
谈谈C++新标准带来的属性(Attribute)

函数
变量
函数或者变量的名称
类型
程序块
Translation Unit (这个不知道用中文咋说)
程序控制声明
[[attr1]] class C [[ attr2 ]] { } [[ attr3 ]] c [[ attr4 ]], d [[ attr5 ]];attr1 作用于class C的实体定义c和d
attr2 作用于class C的定义
attr3 作用于类型C
attr4 作用于实体c
attr5 作用于实体d



[[noreturn]]
[[carries_dependency]]
[[deprecated]] 和 [[deprecated("reason")]]
[[fallthrough]]
[[nodiscard]] 和 [[nodiscard("reason")]] (C++20)
[[maybe_unused]]
[[likely]] 和 [[unlikely]]
[[no_unique_address]]
// 正确,函数将永远不会返回。[[noreturn]] void func1(){ throw "error"; }// 错误,如果用false进行调用,函数是会返回的,这时候会导致未定义行为。[[noreturn]] void func2(bool b){ if (b) throw "error"; }int main(){try{ func1() ; }catch(char const *e){ std::cout << "Got something: " << e << " \n"; }// 此处编译会有警告信息。func2(false);}
noreturn.cpp: In function 'void func2(bool)':noreturn.cpp:11:1: warning: 'noreturn' function does return11 | }| ^
std::atomic<int *> p;std::atomic<int *> q;void func1(int *val){ std::cout << *val << std::endl; }void func2(int * [[carries_dependency]] val){ q.store(val, std::memory_order_release);std::cout << *q << std::endl; }void thread_job(){int *ptr1 = (int *)p.load(std::memory_order_consume); // 1std::cout << *ptr1 << std::endl; // 2func1(ptr1); // 3func2(ptr1); // 4}
程序在1的位置因为ptr1明确的使用了memory_order_consume的内存策略,所以对于ptr1的访问一定会被编译器排到这一行之后。
因为1的原因,所以这一行在编译的时候势必会排列在1后面。
func1并没有带任何属性,而他访问了ptr1,那么编译器为了保证内存访问策略被尊重所以必须在func1调用之间构建一个内存栅栏。如果这个线程被大量的调用,这个额外的内存栅栏将导致性能损失。
在func2中,我们使用了[[carries_dependency]]属性,那么同样的访问ptr1,编译器就知道程序已经处理好了相关的内存访问限制。这个也正如我们再func2中对val访问所做的限制是一样的。那么在func2之前,编译器就无需再插入额外的内存栅栏,提高了效率。
[]]void old_hello() {}[]]void old_greeting() {}int main(){old_hello();old_greeting();return 0;}
deprecated.cpp: In function 'int main()':deprecated.cpp:9:14: warning: 'void old_hello()' is deprecated [-Wdeprecated-declarations]9 | old_hello();| ~~~~~~~~~^~deprecated.cpp:2:6: note: declared here2 | void old_hello() {}| ^~~~~~~~~deprecated.cpp:10:17: warning: 'void old_greeting()' is deprecated:Use new_greeting() instead. [-Wdeprecated-declarations]10 | old_greeting();| ~~~~~~~~~~~~^~deprecated.cpp:5:6: note: declared here5 | void old_greeting() {}| ^~~~~~~~~~~~
类,结构体
静态数据成员,非静态数据成员
联合体,枚举,枚举项
变量,别名,命名空间
模板特化
struct [[nodiscard("IMPORTANT THING")]] important {};important i = important();important get_important() { return i; }important& get_important_ref() { return i; }important* get_important_ptr() { return &i; }int a = 42;int* [[nodiscard]] func() { return &a; }int main(){get_important(); // 此处编译器会给出警告。get_important_ref(); // 此处因为不是按值返回nodiscard类型,不会有警告。get_important_ptr(); // 同上原因,不会有警告。func(); // 此处会有警告,虽然func不按值返回,但是属性修饰的是函数。return 0;}
