
如何评估测试用例有效性
“
每一个测试人都经历过测试用例评审,但是如何评估测试用例的有效性呢? 是不是我按照黑盒测试用例的设计原则来设计,这个测试用例就是一个有效的测试用例呢?(黑盒测试用例设计方法有:等价类划分法、边界值分析法、错误推测法、因果图法、判定表驱动法、正交试验设计法、功能图法、场景图法)。
我想答案是否定的,测试用例的有效性,更像是个玄学,长期以来,并没有一个相对科学的办法来验证。
下面这篇文章是原蚂蚁金服-义理大佬的一些实践,给我非常大启发,分享给大家。
”
01
—
为什么要评估测试用例有效性
想想你的团队有没有碰见过这样的问题:
1. 这么多的Case,花了大量时间和资源去运行,真的能发现Bug吗?
2. CI做到90%的行覆盖率了,能发现问题吗?
3. 测试用例越来越多,删除一些,会不会就发现不了问题了?
4. 怎么找出那些为了覆盖而覆盖,但是发现不了真正问题的测试用例?
想想上面的问题,再扪心自问:测试用例的有效性要不要评估?
测试用例有效性
要评估测试用例的有效性,首先要看,什么样的测试用例是有效的?
测试用例有效性
那么,测试用例具备不具备有效性,主要看以下指标:
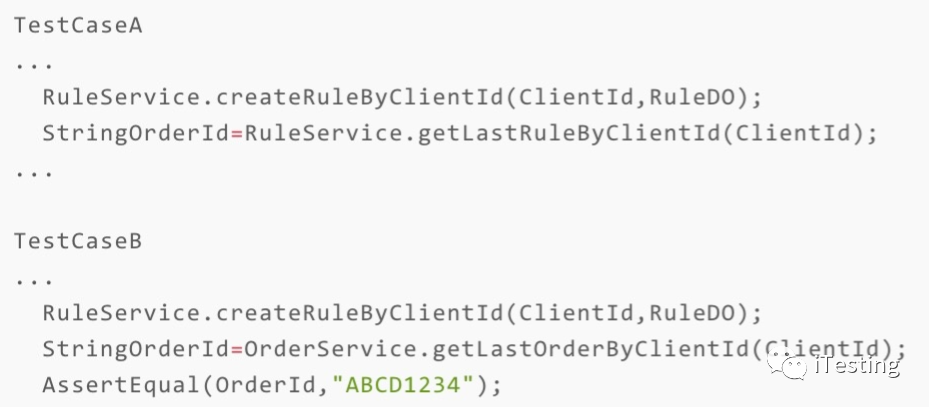
这个测试用例不仅能够“触发被测代码的各种分支”,还能够做好结果校验。
当业务代码出现问题的时候,测试用例可以发现这个问题,我们就认为这一组测试用例是有效的。
当业务代码出现问题的时候,测试用例没能发现这个问题,我们就认为这一组测试用例是无效的。
由此引出测试用例有效性的理论建模:
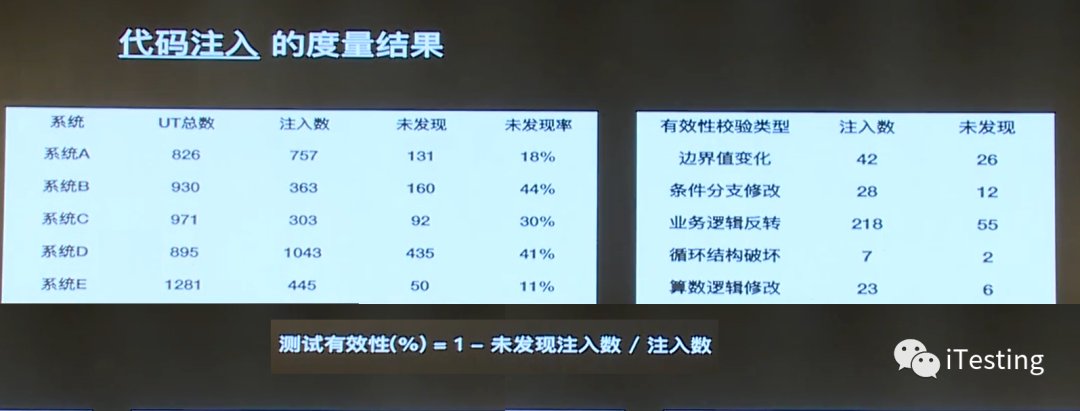
测试有效性 = 被发现的问题数 / 出现问题的总数。
02
—
测试用例有效性评估度量方法
从运行时、非运行时, 正向和逆向这个维度, 我们可以得出以下的度量方式:

正向的链路扫描和静态扫描都比较常见,这里重点介绍下逆向的方式:
代码注入:
属于非运行时度量方式。通过向代码注入变异,来看测试用例是否能够发现问题。
内存注入:
属于运行时度量方式。也叫“”故障注入“”, 指在运行时进行操作和修改,来检查你的测试用例是否能反映出这个问题。 常见的有对API调用的返回结果进行修改,如果更改后,测试用例执行报错,则说明测试用例有效,反之说明无效。
这里重点讲下代码注入。
代码注入的原理是变异测试(mutation testing)。

