
pandas 与 lambda 完美结合指南
大邓和他的Python
共 2661字,需浏览 6分钟
· 2021-12-28
lambda方法以及它在pandas模块当中的运用,熟练掌握可以极大地提高数据分析与挖掘的效率导入模块与读取数据
我们第一步需要导入模块以及数据集
import pandas as pd
df = pd.read_csv("IMDB-Movie-Data.csv")
df.head()
创建新的列
df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2
lambda方法就很多必要被运用到了,我们先来定义一个函数方法def custom_rating(genre,rating):
if 'Thriller' in genre:
return min(10,rating+1)
elif 'Comedy' in genre:
return max(0,rating-1)
elif 'Drama' in genre:
return max(5, rating-1)
else:
return rating
apply方法和lambda方法将这个自定义的函数应用在这个DataFrame数据集当中df["CustomRating"] = df.apply(lambda x: custom_rating(x['Genre'], x['Rating']), axis = 1)
axis参数的作用,其中axis=1代表跨列而axis=0代表跨行,如下图所示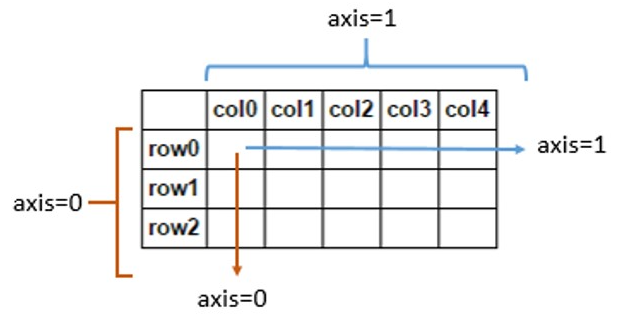
筛选数据
pandas当中筛选数据相对来说比较容易,可以用到& | ~这些操作符,代码如下# 单个条件,评分大于5分的
df_gt_5 = df[df['Rating']>5]
# 多个条件: AND - 同时满足评分高于5分并且投票大于100000的
And_df = df[(df['Rating']>5) & (df['Votes']>100000)]
# 多个条件: OR - 满足评分高于5分或者投票大于100000的
Or_df = df[(df['Rating']>5) | (df['Votes']>100000)]
# 多个条件:NOT - 将满足评分高于5分或者投票大于100000的数据排除掉
Not_df = df[~((df['Rating']>5) | (df['Votes']>100000))]
电影的影名长度大于5的部分,要是也采用上面的方式就会报错df[len(df['Title'].split(" "))>=5]
output
AttributeError: 'Series' object has no attribute 'split'
这里我们还是采用apply和lambda相结合,来实现上面的功能
#创建一个新的列来存储每一影片名的长度
df['num_words_title'] = df.apply(lambda x : len(x['Title'].split(" ")),axis=1)
#筛选出影片名长度大于5的部分
new_df = df[df['num_words_title']>=5]
当然要是大家觉得上面的方法有点繁琐的话,也可以一步到位
new_df = df[df.apply(lambda x : len(x['Title'].split(" "))>=5,axis=1)]
我们先要对每年票房的的平均值做一个归总,代码如下
year_revenue_dict = df.groupby(['Year']).agg({'Revenue(Millions)':np.mean}).to_dict()['Revenue(Millions)']
def bool_provider(revenue, year):
return revenue然后我们通过结合apply方法和lambda方法应用到数据集当中去
new_df = df[df.apply(lambda x : bool_provider(x['Revenue(Millions)'],
x['Year']),axis=1)]
.loc方法,它同时也可以和lambda方法联用,例如我们想要筛选出评分在5-8分之间的电影以及它们的票房,代码如下df.loc[lambda x: (x["Rating"] > 5) & (x["Rating"] < 8)][["Title", "Revenue (Millions)"]]
转变指定列的数据类型
astype方法来实现的,例如我们将“Price”这一列的数据类型转变成整型的数据,代码如下df['Price'].astype('int')
会出现如下所示的报错信息
ValueError: invalid literal for int() with base 10: '12,000'
astype方法实现数据类型转换就会报错,因此我们还需要将到apply和lambda结合进行数据的清洗,代码如下df['Price'] = df.apply(lambda x: int(x['Price'].replace(',', '')),axis=1)
方法调用过程的可视化
这里用到的是tqdm模块,我们将其导入进来
from tqdm import tqdm, tqdm_notebook
tqdm_notebook().pandas()
然后将apply方法替换成progress_apply即可,代码如下
df["CustomRating"] = df.progress_apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
output

当lambda方法遇到if-else
当然我们也可以将if-else运用在lambda自定义函数当中,代码如下
Bigger = lambda x, y : x if(x > y) else y
Bigger(2, 10)
output
10
if-else,这样写起来就有点麻烦了,代码如下df['Rating'].apply(lambda x:"低分电影" if x < 3 else ("中等电影" if x>=3 and x < 5 else("高分电影" if x>=8 else "值得观看")))
apply和lambda方法搭配使用。近期文章
如何在DataFrame中使用If-Else条件语句创建新列
Phonemizer | Python文本语音(音素)表征包
评论
一女子与一男子在阳台上打扑克,被邻居偷拍后...
