
完全解读数据仓库质量管理规范

一、 背景
现在数据仓库层面的工作越来越多,开发人员也越来越多,如何保障数据准确性是一项非常重要的工作,,数据仓库的很多应用数据直接呈现给用户或者支撑企业分析决策的,容不得数据出现错误。随着开展的业务越来越多,数据模型越来也多,我们管控的越晚就越容易出问题。尽管有数据仓库建设规范,同样在数据模型命名,数据逻辑开发,每个人都可能不一样,而这些也容易导致数据模型准确性的问题。我们迫切需要制定一套数据的准确性验证流程,让大家都按规范流程来做,保障数据的准确性。
二、 数据指标管理
首先我们看下数据仓库的数据流转,要确认计算出的指标正确,就要保证数据源的准确和逻辑的准确。

所以开发前需要确认需求理解的准确性。根据“需求模板”完善所开发的需求,遇到提出的模糊定义,需要和业务人员确认指标口径的准确性。
需求模板主要包含业务分类、指标名称、是否新增、统计周期、指标维度、业务口径、技术口径、数据源表、需求提出人、需求提出日期、优先级等:

开发数据指标过程分为四部分:看、查、管、控。
1. 看
首先我们要对开发出的指标结果数据进行查看,是否有一些明显的异常,比如某个数据值不在正常范围内,如车速大于500KM/h,或者统计的总数过大,比如某城市人口1亿人等。
2. 查
查,分为测试验证和上线审核。
测试核对方法如下:
总量核对,核对上下两步的数据总条数,没有过滤条件的话应该是一致的。
多维度统计,复杂的多维度指标拆分成单维度SQL统计,对每个指标分别进行核查。
多表关联统计,拆分成中间表进行核对每一步骤的指标。
明细到指标统计,比如随机找一台车的明细和最后统计的指标进行核对。
新老统计对比,比如有些指标是迁移或者之前业务手工制作,可以开发后的新指标同老指标进行对比。
测试需要有专门的数据测试人员进行测试,输出测试用例和测试报告。
上线审核方法如下:
需要对上线的SQL代码进行审核,主要从以下几个方面:
对查询表的where后面的条件、join关联字段、group by分组字段等重点检查逻辑,和需求理解结合审核。
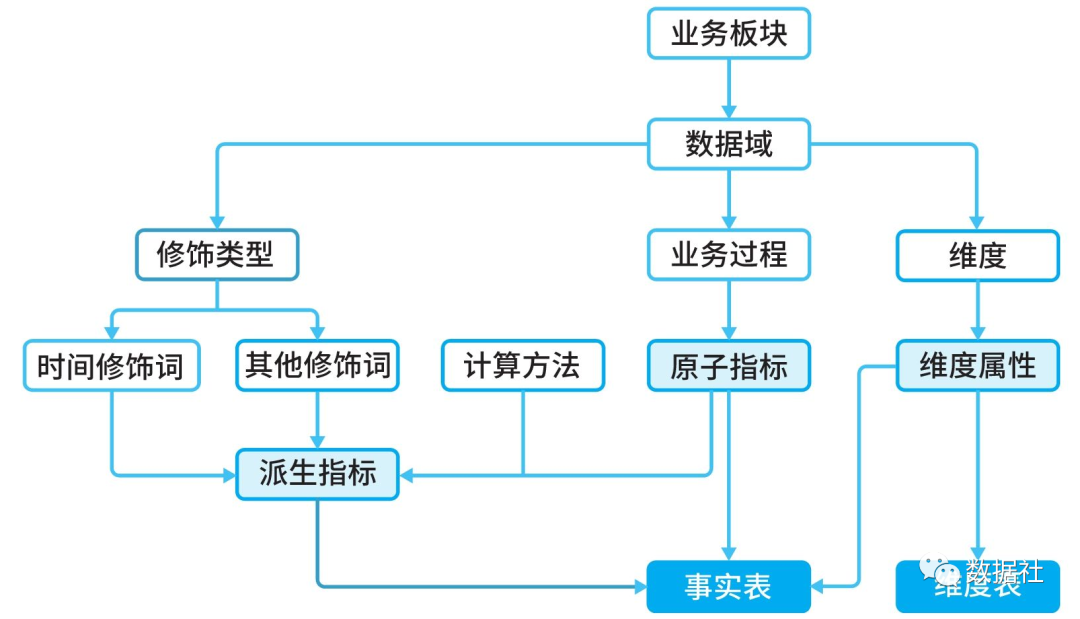
数据集命名、数据集字段命名、任务名称进行审核,是否按照数据仓库建设规范中的业务域、维度、原子指标、修饰类型、修饰词、时间周期、派生指标等标准进行命名。
代码注释审核,每一步处理需要有注释该步骤的作用,每个指标也要有注释,where条件等也要添加注释。
重要任务是否开启短信告警,任务启动时间等审核。
任务上线的位置是否符合上线标准,比如上线的数据层级与业务层级等。
上线审核需要审核人员按照以上步骤进行审核,对不合理的地方进行指正,审核人员和开发人员共同保障代码质量。
3. 管
开发过程中,大家需要遵循一些流程规则,以确保指标的定义,开发的准确性。
需求上线时候需要在知识库中完成所开发需求逻辑说明
复杂需求(比如项目指标),需要团队至少两人以上评审需求后开发。
提交上线申请的同事需要备注上需求逻辑说明。
审核上线人员为“轮值”,审核上线人员需要review开发人员的代码,需要和开发人员共同承担代码质量
4. 控
指标开发完成后,需要对指标的波动情况进行监控,发现波动较大的进行核查,指标波动范围需要具体业务具体制定,需要业务人员协助确认。常用的数据质量监控方法如下:
1、校验每天的记录数
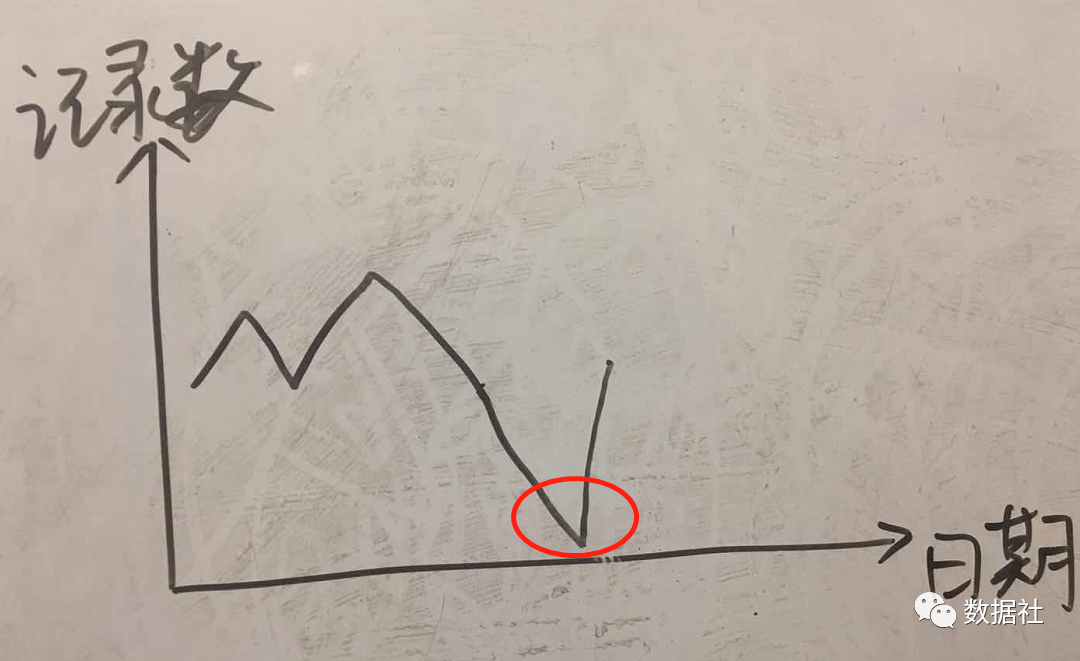
分析师遇到的最常见数据异常是其报告的输出突然降至0。
我们通常会发现最后的罪魁祸首是当天没有将新记录添加到相应的表中。
一种简单的检查方法是确保每天一个表中的新记录数>0。
2、NULL和0值校验
