
Facebook全球6小时宕机原因已查明:一条指令所致,内部工程师所为
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
来源丨量子位(ID:QbitAI)
博雯 发自 凹非寺
Facebook全球宕机6小时的原因,是公司内部工程师的一条错误指令。
最近,Facebook官方针对这次大规模宕机的原因做了回应。

这一新闻已经出现在了微博热榜。

而在回复中,官方也(针对各种神奇的假说)强调:
没有黑客恶意攻击行为,用户的数据也没有受到损害。

在第二天,Facebook又发了另一则声明,详细地说明了这次宕机的技术细节。
那么这场Facebook有史以来持续时间最长,规模最大,造成公司股价蒸发百亿的宕机到底是因为什么?
一起来看看。
日常维护切断网络
一切都开始于日常维护中的一条错误指令。
也就是Facebook engineering平台上的声明中所提到的“配置变化”:
协调数据中心之间网络流量的主干路由器的配置变化导致了通信中断,进而影响了数据中心的的通信方式,最后导致了服务中断。

在日常维护网络基础设施时,工程师经常需要离线维护部分主干网,比如修理一条光纤线路,增加更多容量,或者更新路由器本身的软件。
而上面提到的“配置变化”,就是日常维护工作中主要用于检测Facebook主干网络的可用性的一条命令。
当然肯定有应对这种命令的保护措施,但不巧审计工具(audit tool)中出了个bug……

于是,这个“配置变化”就撒着欢儿,啪一下把Facebook主干网络的所有连接都给切断了。
这一断,应用程序对数据的刷新搜索,上传下载等请求就无法从用户设备传到最近的数据中心了。
而这些数据中心不仅有容纳了数百万台存储数据机器,用于支撑平台运行的大型建筑,还有将主干网络连接到更广泛的互联网和具体应用平台的较小设施。
嗯,差不多就是这样的严重性……
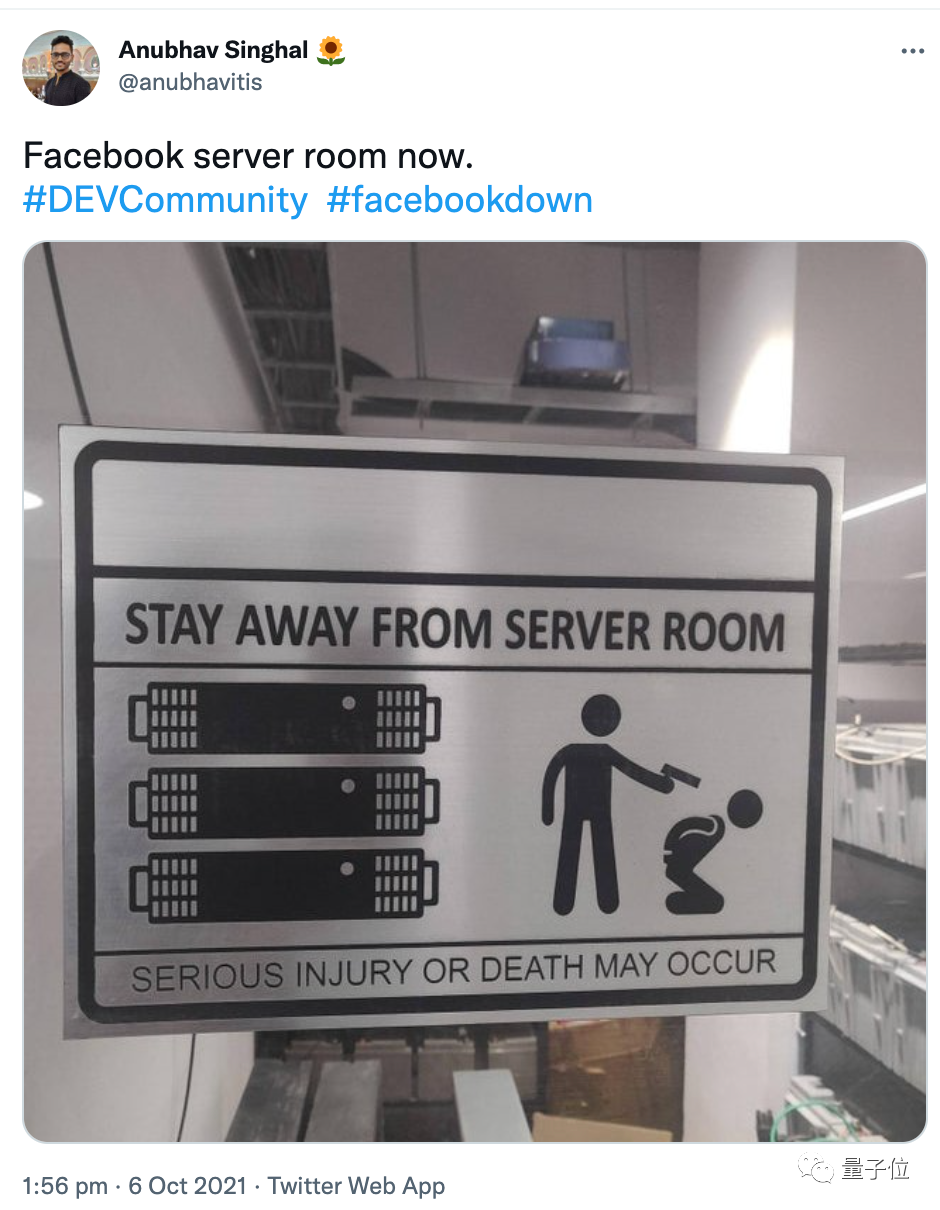
这还没完。
上述数据中心里的小型设施还有一个工作,那就是响应DNS查询。
DNS是互联网的地址簿,能够将浏览器中键入的简单网络名称转换为特定的服务器IP地址。
而这些地址又通过边界网关协议(BGP)向互联网其他地址进行广播,类似一个地图,提供通往各种目的地的线路。
当DNS服务器发现主干网络失去了与互联网的连接时,BGP的“广播”也随之停止。
相当于Facebook短暂地被从互联网这块地图上抹除了存在。
只有Facebook受伤的世界完成了
当然,在派遣工程师进入现场数据中心进行修复之后,网络服务也在10月4日下午4点左右逐渐恢复。

