创建一个线程池,线程池容量大小为Integer.MAX_VALUE
Integer.MAX_VALUE=2147483647,对于真正的机器来说,可以被认为是无界队列newFixedThreadPool和newSingleThreadExecutor在运行的线程数超过corePoolSize时,后来的请求会都被放到阻塞队列中等待,因为阻塞队列设置的过大,后来请求不能快速失败而长时间阻塞,就可能造成请求端的线程池被打满,拖垮整个服务。
Integer.MAX_VALUE,阻塞队列使用的SynchronousQueue,SynchronousQueue不会保存等待执行的任务所以newCachedThreadPool是来了任务就创建线程运行,而maximumPoolSize相当于无限的设置,使得创建的线程数可能会将机器内存占满。
线程数建议
1.CPU密集型应用
corePoolSize=CPU核数+1个线程。JVM可运行的CPU核数可以通过Runtime.getRuntime().availableProcessors()查看。2.IO密集型应用
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️