
为什么继承 Python 内置类型会出问题?!
△点击上方“Python猫”关注 ,回复“1”领取电子书

作者:豌豆花下猫
来源:Python猫
不久前,Python猫 给大家推荐了一本书《流畅的Python》(点击可跳转阅读),那篇文章有比较多的“溢美之词”,显得比较空泛……
但是,《流畅的Python》一书值得反复回看,可以温故知新。最近我偶然翻到书中一个有点诡异的知识点,因此准备来聊一聊这个话题——子类化内置类型可能会出问题?!

1、内置类型有哪些?
在正式开始之前,我们首先要科普一下:哪些是 Python 的内置类型?
根据官方文档的分类,内置类型(Built-in Types)主要包含如下内容:

详细文档:https://docs.python.org/3/library/stdtypes.html
其中,有大家熟知的数字类型、序列类型、文本类型、映射类型等等,当然还有我们之前介绍过的布尔类型、...对象 等等。
在这么多内容里,本文只关注那些作为可调用对象(callable)的内置类型,也就是跟内置函数(built-in function)在表面上相似的那些:int、str、list、tuple、range、set、dict……
这些类型(type)可以简单理解成其它语言中的类(class),但是 Python 在此并没有用习惯上的大驼峰命名法,因此容易让人产生一些误解。
在 Python 2.2 之后,这些内置类型可以被子类化(subclassing),也就是可以被继承(inherit)。
2、内置类型的子类化
众所周知,对于某个普通对象 x,Python 中求其长度需要用到公共的内置函数 len(x),它不像 Java 之类的面向对象语言,后者的对象一般拥有自己的 x.length() 方法。(PS:关于这两种设计风格的分析,推荐阅读 这篇文章)
现在,假设我们要定义一个列表类,希望它拥有自己的 length() 方法,同时保留普通列表该有的所有特性。
实验性的代码如下(仅作演示):
# 定义一个list的子类
class MyList(list):
def length(self):
return len(self)
我们令 MyList这个自定义类继承 list,同时新定义一个 length() 方法。这样一来,MyList 就拥有 append()、pop() 等等方法,同时还拥有 length() 方法。
# 添加两个元素
ss = MyList()
ss.append("Python")
ss.append("猫")
print(ss.length()) # 输出:2
前面提到的其它内置类型,也可以这样作子类化,应该不难理解。
顺便发散一下,内置类型的子类化有何好处/使用场景呢?
有一个很直观的例子,当我们在自定义的类里面,需要频繁用到一个列表对象时(给它添加/删除元素、作为一个整体传递……),这时候如果我们的类继承自 list,就可以直接写 self.append()、self.pop(),或者将 self 作为一个对象传递,从而不用额外定义一个列表对象,在写法上也会简洁一些。
还有其它的好处/使用场景么?欢迎大家留言讨论~~
3、内置类型子类化的“问题”
终于要进入本文的正式主题了:)
通常而言,在我们教科书式的认知中,子类中的方法会覆盖父类的同名方法,也就是说,子类方法的查找优先级要高于父类方法。
下面看一个例子,父类 Cat,子类 PythonCat,都有一个 say() 方法,作用是说出当前对象的 inner_voice:
# Python猫是一只猫
class Cat():
def say(self):
return self.inner_voice()
def inner_voice(self):
return "喵"
class PythonCat(Cat):
def inner_voice(self):
return "喵喵"
当我们创建子类 PythonCat 的对象时,它的 say() 方法会优先取到自己定义出的 inner_voice() 方法,而不是 Cat 父类的 inner_voice() 方法:
my_cat = PythonCat()
# 下面的结果符合预期
print(my_cat.inner_voice()) # 输出:喵喵
print(my_cat.say()) # 输出:喵喵
这是编程语言约定俗成的惯例,是一个基本原则,学过面向对象编程基础的同学都应该知道。
然而,当 Python 在实现继承时,似乎不完全会按照上述的规则运作。它分为两种情况:
符合常识:对于用 Python 实现的类,它们会遵循“子类先于父类”的原则 违背常识:对于实际是用 C 实现的类(即str、list、dict等等这些内置类型),在显式调用子类方法时,会遵循“子类先于父类”的原则;但是,**在存在隐式调用时,**它们似乎会遵循“父类先于子类”的原则,即通常的继承规则会在此失效
对照 PythonCat 的例子,相当于说,直接调用 my_cat.inner_voice() 时,会得到正确的“喵喵”结果,但是在调用 my_cat.say() 时,则会得到超出预期的“喵”结果。
下面是《流畅的Python》中给出的例子(12.1章节):
class DoppelDict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, [value] * 2)
dd = DoppelDict(one=1) # {'one': 1}
dd['two'] = 2 # {'one': 1, 'two': [2, 2]}
dd.update(three=3) # {'three': 3, 'one': 1, 'two': [2, 2]}

在这个例子中,dd['two'] 会直接调用子类的__setitem__()方法,所以结果符合预期。如果其它测试也符合预期的话,最终结果会是{'three': [3, 3], 'one': [1, 1], 'two': [2, 2]}。
然而,初始化和 update() 直接调用的分别是从父类继承的__init__()和__update__(),再由它们隐式地调用__setitem__()方法,此时却并没有调用子类的方法,而是调用了父类的方法,导致结果超出预期!
