
浅谈Elasticsearch数据库的重构与取证

在一起大型侵公类的案件中,我们发现海量的数据被存储在一个名为Elasticsearch的数据库中。所谓Elasticsearch(以下简称ES),实际上是一个高度可扩展开源的全文搜索引擎。它搜索功能非常强大,几乎可以做到实时搜索,因此也常被用来作为搜索引擎,为复杂搜索功能的需求提供解决方案。
ES也可以看作是一个分布式非关系型数据库,数据格式和MongoDB相似。
接下来我们将从ES数据库的启动、连接、管理、备份、导出等流程还原一个ES7数据服务器的基本重构和查询流程。
我们先来了解es7配置信息,用来获取服务器中es7数据库相关信息,也可用于重新搭建es7数据库。
Elasticsearch通常有三个主要的配置文件:
l elasticsearch.yml:用于配置Elasticsearch
l jvm.options:用于配置Elasticsearch JVM设置
l log4j2.properties:用于配置Elasticsearch日志

参数中比较重要的是host和port参数,用来告诉访问者通过什么ip和端口来访问数据库服务。path.data也很重要,直接记录了数据文件路径,物理备份可以直接拷贝该路径下文件。

JVM设置主要用来配置内存和调优的,重构es7数据库需要关注内存参数,内存配置不要高于本机内存。
以“-”开头的行是不依赖JVM版本的选项,例如,-Xmx2g
以数值“:-”开头的行是依赖于JVM版本的选项,例如,8:-Xmx2g
-Xms4g #JVM最初内存配置4g-Xmx4g #JVM最大内存配置4g
useradd elas #新建一个普通用户chown -R elas:elas elasticsearch-7.9.2/ #将es7相关文件夹所有权限赋给该用户su elas #切换用户后再启动
2、启动es7。
./elasticsearch -d3、查看运行状态正常。
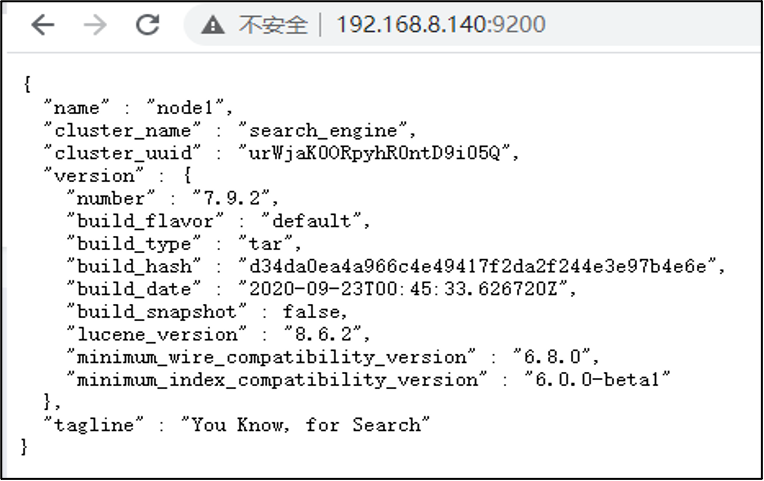
netstat -anpt | grep 9200 #查看对应端口是否开启
curl http://192.168.8.140:9200 #接口测试正常
4、查看浏览器。
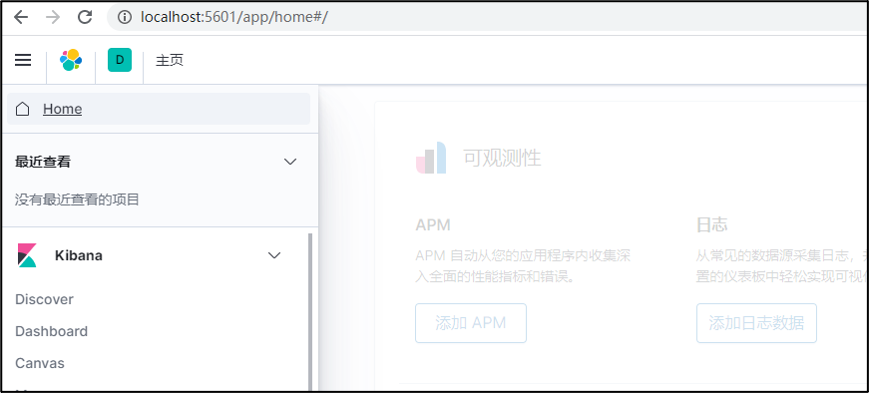
Kibana是es7的可视化管理工具,用来可视化管理数据库,查询分析数据,功能十分强大。
windows版本Kibana ,要求和elasticsearch版本号一致,下载地址:
https://www.elastic.co/cn/downloads/past-releases#kibana
运行步骤:
(1)下载并解压Kibana;
(2)在编辑器中打开 config/kibana.yml;
(3)设置elasticsearch.hosts为指向您的 Elasticsearch 实例;