变异测试的例子
我们用了一组测试用例(3个),去测试一个判断分支。
而为了证明这一组测试用例的有效性,我们向业务代码中注入变异。我们把b<100的条件改成了b<=100。
我们认为:一组Success的测试用例,在其被测对象发生变化后(注入变异后),应该至少有一个失败。如果这组测试用例仍然全部Success,则这组测试用例的有效性不足。
通过变异测试的方式:让注入变异后的业务代码作为“测试用例”,来测试“测试代码”。
那么可选的变异有哪些呢?
1. 线上的故障总结。
根据线上出现过的故障,总结其故障模式,然后将归纳后的符合故障模式的代码变异注入,以期望未来线上不会有同样问题出现。比如,代码中把空判断删除、更改日期格式(冬令时改成夏令时)、把相似函数混淆(例如把函数encodeing改成decoding)甚至发大程序中的数据范围(把金额从放大10倍或100倍)来引发错误。
2. 解决未知的问题。
上面的部分是已知的问题,那么还有很多我不知道有哪些问题的问题,这些问题怎么解决呢?
对于此类问题,可以寻找其通用解。
例如基于Java语言,把它的运算符,代码结构这一类的约定俗成的编码规范进行修改,例如把+改成-, 把=改成!=。
在此基础上,可以实现多种规则,主动的注入下面这些变异:

上面的介绍是理论,每个团队都可以看,可以学。下面的是蚂蚁金服的实践方案,大家可以按需参考
03
—
代码注入工程化方案
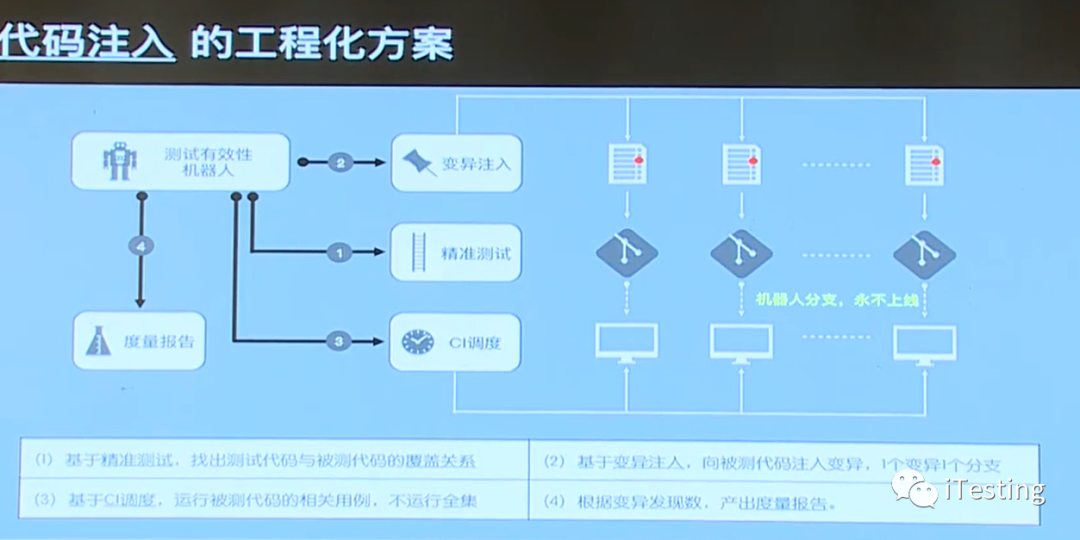
为了全自动的进行测试有效性评估,我们做了一个变异机器人,其主要运作是:
往被测代码中写入一个BUG(即:变异)
执行测试
把测试结果和无变异时的测试结果做比对,判断是否有新的用例失败
重复1-3若干次,每次注入一个不同的Bug
统计该系统的“测试有效性”
变异机器人的优点:
防错上线:变异是单独拉代码分支,且该代码分支永远不会上线,不影响生产。
全自动:只需要给出系统代码的git地址,即可进行评估,得到改进报告。
高效:数小时即可完成一个系统的测试有效性评估。
扩展性:该模式可以支持JAVA以及JAVA以外的多种语系。
适用性:该方法不仅适用于单元测试,还适用于其他自动化测试,例如接口测试、功能测试、集成测试。
变异机器人的使用门槛:
测试成功率:只会选择通过率100%的测试用例,所对应的业务代码做变异注入。
测试覆盖率:只会注入被测试代码覆盖的业务代码,测试覆盖率越高,评估越准确。
检查的结果如下:
04
—
持续优化
在执行的过程中,会碰见如下的问题:

那么还有什么方式可以持续优化呢?
<分钟级的系统评估效率>
为了保证评估的准确性,100个变异将会执行全量用例100遍,每次执行时间长是一大痛点。
高配版变异机器人给出的解法:
并行注入:基于代码覆盖率,识别UT之间的代码覆盖依赖关系,将独立的变异合并到一次自动化测试中。
热部署:基于字节码做更新,减少变异和部署的过程。
精准测试:基于UT代码覆盖信息,只运行和本次变异相关的UT(该方法不仅适用于UT,还适用于其他自动化测试,例如接口测试、功能测试、集成测试)
<学习型注入经验库>
为了避免“杀虫剂”效应,注入规则需要不断的完善。
高配版变异机器人给出的解法:故障学习,基于故障学习算法,不断学习历史的代码BUG,并转化为注入经验。可学习型经验库目前覆盖蚂蚁金服的代码库,明年会覆盖开源社区。
<兼容不稳定环境>
集成测试环境会存在一定的不稳定,难以判断用例失败是因为“发现了变异”还是“环境出了问题”,导致测试有效性评估存在误差。
高配版变异机器人给出的解法:
高频跑:同样的变异跑10次,对多次结果进行统计分析,减少环境问题引起的偶发性问题。
环境问题自动定位:接入附属的日志服务,它会基于用例日志/系统错误日志构建的异常场景,自动学习“因环境问题导致的用例失败”,准确区分出用例是否发现变异。
05
—
最终我们要实现这样的目标:
测试从 代码都能跑-->代码都被测试到了-->代码都测试好了。

最后放一个测试度量三板斧:

如果大家对本演讲的原视频感兴趣,可以通过此观看:
https://www.itdks.com/Course/detail?id=117569