官方 Python 这种实现双重规则的做法,有点违背大家的常识,如果不加以注意,搞不好就容易踩坑。
那么,为什么会出现这种例外的情况呢?
4、内置类型的方法的真面目
我们知道了内置类型不会隐式地调用子类覆盖的方法,接着,就是Python猫的刨根问底时刻:为什么它不去调用呢?
《流畅的Python》书中没有继续追问,不过,我试着胡乱猜测一下(应该能从源码中得到验证):内置类型的方法都是用 C 语言实现的,事实上它们彼此之间并不存在着相互调用,所以就不存在调用时的查找优先级问题。
也就是说,前面的“__init__()和__update__()会隐式地调用__setitem__()方法”这种说法并不准确!
这几个魔术方法其实是相互独立的!__init__()有自己的 setitem 实现,并不会调用父类的__setitem__(),当然跟子类的__setitem__()就更没有关系了。
从逻辑上理解,字典的__init__()方法中包含__setitem__()的功能,因此我们以为前者会调用后者,**这是惯性思维的体现,**然而实际的调用关系可能是这样的:
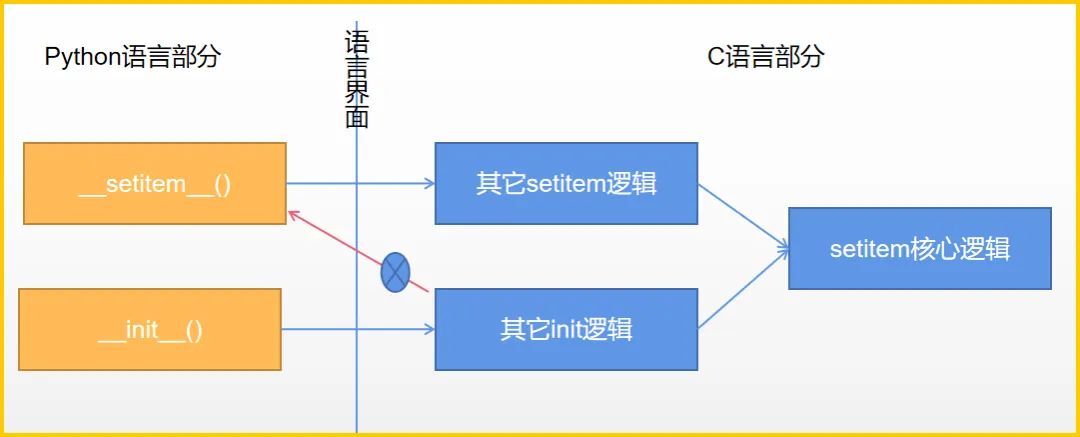
左侧的方法打开语言界面之门进入右侧的世界,在那里实现它的所有使命,并不会折返回原始界面查找下一步的指令(即不存在图中的红线路径)。不折返的原因很简单,即 C 语言间代码调用效率更高,实现路径更短,实现过程更简单。
同理,dict 类型的 get() 方法与__getitem__()也不存在调用关系,如果子类只覆盖了__getitem__()的话,当子类调用 get() 方法时,实际会使用到父类的 get() 方法。(PS:关于这一点,《流畅的Python》及 PyPy 文档的描述都不准确,它们误以为 get() 方法会调用__getitem__())
也就是说,Python 内置类型的方法本身不存在调用关系,尽管它们在底层 C 语言实现时,可能存在公共的逻辑或能被复用的方法。
我想到了“Python为什么”系列曾分析过的《Python 为什么能支持任意的真值判断?》。在我们写if xxx时,它似乎会隐式地调用__bool__()和__len__()魔术方法,然而实际上程序依据 POP_JUMP_IF_FALSE 指令,会直接进入纯 C 代码的逻辑,并不存在对这俩魔术方法的调用!