分析师常遇到的第二个问题是NULL或0值。我们要保证每天增量数据中的NULL或0值不能超过新增数据的99%。要检查这一点,只需将一个循环脚本设置为每天用NULL或0计数一个表中的新记录数。如果看到记录数急剧增加,则可能存在转换错误或源业务系统就存在异常。
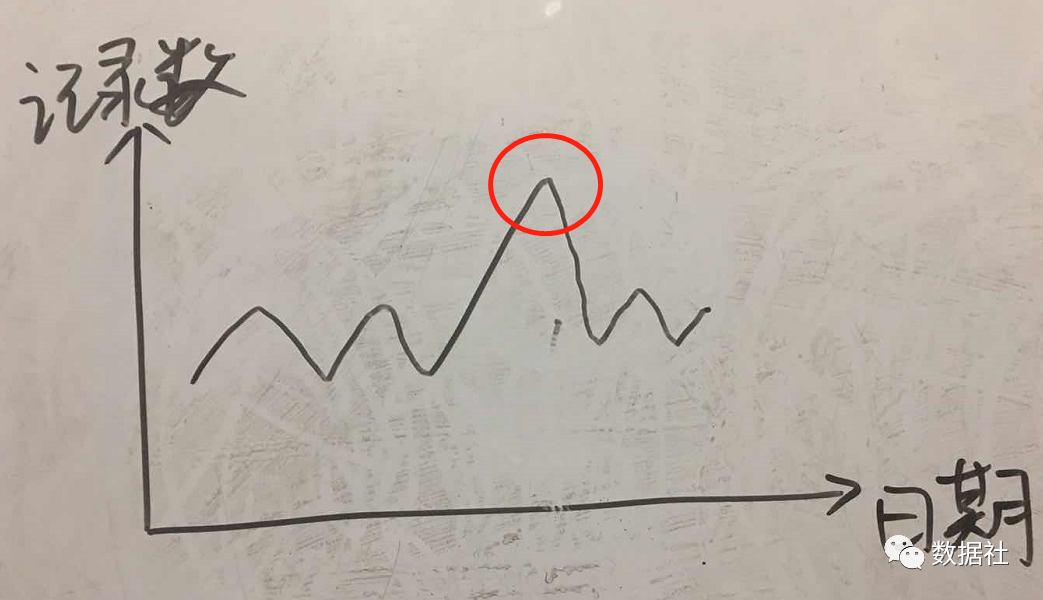
3、每天新增的记录数波动范围
某一天你发现数据量出现大幅增长或下降,而规则1和2都已校验通过。这种波动可能是正常的,比如电商行业某天的大促活动,或者社交软件的营销活动。但是也可能这就是异常的,是因为从源系统抽取了重复的记录。所以针对此种情况,我们也要制定数据质量规则,检查这些波动何时发生,并主动进行诊断。比如自动执行的一个简单的SQL过程,每天检查COUNT个新记录是否在7天跟踪平均值的误差范围内。阈值和误差范围可能因公司和产品而异,经验值一般是加减25%。当然,你可也可以直接和前一天的数据对比,增量不超过前一天的1倍。
4、重复记录数据校验
不管是电商系统或者是社交系统或者是物联网设备上报的数据,正常情况下都不会出现两条完全一样的记录(包括ID,时间,值都一样)。笔者曾遇到一个终端上报的两条数据完全一样的场景,导致我在做时间分段时候,划分不正确。所以,对数据值唯一性校验是有必要的。

5、数据时间校验
一般我们业务系统的数据都是带有时间戳的,这个时间戳肯定比当前的时间要小。但是由于采集数据设备异常(业务系统异常),我们会碰到“未来时间”的数据,那如果我们以时间作为分区,后期可能就会出现异常的分析结果。当然,如果你的公司业务是跨国的,你需要考虑时差因素。

三、总结
通过以上内容,我们对如何管控数据仓库的数据质量管理方法和流程有了初步的认识。对于不同的业务或者公司,还是需要团队小伙伴或者业务侧一起制定解决方案,不断完善监控体系,只有这样才能保证我们的业务分析结果是准确的,才能指导公司做出正确的决策。
更多阅读
特别推荐

点击下方阅读原文加入社区会员