(4)语言设置;
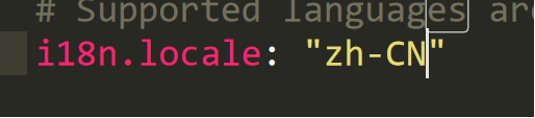
(5) 运行bin/kibana(或bin\kibana.bat在 Windows 上);
(6) 将浏览器指向“http://localhost:5601”;
(7)在索引管理中查看对应的索引(数据库名)和它包含的文档(数据条数)个数。
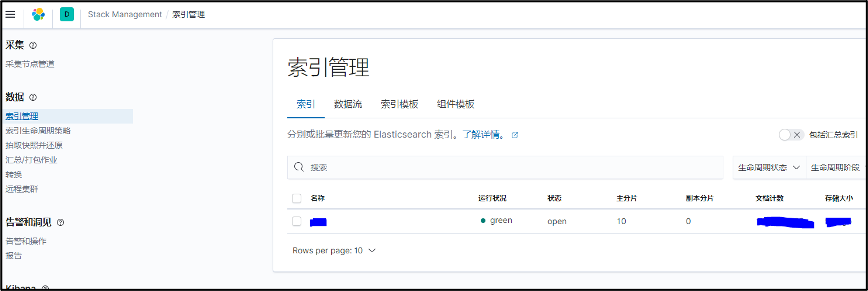
和传统意义上的数据库相比,es7数据库对库和数据有对应概念。
Index索引概念:含有相同属性的文档集合,类似于数据库的概念。一个index包含很多document,一个index就代表了一类类似的或者相同的document。
document文档概念:es中的最小数据单元,一个document可以是一条数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
创建索引中定义一个已有索引:
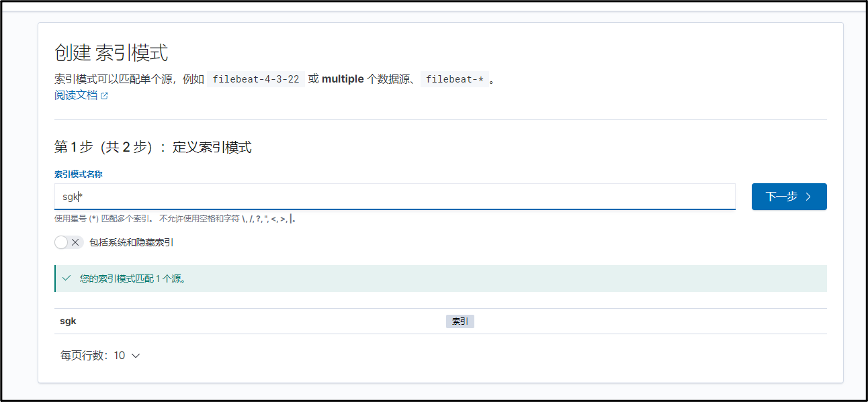
创建成功后在Discover中可以查看数据:

进行数据筛选:

导出CSV功能:共享菜单中可以将筛选命中的结果保存为csv(数据量过大时无法通过该方式导出csv)。

(不同版本接口不太一样,具体接口参考官方文档)
GET http://192.168.8.140:9200/sgk/_search #查询sgk索引的所有数据,默认返回前10条GET http://192.168.8.140:9200/sgk/_search?q=username:张三#&q=mobile:13000000000&size=10&from=10 #查询sgk索引的字段username为张伟且mobile为13000000000的记录,返回第11到20条数据(分页查询有限制,一般size+from为10000条,数据量大无法用分页查找)案件中我们需要将在线的数据备份,推荐工具为elasticdump,数据备份为json。
1、通过npm安装elasticdump命令。
npm install elasticdump2、导出 index 的所有数据到 .json 文件。
elasticdump \--input=http://production.es.com:9200/my_index \--output=/data/my_index.json \--type=data
3、导入还原jsons数据。
elasticdump \--input=./my_index.json \--output=http://es.com:9200 \--type=data
在使用场景中如遇到数据量巨大的情况,分页查询或者Kibana的导出csv功能都有大小限制。
这种情况,Scroll滚动查询是最优化选择。
使用Scroll滚动查询:search请求返回一个单一的结果“页”,而scroll API可以被用来检索大量的结果(甚至所有的结果),就像在传统数据库中使用的游标 cursor。滚动并不是为了实时的用户响应,而是为了处理大量的数据。
*通过python导出es7数据为csv(使用Scroll滚动查询,针对数据量巨大的情况,可以控制导出的字段和结果数)

各位看官如果想了解服务器固定、仿真等产品详情,或者有任何建议和疑问,可公众号留言或拨打服务热线400-800 3721咨询。