在官方回复的最后,他们也提到会通过这次的“演习”加强系统故障的测试、训练和整体恢复能力。
而纵观这次全球大宕机,不仅国外热度爆表,就连国内也上了热搜。

国内外的网友们弔图一堆,苦中作乐。
同为社交媒体的Twitter则高傲尽数显现。

甚至连Netflix都过来蹭了把热度,顺带了夹杂了新剧宣传私货:

而Facebook在这次事件中股价暴跌6%,扎克伯格个人财富一日蒸发逾60亿美元。
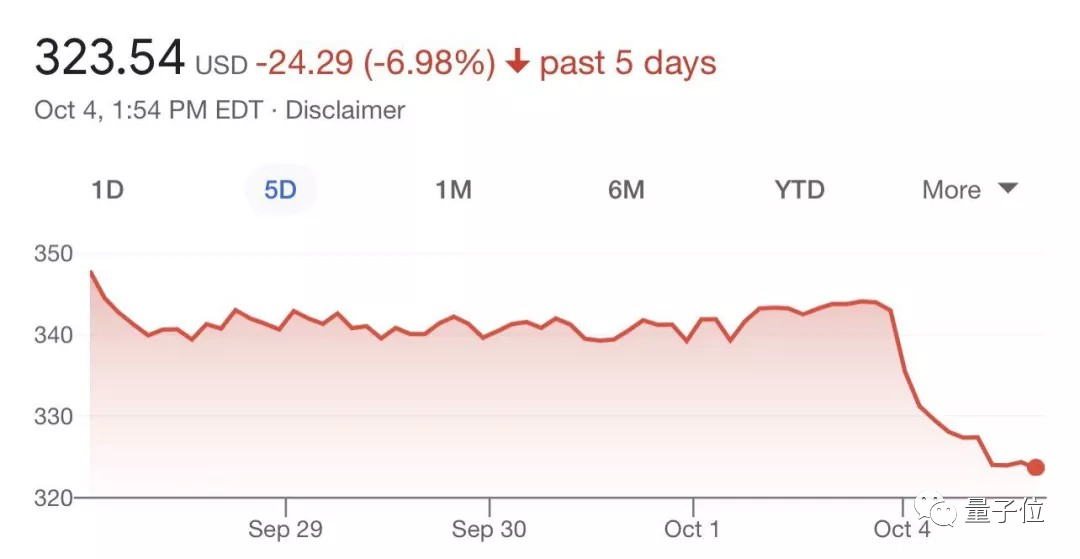
现在看来,只有小扎受伤的世界完成了(狗头表情包)。
官方回应:
[1]https://engineering.fb.com/2021/10/04/networking-traffic/outage/
[2]https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【
面试题】即可获取