
真香!我挖到了4款超级强大的 Python 数据科学工具!
Pandas 在数据科学和机器学习领域的成功和优势归功于功能和方法的多样性和灵活性。
在这篇文章中,我们将介绍四个 pandas 函数,这些函数虽然使用频率较低,但却非常实用、强大。
让我们从导入 NumPy 和 Pandas 开始。
import numpy as np
import pandas as pd
1、factorize
它提供了一种对分类变量进行编码的简单方法,这是大多数机器学习技术中必需的任务。
下面是来自客户流失数据集的分类变量。
df = pd.read_csv('/content/Churn_Modelling.csv')
df['Geography'].value_counts()
France 5014
Germany 2509
Spain 2477
Name: Geography, dtype: int64
我们只需一行代码就可以对类别(即转换为数字)进行类别转换。
df['Geography'], unique_values = pd.factorize(df['Geography'])
因子函数返回转换的值以及类别的索引
df['Geography'].value_counts()
0 5014
2 2509
1 2477
Name: Geography, dtype: int64
unique_values
Index(['France', 'Spain', 'Germany'], dtype='object')
如果原始数据中缺少值,可以指定要用于这些值的值。默认值为 -1。
A = ['a','b','a','c','b', np.nan]
A, unique_values = pd.factorize(A)
array([ 0, 1, 0, 2, 1, -1])
A = ['a','b','a','c','b', np.nan]
A, unique_values = pd.factorize(A, na_sentinel=99)
array([ 0, 1, 0, 2, 1, 99])
2、Categorical
Categorical 可用于创建分类变量。
A = pd.Categorical(['a','c','b','a','c'])
我们只能从现有类别之一分配新值。否则,我们将得到一个值错误。
A[0] = 'd'
ValueError: Cannot setitem on a Categorical with a new category, set the categories first
3、Interval
它返回表示 Interval 的不可变对象。当我们处理日期时间数据时,Interval 会派上用场。我们可以很容易地检查日期是否以指定的间隔。
date_iv = pd.Interval(left = pd.Timestamp('2019-10-02'), right = pd.Timestamp('2019-11-08'))
date = pd.Timestamp('2019-10-10')
date in date_iv
True
4、Wide_to_long
Wide_to_long将宽数据框转换为长数据。它提供了一种灵活且对用户更友好的方式。
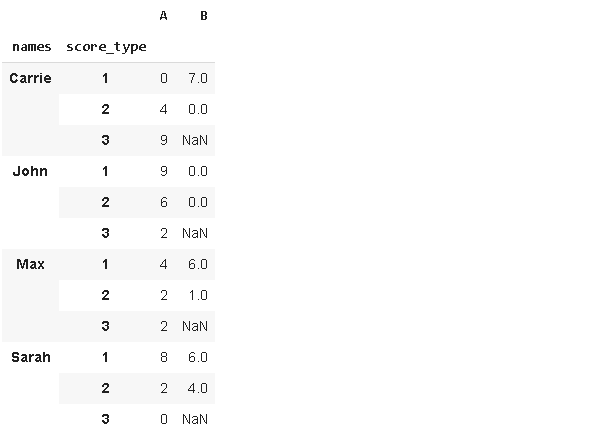
请看以下示例数据。 我们希望重塑此数据帧
我们希望重塑此数据帧
pd.wide_to_long(df, stubnames=['A','B'], i='names', j='score_type')
 返回的数据帧具有多级索引,我们可以通过应用该函数将其转换为reset_index索引。
返回的数据帧具有多级索引,我们可以通过应用该函数将其转换为reset_index索引。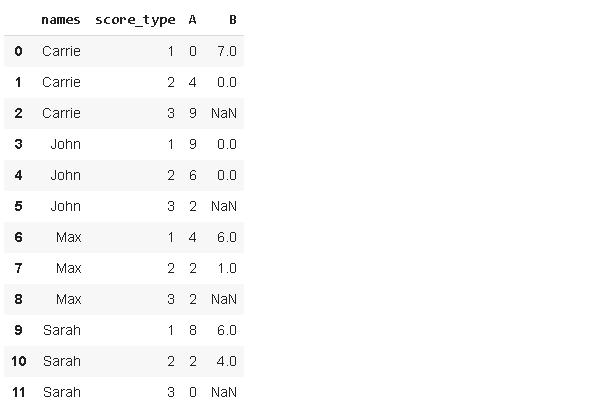

另外,再送大家一份《Python数据科学手册》
以大数据、云计算、物联网、人工智能等新技术所推动的数字化转型正迅速的改变着我们所处的时代,各大互联网公司都积累了大量的用户数据,比如购物、社交、出行等。充分挖掘数据价值,就是需要不断的和数据打交道。
如果你对数据分析、数据挖掘、数据化运营感兴趣,却又无从下手,那么我来给你推荐一本不错的书籍--《Python数据科学手册》。

领取方式:
长按扫码,发消息 [数据分析]
评论