nodiscard.cpp:8:25: warning: 'nodiscard' attribute can only be applied to functions or to class or enumeration types [-Wattributes]8 | int* [[nodiscard]] func() { return &a; }| ^nodiscard.cpp: In function 'int main()':nodiscard.cpp:12:18: warning: ignoring returned value of type 'important',declared with attribute 'nodiscard': 'IMPORTANT THING' [-Wunused-result]12 | get_important();| ~~~~~~~~~~~~~^~nodiscard.cpp:3:11: note: in call to 'important get_important()', declared here3 | important get_important() { return i; }| ^~~~~~~~~~~~~nodiscard.cpp:1:41: note: 'important' declared here1 | struct [[nodiscard("IMPORTANT THING")]] important {};| ^~~~~~~~~
std::vector<int> vect;int main(){ vect.empty(); }
nodiscard2.cpp: In function 'int main()':attibute/nodiscard2.cpp:5:13: warning:ignoring return value of 'bool std::vector<_Tp, _Alloc>::empty() const [with _Tp = int; _Alloc = std::allocator<int>]',declared with attribute 'nodiscard' [-Wunused-result]5 | { vect.empty(); }| ~~~~~~~~~~^~In file included from /usr/local/include/c++/11.1.0/vector:67,from attibute/nodiscard2.cpp:1:/usr/local/include/c++/11.1.0/bits/stl_vector.h:1007:7: note: declared here1007 | empty() const _GLIBCXX_NOEXCEPT| ^~~~~
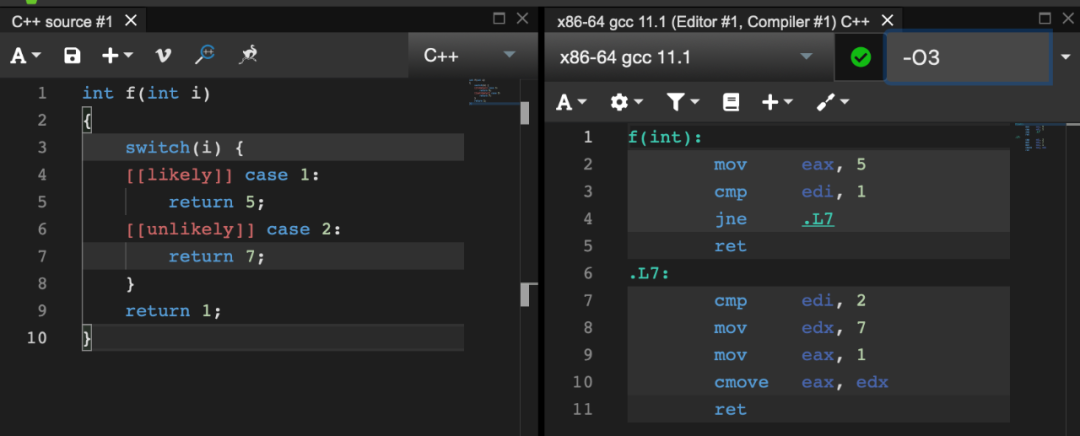
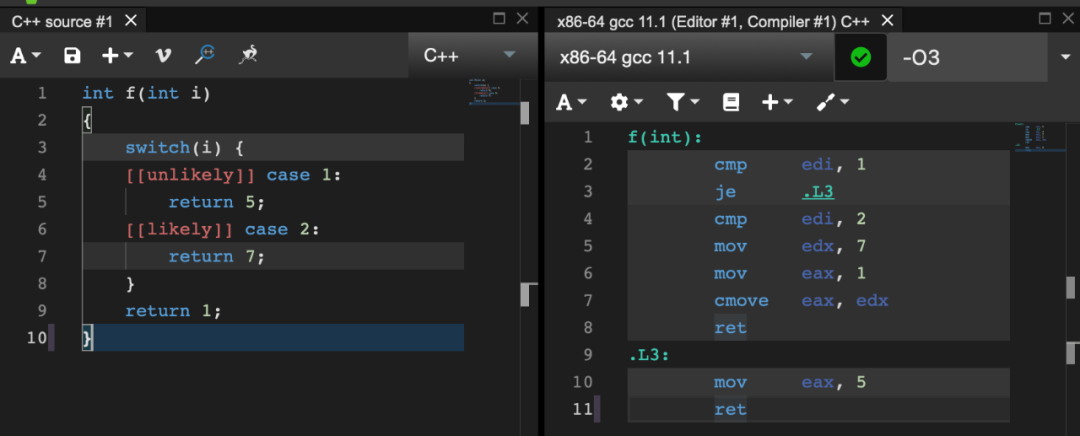
struct Empty {}; // 空类型struct X { int i; };struct Y1 { int i; Empty e; };struct Y2 { int i; [[no_unique_address]] Empty e; };struct Z1 { char c; Empty e1, e2; };struct Z2 { char c; [[no_unique_address]] Empty e1, e2; };int main(){std::cout << "空类大小:" << sizeof(Empty) << std::endl;std::cout << "只有一个int类大小:" << sizeof(X1) << std::endl;std::cout << "一个int和一个空类大小:" << sizeof(Y1) << std::endl;std::cout << "一个int和一个[[no_unique_address]]空类大小:" << sizeof(Y2) << std::endl;std::cout << "一个char和两个空类大小:" << sizeof(Z1) << std::endl;std::cout << "一个char和两个[[no_unique_address]]空类大小:" << sizeof(Z2) << std::endl;}
空类大小:1
只有一个int类大小:4
一个int和一个空类大小:8
一个int和一个[[no_unique_address]]空类大小:4
一个char和两个空类大小:3
一个char和两个[[no_unique_address]]空类大小:2
对于空类型,在C++中也会至少分配一个地址,所以空类型的尺寸大于等于1。
如果类型中有一个非空类型,那么这个类的尺寸等于这个非空类型的大小。
如果类型中有一个非空类型和一个空类型,那么尺寸一定大于非空类型尺寸,编译器还需要分配额外的地址给非空类型。具体会需要分配多少大小取决于编译器的具体实现。本例子中用的是gcc11,我们看到为了对齐,这个类型的尺寸为8,也就是说,空类型分配了一个和int对齐的4的尺寸。
如果空类型用[[no_unique_address]]属性修饰,那么这个空类型就可以和其他非同类型的非空类型共享空间,可以看到,这里编译器优化之后,空类型和int共享了同一块内存空间,整个类型的尺寸就是4。
如果类型中有一个char类型和两个空类型,那么编译器对于两个空类型都分配了和非空类型char同样大小的尺寸,整个类型占用内存为3。
同样的,如果两个空类型都用[[no_unique_address]]进行修饰的话,我们发现,其中一个空类型可以和char共享空间,但是另外一个空类型无法再次共享同一个地址,又不能和同样类型的空类型共享,所以整个结构的尺寸为2。