因此,在意识到 C 实现的特殊方法间相互独立之后,我们再回头看内置类型的子类化,就会有新的发现:
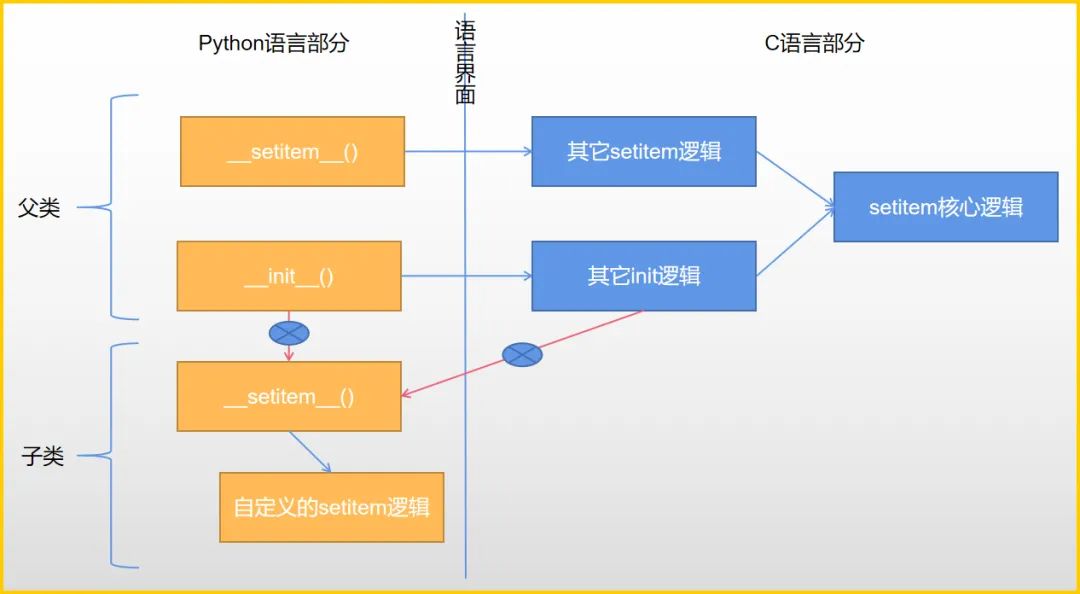
父类的__init__()魔术方法会打破语言界面实现自己的使命,然而它跟子类的__setitem__()并不存在通路,即图中红线路径不可达。
特殊方法间各行其是,由此,我们会得出跟前文不同的结论:实际上 Python 严格遵循了“子类方法先于父类方法”继承原则,并没有破坏常识!