近日网络上又发生了一起疑似黄色谣言的事件:一女子与一男子在阳台上打扑克,被邻居偷拍后上传到网上,引发广泛舆论讨论。根据网传视频显示,一名穿着吊带睡衣的女子与一名光着上身的男性在阳台上交谈,随后开始打起扑克牌。这一幕被邻居拍下并上传至网络后,引发了许多网友的关注和猜测,其中大部分涉及到了不当的假设。当
逆锋起笔
0
字节的跳动职级与薪资(2024年)
上一篇:阿里公布年终奖,P7, 3.5+,22W年终奖,还有35W长期现金激励,真香字节跳动自2012年3月成立以来,已经迅速成长为一个全球性的科技公司。其产品和服务已经遍布全球150多个国家与地区,并且支持超过75种不同的语言。在字节跳动的官方网站上,列出了一系列引人注目的产品和服务,包括但不限于
开发者全社区
0
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路
1、《一本书讲透 Elasticsearch》销售最近进展汇报给大家同步一下《一本书讲透 Elasticsearch》图书的进展情况,本周五(2024年4月26日),出版社编辑老师反馈图书相关销量进展:预计全网销量 1000 册+,发货量 2462 册(截止2024年4月28日)。2023年12月2
铭毅天下
0
展讯平台手机重启问题分析指南
和你一起终身学习,这里是程序员Android经典好文推荐,通过阅读本文,您将收获以下知识点:一、 User 版本 默认开启 sysdump 方法二、插入SD卡 抓取Sysdump log三、 sysdump log 分析四、展讯平台抓取重启 串口log的方案五、展讯平台判断重启类型六、展讯平台关闭
程序员Android
0
国产算力训练大模型的经验与教训
本文来自“国产算力训练大模型的经验与教训”。本文介绍大模型的计算特征(国产平台介绍、系统挑战、算子实现、容错)、框架的并行性支持、未来算法等。随着ChatGPT的横空出世,人工智能大模型成为各行各业热议的焦点,国内外各种大模型如雨后春笋般涌现,引发了新一轮人工智能热潮。但在看到大模型取得巨大进步的同
架构师技术联盟
1
Java与lua互相调用简单教程
来源:网络👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目 2.0 版本完结啦, 演示链接:http://116.62.199.48/ ,新项目
小哈学Java
0
【送书福利】《Java面试八股文:高频面试题与求职攻略一本通》
先来唠唠最近粉丝面试回来跟我聊天,基本上都提到一个点,在面试过程中八股文占比很高(八股文70%、项目20%、10%算法)除了一些搞算法突出的厂除外。其实现在很多厂八股都是逐渐深入的方式来问,所以大家在学习的过程中,针对一些重点的内容,最好深入去学习,不然还是比较难应对这种追问式的问题。最近刚好从一位
Java后端技术
0
2024跨屏营销指南
下载报告去公众号:硬核刘大 后台回复“ 跨屏营销”,即可下载完整PDF文件。更多报告内容,可加微信:chanpin628 领取。(ps:加过微信:yw5201a1 的不要再加,分享的内容一样,有一个号就行。)申明:报告版权 勾正科技&MMA
产品刘
0