
成为自信的node.js开发者(一)
作者:雾豹
原文地址:https://juejin.im/post/5c6a780451882561dd7b65d6
适合阅读的同学
想更进一步深入理解node的同学,如果你已经稍微了解一点点node, 可以用node做一些小demo,并且想更深一步的了解,希望这篇文章可以帮助到你。
不太适合阅读的同学
不太熟悉基本的javascript 语法,比如说回调函数
对node有深入理解的同学,比如说,可以清晰的说出
event-loop
Node 架构——v8、libuv
第一部分,我们先了解一下node的结构,对node先有一个整体上的认识。只有这样,我们才能编写出更加高性能的代码,在遇到问题时,也知道解决的思路。
先来看一张图表:
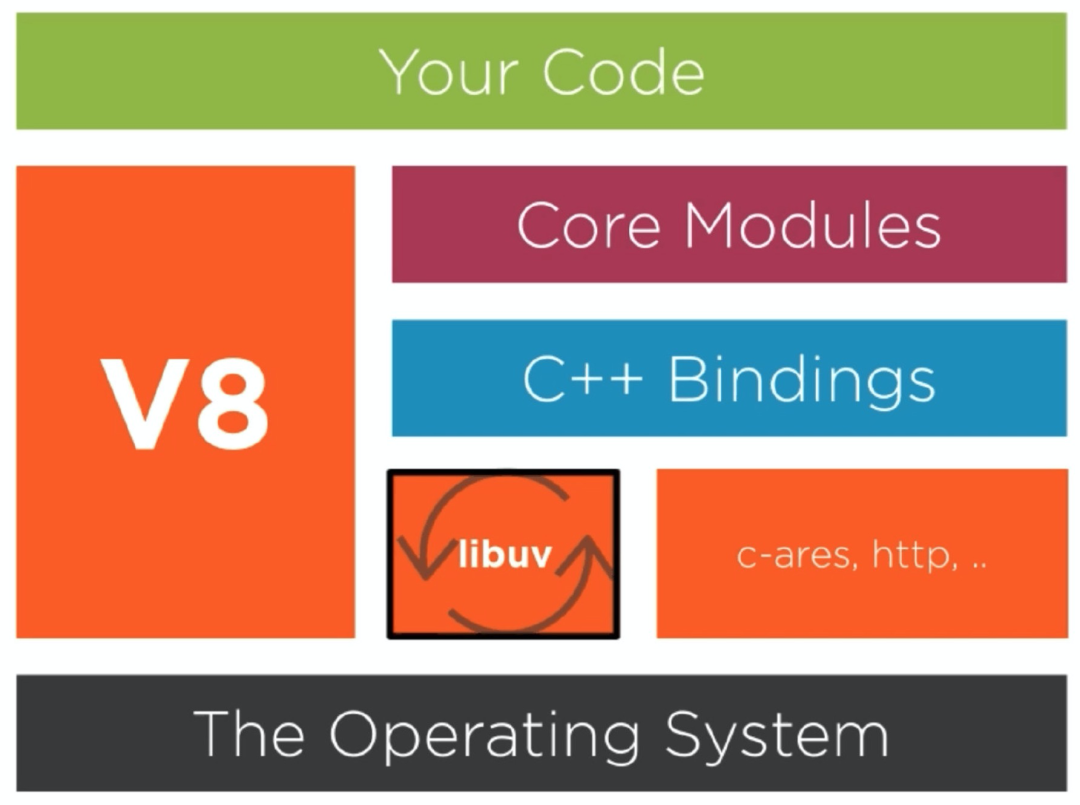
最上面是我们编写的node.js的代码,当我们执行node index.js的命令时,我们是触发了一个node的程序,和其他的javascript的项目,比如说前端的h5项目一样,该node程序需要有其他的依赖,其中最主要的两个依赖是 v8 和 libuv。
v8是 google 开源的引擎,目的是在浏览器世界外可以运行javascript的代码。
libuv 是c++ 开源的项目,最初就是专门为node设计,目的是给node和操作系统交互的能力,比如说网络, 操作文件。
node在可见的未来仍将继续使用v8, 但是微软edge浏览器的
chakra(读法:渣坷垃)引擎也是一个强有力的竞争者。https://github.com/nodejs/node-chakracore 这个项目是如何让node如何跑在chakras引擎上
v8 引擎
我们现在知道了,node 使用 v8 用来执行javascript 代码,这意味着,node中所支持的javascript的特性,是由 v8 引擎所决定的。
V8引擎支持的 javascript 特性被划分为三个不同的group: Shipping/Staged/In Progress。
默认情况下Shipping group的特性可以直接使用,Staged group的特性需要使用--harmony选项来开启。如下所示:
➜ node -v
v7.9.0
➜ node -p 'process.versions.v8'
5.5.372.43
➜ node -p "'Node'.padEnd(8, '*')" // 默认是不支持的
[eval]:1
'Node'.padEnd(8, '*')
^
TypeError: "Node".padEnd is not a function
at [eval]:1:8
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at Object.runInThisContext (vm.js:95:38)
at Object. ([eval]-wrapper:6:22)
at Module._compile (module.js:571:32)
at evalScript (bootstrap_node.js:387:27)
at run (bootstrap_node.js:120:11)
at run (bootstrap_node.js:423:7)
at startup (bootstrap_node.js:119:9)
at bootstrap_node.js:538:3
➜ node --harmony -p "'Node'.padEnd(8, '*')" // 通过--harmony
Node****
In Progress group的feature不稳定,但你也可以使用特定的flag来开启,通过 node --v8-options 命令可以查看,通过grep 命令去查找in progress,如下:
➜ node --v8-options | grep "in progress"
--harmony_array_prototype_values (enable "harmony Array.prototype.values" (in progress))
--harmony_function_sent (enable "harmony function.sent" (in progress))
--harmony_sharedarraybuffer (enable "harmony sharedarraybuffer" (in progress))
--harmony_simd (enable "harmony simd" (in progress))
--harmony_do_expressions (enable "harmony do-expressions" (in progress))
--harmony_restrictive_generators (enable "harmony restrictions on generator declarations" (in progress))
--harmony_regexp_named_captures (enable "harmony regexp named captures" (in progress))
--harmony_regexp_property (enable "harmony unicode regexp property classes" (in progress))
--harmony_for_in (enable "harmony for-in syntax" (in progress))
--harmony_trailing_commas (enable "harmony trailing commas in function parameter lists" (in progress))
--harmony_class_fields (enable "harmony public fields in class literals" (in progress))
比如说,上面打印出来的倒数第二行-- harmony_trailing_commas 可以支持函数传参尾逗号:
node -p 'function tc(a,b,) {}' // 会报错,因为最后一个逗号
=========================
node --harmony_trailing_commas -p 'function tc(a,b,) {}' //不会报错
libuv
libuv提供了和操作系统交互的能力,比如说操作文件,网络等等,并且磨平了操作系统的差异。node还使用
libuv来处理异步操作,比如非阻塞IO(file system/TCP socket/child process)。当异步操作完成时,node通常需要调用回调函数,当调用回调函数时,node会把控制权交给V8引擎。当回调函数执行完毕,控制权从v8引擎重新回到node.v8 引擎是单线程的,当v8引擎获得控制权的时候,node 只能等待v8 引擎操作完成。
这让node没有死锁,竞争的概念。
libuv包含一个线程池,从操作系统的层面来做那些不能被异步做的事情libuv给node 提供了event-loop, 会在第二节介绍
其他依赖
除了v8引擎和 libuv, node 还有其他的一些比较重要的依赖。

http-parser 用来解析http内容的
c-ares 是用来支持异步的DNS 查询的
openSSL 常用在 tls 和 crypto 的包中,提供了加密的方法
zlib 是用来压缩和解压的
node REPL
你可以在terminal里面执行node来启动CLI,如下所示,REPL十分方便
例如,你定义一个array,当你arr.然后tab-tab(tab两次),array自身的方法会显示出来
➜ node
> var arr = [];
undefined
> arr.
arr.toString arr.valueOf
arr.concat arr.copyWithin arr.entries arr.every arr.fill arr.filter
arr.find arr.findIndex arr.forEach arr.includes arr.indexOf arr.join
arr.keys arr.lastIndexOf arr.length arr.map arr.pop arr.push
arr.reduce arr.reduceRight arr.reverse arr.shift arr.slice arr.some
arr.sort arr.splice arr.unshift
你也可以输入.help,然后可以看到各种快捷键如下:
> .help
.break Sometimes you get stuck, this gets you out
.clear Alias for .break
.editor Enter editor mode
.exit Exit the repl
.help Print this help message
.load Load JS from a file into the REPL session
.save Save all evaluated commands in this REPL session to a file
你还可以用_(underscore)来得到上次evaluated的值:
> 3 - 2
1
> _
1
> 3 < 2
false
> _
false
你还可以自定义REPL选项,如下,你自定义repl.js并选择忽视undefined,这样output里面就不会有undefined输出,同时你还可以预先加载你需要的library比如lodash
// repl.js
let repl = require('repl');
let r = repl.start({ ignoreUndefined: true });
r.context.lodash = require('lodash');
➜ node ~/repl.js
> var i = 2;
>
>
你可以用下面的command来查看更多的选项 node --help | less
-p, --print evaluate script and print result
-c, --check syntax check script without executing
-r, --require module to preload (option can be repeated)
例如,node -c bad-syntax.js可以用来检查语法错误, node -p 'os.cpus()'可以用来执行script并输出结果,你还可以传入参数,如下所示
➜ node -p 'process.argv.slice(1)' test 666
[ 'test', '666' ]
node -r babel-core/register可以用来预加载,相当于require('babel-core/register')
global 中的 process 和 buffer
global相当于浏览器里面的window,你可以global.a = 1;这样a就是全局变量,但一般不推荐这样做
global 对象身上有两个属性特别重要: process 和 buffer
process
process是application和running env之间的桥梁,可以得到运行环境相关信息,如下所示:
> process.
process.arch
process.argv
process.argv0 process.assert process.binding
process.chdir
process.config process.cpuUsage
process.cwd process.debugPort
process.dlopen process.emitWarning
process.env process.execArgv
process.execPath
process.exit process.features process.getegid
process.geteuid process.getgid process.getgroups process.getuid
process.hrtime process.initgroups
process.kill process.memoryUsage
process.moduleLoadList process.nextTick process.openStdin
process.pid
process.platform process.reallyExit process.release process.setegid
process.seteuid process.setgid process.setgroups process.setuid
process.stderr process.stdin process.stdout
process.title
process.umask process.uptime process.version process.versions
process._events process._maxListeners process.addListener process.domain
process.emit process.eventNames process.getMaxListeners process.listenerCount
process.listeners
process.on
process.once process.prependListener
process.prependOnceListener process.removeAllListeners process.removeListener process.setMaxListeners\
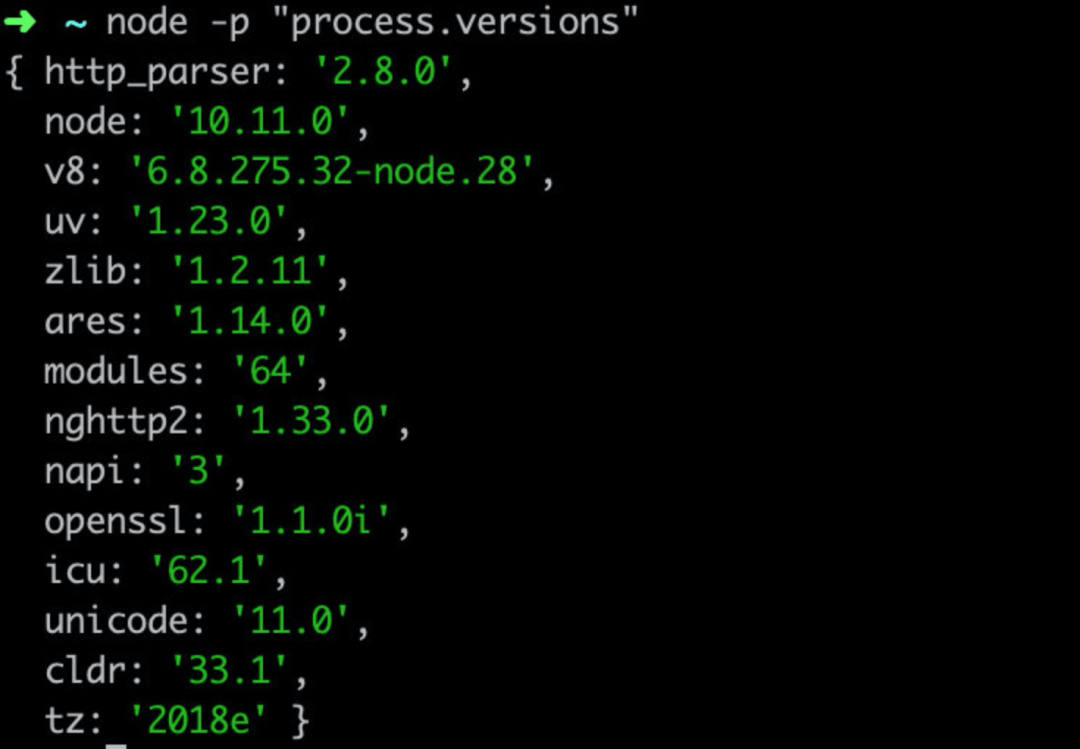
process.versions 非常有用:
process.env 提供了当前环境的一些信息
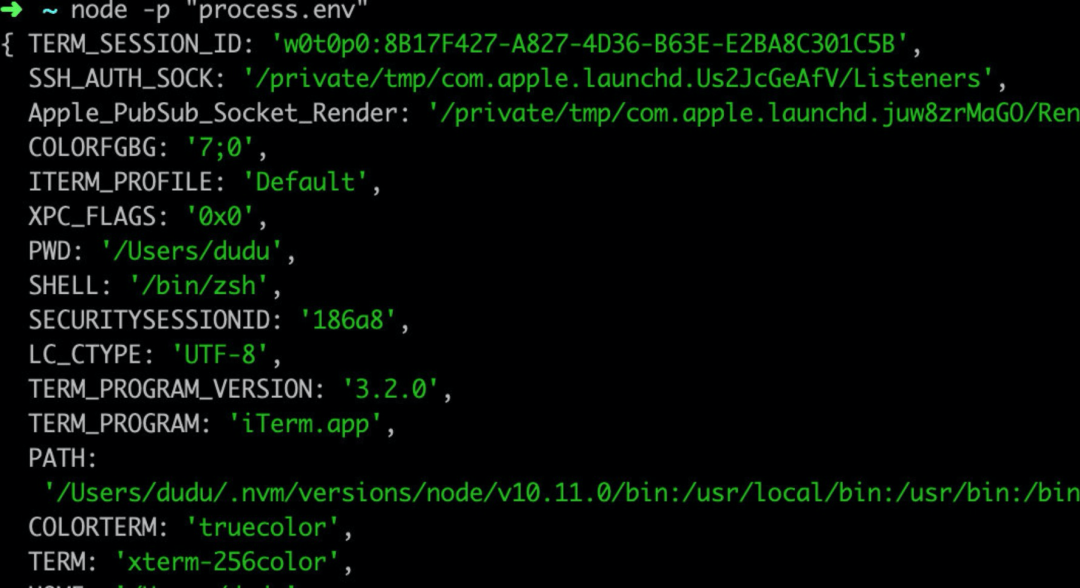
建议从 process.env 中只读,因为改了也没有用。
同时,process也是一个event emitter,例如:
process.on('exit', code => {
// 并不能阻止node进程退出
console.log(code)
})
process.on('uncaughtException', err => {
console.error(err)
process.exit(1)
})
在process 的事件处理函数中,我们只能执行同步的方法,而不能使用event_loop,
exit和uncaughtException的�区别。如果uncaughtException注册了事件,则node遇到错误并不会退出,也就是说,不会触发exit事件。这会让node的执行变的不可预测。证明如下:process.on('exit', (code) => {
console.log('ssss')
})
process.on('uncaughtException', (err) => {
console.error(err);
})
// keep the event loop busy
process.stdin.resume()
// 在这里触发了bug
console.logg()上面的代码即使遇到了错误也不会退出执行,
exit事件处理函数并不会触发。所以需要我们手动触发process.exit(1)才可以。
buffer
buffer 也是 global 对象中的一个属性,主要用来处理二进制流。 buffer 本质上是一段内存片段,是放在v8引擎的堆的外面。
我们可以在buffer 这个内存中存放数据。
从 buffer读取数据时,我们必须指定encoding, 因此从 files 和 sockets 中读取数据时,如果不指定encoding, 我们会得到一个 buffer 对象。
一旦buffer 被创建,就不能修改大小
buffer 在处理读取文件,网络数据流的时候非常有用
创建buffer的三种方式:
Buffer.alloc(2)
在内存中划分出固定的大小
Buffer.allocUnsafe(8)
没有指定具体的数据,可能会包含老的数据和敏感的数据,需要被正确的『填充』
Buffer.from()
buffer的方法
和数组类似,但是不同。比如说 slice 方法截取出来的新buffer 和 老的buffer是共享同一个内存。
stringDecode
当转变二进制数据流的时候,toString() 不如使用 stringDecode 模块,因为该模块可以处理不完整的数据呢。
Require() 的背后
如果想深入了解node, 必须要深入了解 require 方法。
涉及到两个核心模块——require 方法(在grobal对象上,但是每一个模块都有自己的require 方法) 和 Module 模块 (同样在grobal对象上,用来管理模块的)
require 分为几步
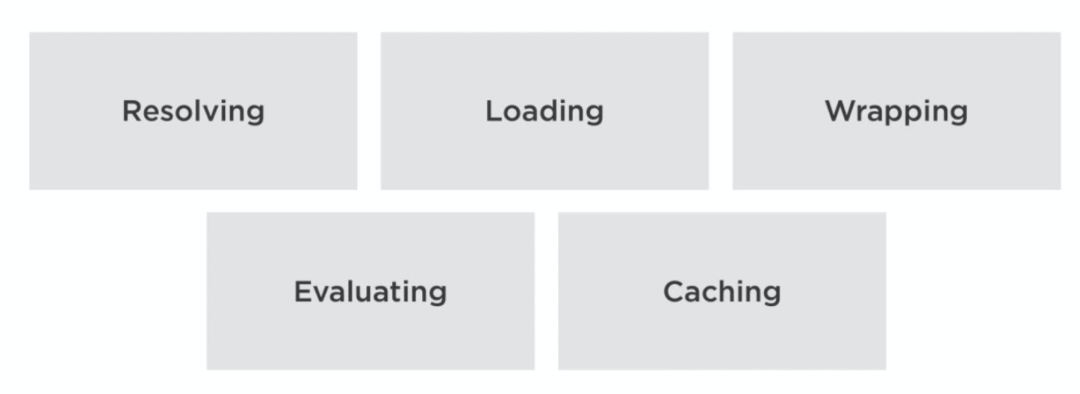
当我们require一个module时,整个过程有五个步骤:
Resolving找到module的绝对文件路径
Loading将文件内容加载到内存
Wrapping给每个module创造一个private scope并确保require对每个module来说是local变量
EvaluatingVM执行module代码
Caching缓存module以备下次使用
module 对象
Module {
id: '.',
exports: {},
parent: undefined,
filename: '/Users/xxx/lib/find.js',
loaded: false,
children: [],
paths:
[ '/Users/xxx/lib/node_modules',
'/Users/xxx/node_modules',
'/Users/node_modules',
'/node_modules' ] }
在Module对象里面,id 是module的identity,通常它的值是module文件的全路径,除非是root,这时它的值是.(dot)
filename 是文件的路径
paths 从当前路径开始,往上一直到根路径
require.resolve 和require一样,但是它不会加载文件,只是resolve
模块不一定是文件�
可以是文件,比如说
node_module/find-me.js可以是目录带
index.js,比如说node_module/find-me/index.js可以是目录带
package.json, 比如说node_module/find-me/main.js{
"name": "find-me",
"main": "start.js"
}
exports 属性
exports 是module 上一个特殊的属性,我们放入它的任何变量都可以在require时得到 。
loaded
Module对象的loaded属性会保持false,直到所有content都被加载
因此,exports 不能放在的异步的setImmediate 中
循环引用
例如A require B,B require A
JSON 文件 和 c++ Addon 文件
Node会首先查找.js文件,再查找.json文件,最后.node文件 比如说,在主文件中,引入.json 文件
// 在主文件中
let mock = require('mockData.json')
console.log(mock)
在mockData.json 文件中,不需要导出什么,直接写json格式的即可
{
"a": "abc",
"b": "abc",
}如果node找不到 .js , .json 文件,就会找.node 文件,会把.node 文件作为一个编译好的addon(插件) module。那么 .node 文件是从哪里来的呢?
先有一个 hello.cc 文件,是用 c++ 代码写的
�再有一个 binding.gyp, 相当于的编译的配置文件,里面是
json格式的配置项, 如下面所示:{
"targets": [
{
"target_name": "addon",
"sources": [ "hello.cc" ]
}
]
}安装
npm install node-gyp -g, node 和 npm 自带的那个不是给开发者�用的,而是需要重新安装一个node-gyp configure根据平台生成项目,再执行node-gyp build生成.node文件,可以在js的代码中直接引用使用了。你可以通过
require.extensions来查看Node支持的文件扩展名:
> require.extensions
{ '.js': [Function], '.json': [Function], '.node': [Function] }

上面的代码中,对于 .js 文件,是直接编译引入,对于.json 文件,是使用了JSON.parse 方法,对于 .node 文件,是使用了 process.dlopen() 方法。
包裹模块
exports.id = 1; // 对的
exports = {
id: 1, // 错的
}
module.exports = {
id: 1 // 对的
}
上面的代码中,为什么exports 和 module.exports 有区别?
原因是,node 引入一个模块代码后,node 会给这些代码外面包裹上一层方法,这个方法是module 模块的wrapper 方法:
> require('module').wrapper
>[ '(function (exports, require, module, __filename, __dirname) { ',
'\n});' ]
这个方法接受5个参数: exports, require, module, __filename, __dirname
这个方法,让 exports, require, module 看起来是全局变量,但其实是每个文件所独有的。
exports 是 module 对象的module.exports 方法的引用,相当于 let exports s = module.exports, 如果让 exports = {} 等于让 exports 变量改写了引用
缓存模块
当第二次引入同一个文件的时候,将会走了缓存。
console.log(require.cache)
delete require.cache['/User/sss/sss/cache.js']
下一期我们再见~