最后值得一提的是,__missing__()是一个特例。《流畅的Python》仅仅简单而含糊地写了一句,没有过多展开。
经过初步实验,我发现当子类定义了此方法时,get() 读取不存在的 key 时,正常返回 None;但是 __getitem__() 和 dd['xxx'] 读取不存在的 key 时,都会按子类定义的__missing__()进行处理。
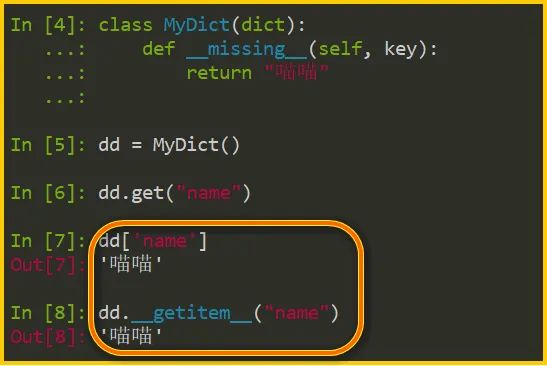
我还没空深入分析,恳请知道答案的同学给我留言。
5、内置类型子类化的最佳实践
综上所述,内置类型子类化时并没有出问题,只是由于我们没有认清特殊方法(C 语言实现的方法)的真面目,才会导致结果偏差。
那么,这又召唤出了一个新的问题:如果非要继承内置类型,最佳的实践方式是什么呢?
首先,如果在继承内置类型后,并不重写(overwrite)它的特殊方法的话,子类化就不会有任何问题。
其次,如果继承后要重写特殊方法的话,记得要把所有希望改变的方法都重写一遍,例如,如果想改变 get() 方法,就要重写 get() 方法,如果想改变 __getitem__()方法,就要重写它……
但是,如果我们只是想重写某种逻辑(即 C 语言的部分),以便所有用到该逻辑的特殊方法都发生改变的话,例如重写__setitem__()的逻辑,同时令初始化和update()等操作跟着改变,那么该怎么办呢?
我们已知特殊方法间不存在复用,也就是说单纯定义新的__setitem__()是不够的,那么,怎么才能对多个方法同时产生影响呢?
PyPy 这个非官方的 Python 版本发现了这个问题,它的做法是令内置类型的特殊方法发生调用,建立它们之间的连接通路。
官方 Python 当然也意识到了这么问题,不过它并没有改变内置类型的特性,而是提供出了新的方案:UserString、UserList、UserDict……

除了名字不一样,基本可以认为它们等同于内置类型。
这些类的基本逻辑是用 Python 实现的,相当于是把前文 C 语言界面的某些逻辑搬到了 Python 界面,在左侧建立起调用链,如此一来,就解决了某些特殊方法的复用问题。
对照前文的例子,采用新的继承方式后,结果就符合预期了:
from collections import UserDict
class DoppelDict(UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, [value] * 2)
dd = DoppelDict(one=1) # {'one': [1, 1]}
dd['two'] = 2 # {'one': [1, 1], 'two': [2, 2]}
dd.update(three=3) # {'one': [1, 1], 'two': [2, 2], 'three': [3, 3]}
显然,如果要继承 str/list/dict 的话,最佳的实践就是继承collections库提供的那几个类。
6、小结
写了这么多,是时候作 ending 了~~
在本系列的前一篇文章中,Python猫从查找顺序与运行速度两方面,分析了“为什么内置函数/内置类型不是万能的”,本文跟它一脉相承,也是揭示了内置类型的某种神秘的看似是缺陷的行为特征。
本文虽然是从《流畅的Python》书中获得的灵感,然而在语言表象之外,我们还多追问了一个“为什么”,从而更进一步地分析出了现象背后的原理。
简而言之,内置类型的特殊方法是由 C 语言独立实现的,它们在 Python 语言界面中不存在调用关系,因此在内置类型子类化时,被重写的特殊方法只会影响该方法本身,不会影响其它特殊方法的效果。
如果我们对特殊方法间的关系有错误的认知,就可能会认为 Python 破坏了“子类方法先于父类方法”的基本继承原则。(很遗憾《流畅的Python》和 PyPy 都有此错误的认知)
为了迎合大家对内置类型的普遍预期,Python 在标准库中提供了 UserString、UserList、UserDict 这些扩展类,方便程序员来继承这些基本的数据类型。
写在最后:本文属于“Python为什么”系列(Python猫出品),该系列主要关注 Python 的语法、设计和发展等话题,以一个个“为什么”式的问题为切入点,试着展现 Python 的迷人魅力。若你有其它感兴趣的话题,欢迎填在《Python的十万个为什么? 》里的调查问卷中。

近期热门文章推荐: