
持续更新!Python文献超级搜索下载工具
文献搜索对于广大学子来说真的是个麻烦事
 ,如果你的学校购买的论文下载权限不够多,或者不在校园内,那就很头痛了。幸好,我们有Python制作的这个论文搜索工具,简化了我们学习的复杂性
,如果你的学校购买的论文下载权限不够多,或者不在校园内,那就很头痛了。幸好,我们有Python制作的这个论文搜索工具,简化了我们学习的复杂性
2020-05-28补充:已用最新的scihub提取网,目前项目可用,感谢@lisenjor的分享。
2020-06-25补充:增加关键词搜索,批量下载论文功能。
2021-01-07补充:增加异步下载方式,加快下载速度;加强下载稳定性,不再出现文件损坏的情况。
2021-04-08补充:由于sciencedirect增加了机器人检验,现在搜索下载功能需要先在HEADERS中填入Cookie才可爬取,详见第4步。
本文完整源代码可在 GitHub 找到:
https://github.com/Ckend/scihub-cn
1. 什么是Scihub
首先给大家介绍一下Sci-hub这个线上数据库,这个数据库提供了约8千万篇科学学术论文和文章下载。由一名叫亚历珊卓·艾尔巴金的研究生建立,她过去在哈佛大学从事研究时发现支付所需要的数百篇论文的费用实在是太高了,因此就萌生了创建这个网站,让更多人获得知识的想法

后来,这个网站越来越出名,逐渐地在更多地国家如印度、印度尼西亚、中国、俄罗斯等国家盛行,并成功地和一些组织合作,共同维护和运营这个网站。到了2017年的时候,网站上已有81600000篇学术论文,占到了所有学术论文的69%,基本满足大部分论文的需求,而剩下的31%是研究者不想获取的论文。
2. 为什么我们需要用Python工具下载
在起初,这个网站是所有人都能够访问的,但是随着其知名度的提升,越来越多的出版社盯上了他们,在2015年时被美国法院封禁后其在美国的服务器便无法被继续访问,因此从那个时候开始,他们就跟出版社们打起了游击战
游击战的缺点就是导致scihub的地址需要经常更换,所以我们没办法准确地一直使用某一个地址访问这个数据库。当然也有一些别的方法可让我们长时间访问这个网站,比如说修改DNS,修改hosts文件,不过这些方法不仅麻烦,而且也不是长久之计,还是存在失效的可能的。
3. 新姿势:用Python写好的API工具超方便下载论文
这是一个来自github的开源非官方API工具,下载地址为:
https://github.com/zaytoun/scihub.py
但由于作者长久不更新,原始的下载工具已经无法使用,Python实用宝典修改了作者的源代码,适配了中文环境的下载器,并添加了异步批量下载等方法:
https://github.com/Ckend/scihub-cn
欢迎给我一个Star,鼓励我继续维护这个仓库。如果你访问不了GitHub,请在 Python实用宝典 公众号后台回复 scihub,下载最新可用代码。
解压下载的压缩包后,使用CMD/Terminal进入这个文件夹,输入以下命令(默认你已经安装好了Python)安装依赖:
pip install -r requirements.txt然后我们就可以准备开始使用啦!
这个工具使用起来非常简单,有两种方式,第一种方式你可以先在 Google 学术(搜索到论文的网址即可)或ieee上找到你需要的论文,复制论文网址如:
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1648853
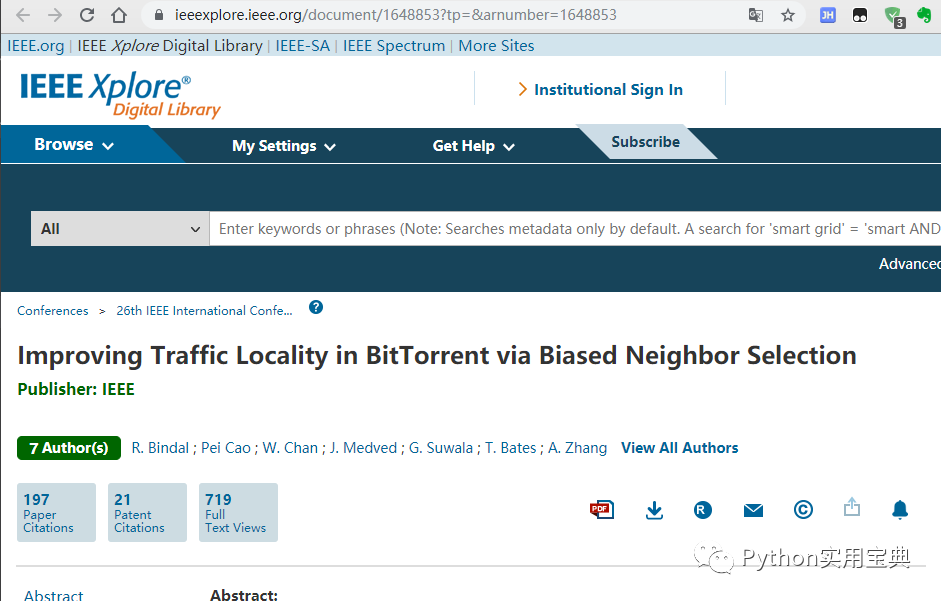
ieee文章
然后在scihub文件夹的scihub里新建一个文件叫download.py, 输入以下代码:
from scihub import SciHub
sh = SciHub()
# 第一个参数输入论文的网站地址
# path: 文件保存路径
result = sh.download('http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1648853', path='paper.pdf')进入该文件夹后在cmd/terminal中运行:
python download.py你就会发现文件成功下载到你的当前目录啦,名字为paper.pdf如果不行,多试几次就可以啦,还是不行的话,可以在下方留言区询问哦。
上述是第一种下载方式,第二种方式你可以通过在知网或者百度学术上搜索论文拿到DOI号进行下载,比如:
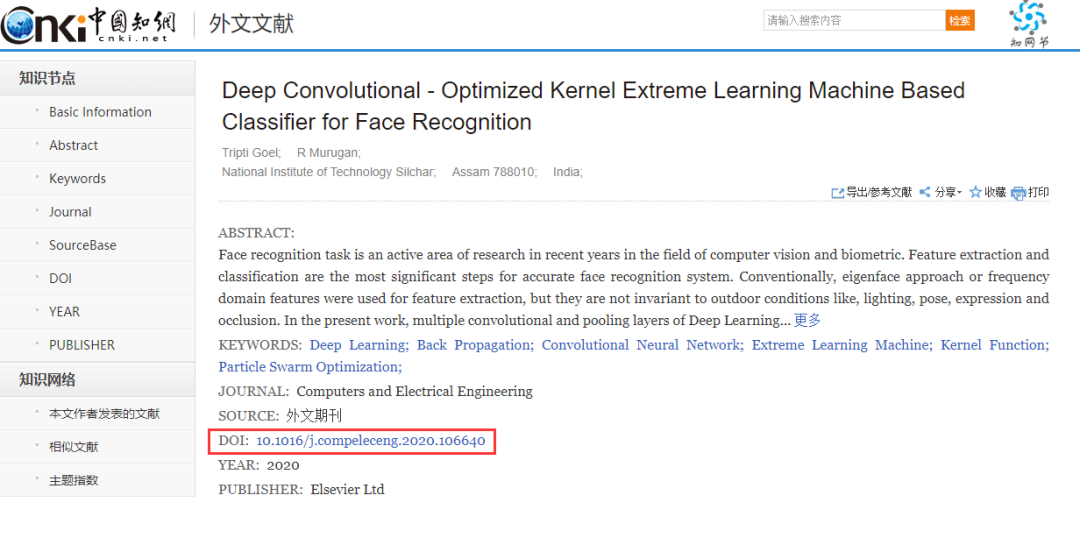
将DOI号填入download函数中:
from scihub import SciHub
sh = SciHub()
result = sh.download('10.1016/j.compeleceng.2020.106640', path='paper2.pdf')下载完成后就会在文件夹中出现该文献:
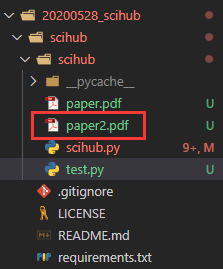
4. 基于关键词的论文批量下载
今天更新了一波接口,现在支持使用搜索的形式批量下载论文,比如说搜索关键词 端午节(Dragon Boat Festival):
from scihub import SciHub
sh = SciHub()
# 搜索词
keywords = "Dragon Boat Festival"
# 搜索该关键词相关的论文,limit为篇数
result = sh.search(keywords, limit=10)
print(result)
for index, paper in enumerate(result.get("papers", [])):
# 批量下载这些论文
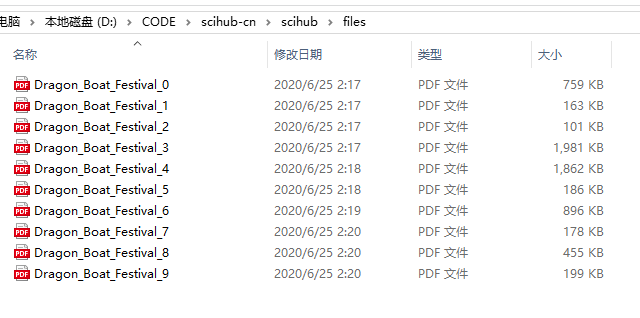
sh.download(paper["url"], path=f"files/{keywords.replace(' ', '_')}_{index}.pdf")运行结果,下载成功:
2021-04-08 更新:
由于 sciencedirect 加强了他们的爬虫防护能力,增加了机器人校验机制,所以现在必须在HEADER中填入Cookie才能进行爬取。
操作如下:
1.获取Cookie
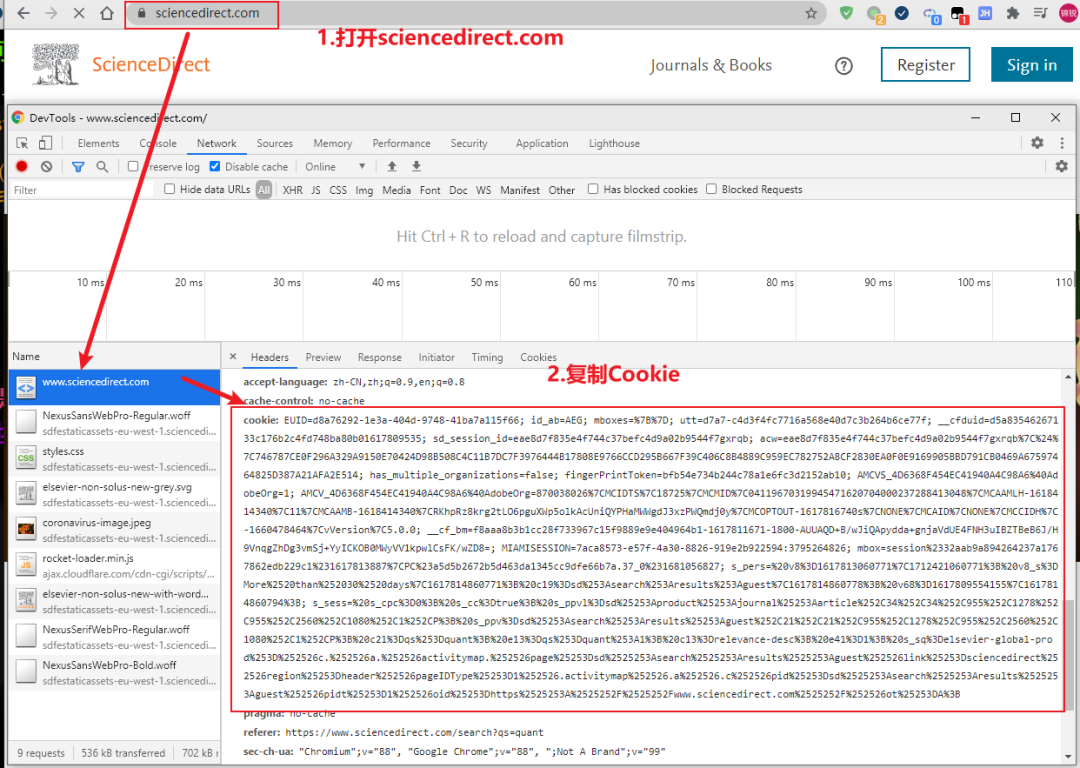
2.将Cookie粘贴到scihub文件夹下scihub.py文件的HEADERS变量中,如下图示:
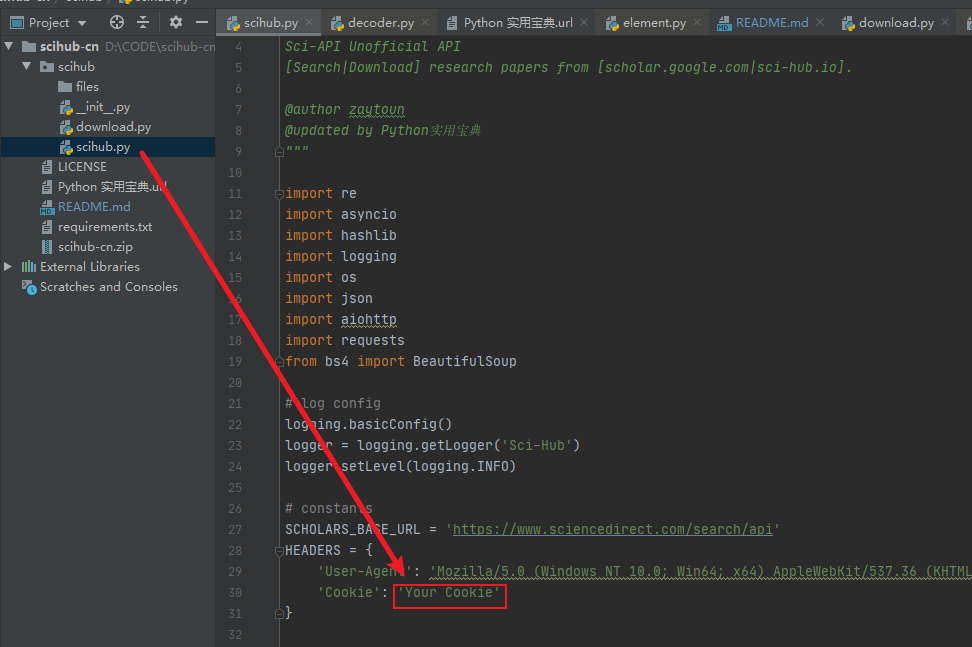
再进行关键词搜索就能正常获取论文了。
5. 异步下载优化,增加超时控制
这个开源代码库已经运行了几个月,经常有同学反馈搜索论文后下载论文的速度过慢、下载的文件损坏的问题,这几天刚好有时间一起解决了。
下载速度过慢是因为之前的版本使用了串行的方式去获取数据和保存文件,事实上对于这种IO密集型的操作,最高效的方式是用 asyncio 异步的形式去进行文件的下载。
而下载的文件损坏则是因为下载时间过长,触发了超时限制,导致文件传输过程直接被腰斩了。
因此,我们将在原有代码的基础上添加两个方法:1.异步请求下载链接,2.异步保存文件。
此外增加一个错误提示:如果下载超时了,提示用户下载超时并不保存损坏的文件,用户可自行选择调高超时限制。
首先,新增异步获取scihub直链的方法,改为异步获取相关论文的scihub直链:
async def async_get_direct_url(self, identifier):
"""
异步获取scihub直链
"""
async with aiohttp.ClientSession() as sess:
async with sess.get(self.base_url + identifier) as res:
logger.info(f"Fetching {self.base_url + identifier}...")
# await 等待任务完成
html = await res.text(encoding='utf-8')
s = self._get_soup(html)
iframe = s.find('iframe')
if iframe:
return iframe.get('src') if not iframe.get('src').startswith('//') \
else 'http:' + iframe.get('src')
else:
return None这样,在搜索论文后,调用该接口就能获取所有需要下载的scihub直链,速度很快:
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["url"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)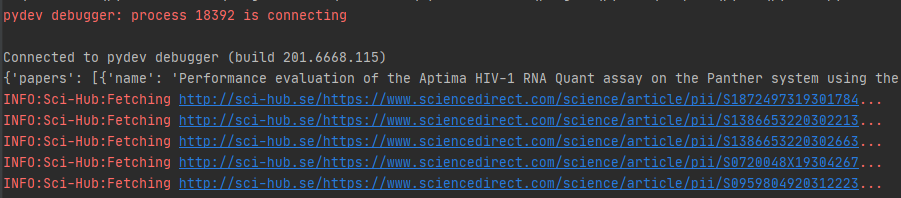
获取直链后,需要下载论文,同样也是IO密集型操作,增加2个异步函数:
async def job(self, session, url, destination='', path=None):
"""
异步下载文件
"""
file_name = url.split("/")[-1].split("#")[0]
logger.info(f"正在读取并写入 {file_name} 中...")
# 异步读取内容
try:
url_handler = await session.get(url)
content = await url_handler.read()
except:
logger.error("获取源文件超时,请检查网络环境或增加超时时限")
return str(url)
with open(os.path.join(destination, path + file_name), 'wb') as f:
# 写入至文件
f.write(content)
return str(url)
async def async_download(self, loop, urls, destination='', path=None):
"""
触发异步下载任务
如果你要增加超时时间,请修改 total=300
"""
async with aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=300)) as session:
# 建立会话session
tasks = [loop.create_task(self.job(session, url, destination, path)) for url in urls]
# 建立所有任务
finished, unfinished = await asyncio.wait(tasks)
# 触发await,等待任务完成
[r.result() for r in finished]最后,在search函数中补充下载操作:
import asyncio
from scihub import SciHub
def search(keywords: str, limit: int):
"""
搜索相关论文并下载
Args:
keywords (str): 关键词
limit (int): 篇数
"""
sh = SciHub()
result = sh.search(keywords, limit=limit)
print(result)
loop = asyncio.get_event_loop()
# 获取所有需要下载的scihub直链
tasks = [sh.async_get_direct_url(paper["url"]) for paper in result.get("papers", [])]
all_direct_urls = loop.run_until_complete(asyncio.gather(*tasks))
print(all_direct_urls)
# 下载所有论文
loop.run_until_complete(sh.async_download(loop, all_direct_urls, path=f"files/"))
loop.close()
if __name__ == '__main__':
search("quant", 5)一个完整的下载过程就OK了:
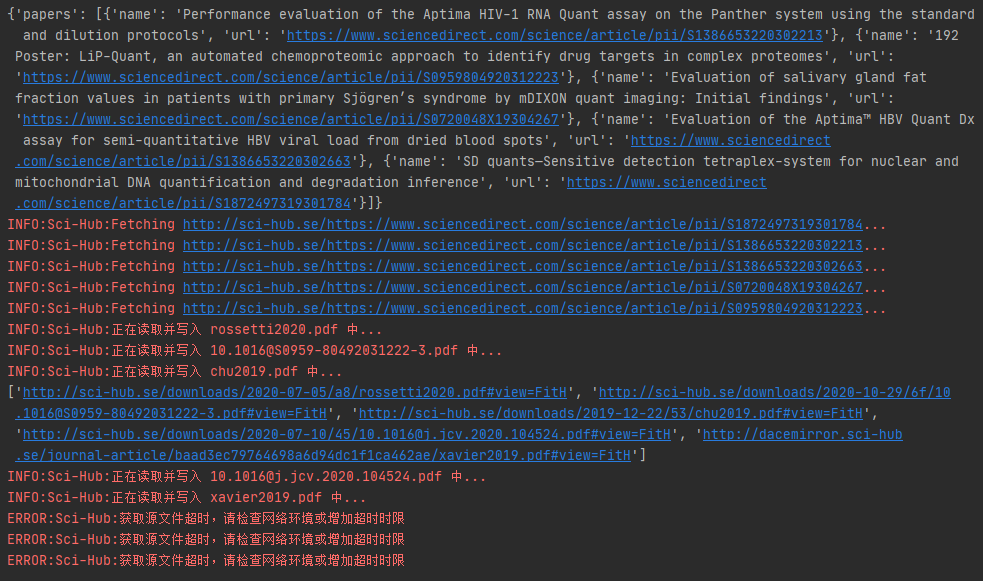
比以前的方式舒服太多太多了... 如果你要增加超时时间,请修改async_download函数中的 total=300,把这个请求总时间调高即可。
最新代码前往GitHub上下载:
https://github.com/Ckend/scihub-cn
或者从Python实用宝典公众号后台回复 scihub 下载。
6.工作原理
这个API的源代码其实非常好读懂
6.1、找到sci-hub目前可用的域名
首先它会在这个网址里找到sci-hub当前可用的域名,用于下载论文:
https://whereisscihub.now.sh/
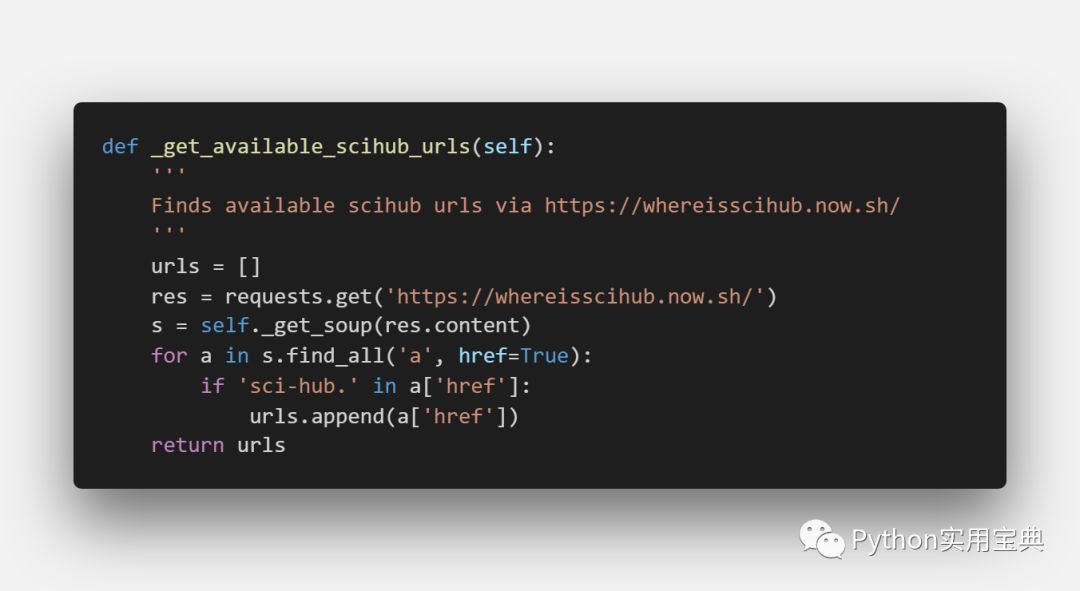
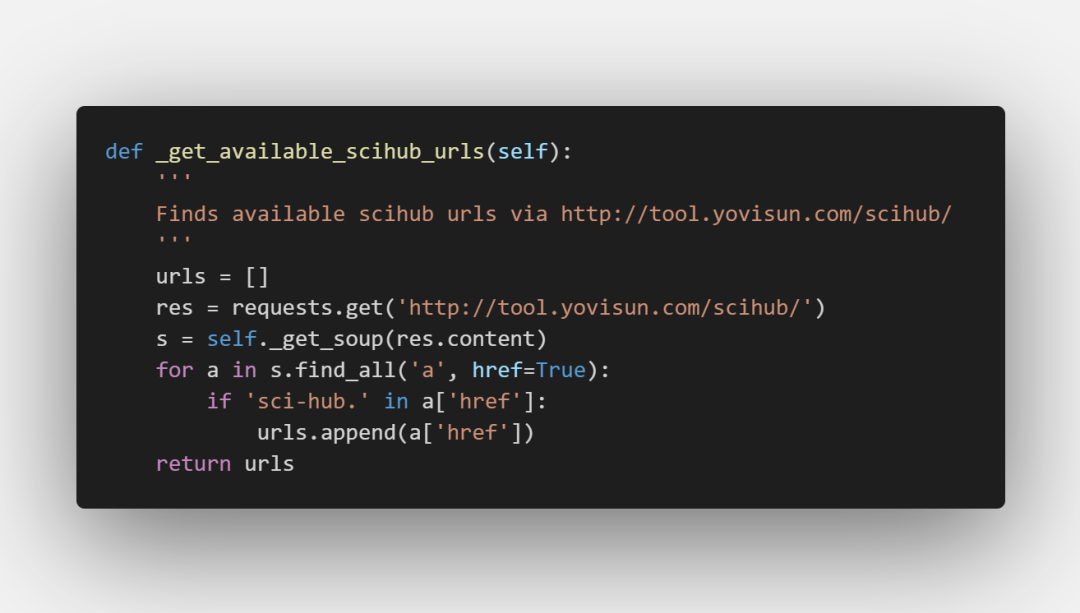
可惜的是,作者常年不维护,该地址已经失效了,我们就是在这里修改了该域名,使得项目得以重新正常运作:
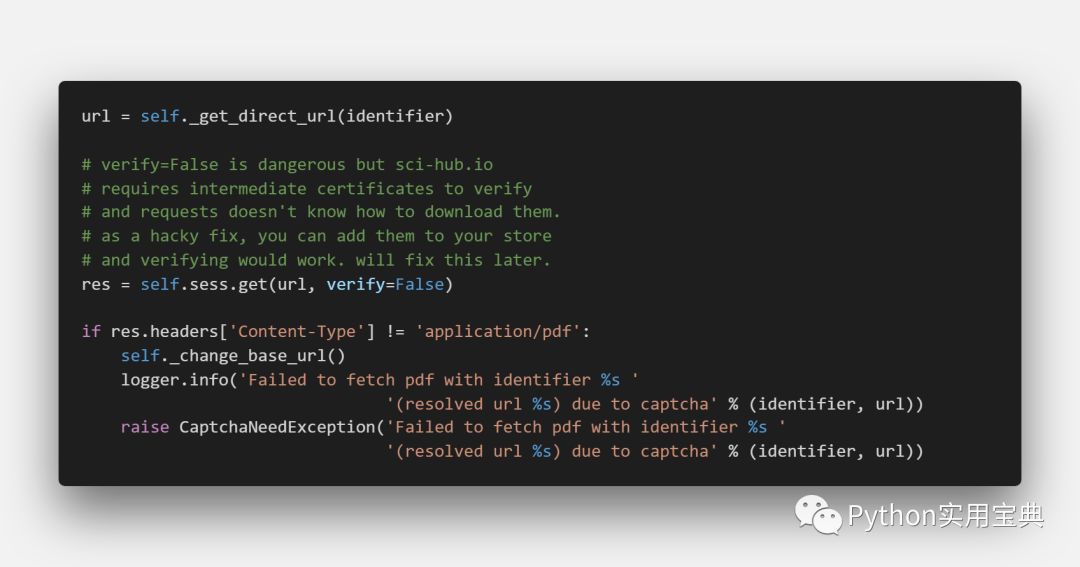
6.2、对用户输入的论文地址进行解析,找到相应论文
1. 如果用户输入的链接不是直接能下载的,则使用sci-hub进行下载
2. 如果scihub的网址无法使用则切换另一个网址使用,除非所有网址都无法使用。
3.值得注意的是,如果用户输入的是论文的关键词,我们将调用sciencedirect的接口,拿到论文地址,再使用scihub进行论文的下载。
6.3、下载
1. 拿到论文后,它保存到data变量中
2. 然后将data变量存储为文件即可
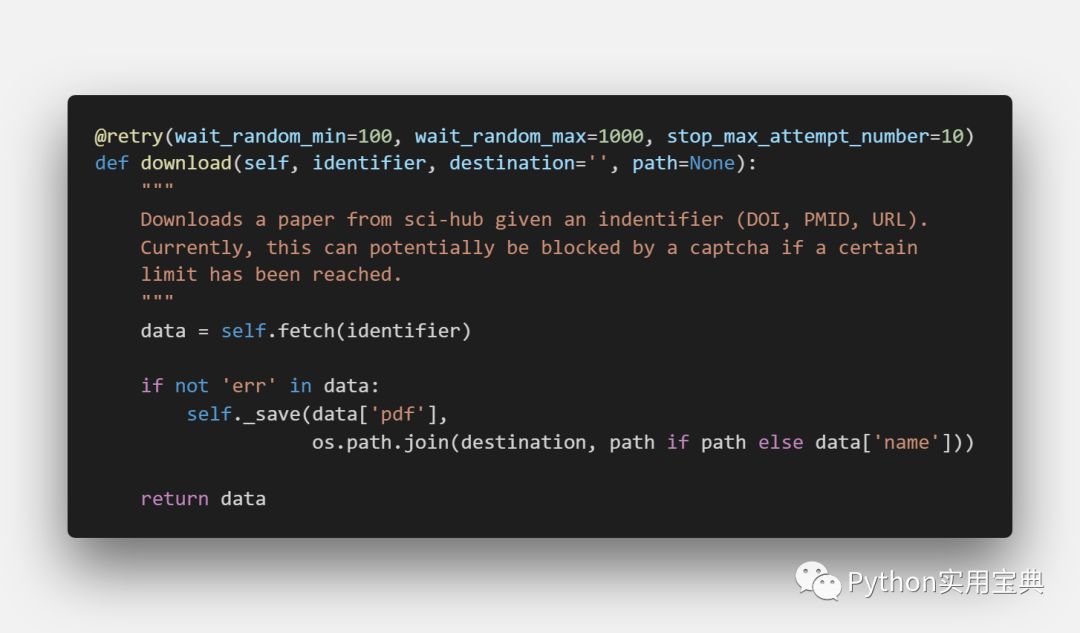
此外,代码用到了一个retry装饰器,这个装饰器可以用来进行错误重试,作者设定了重试次数为10次,每次重试最大等待时间不超过1秒。
希望大家能妥善使用好此工具,不要批量下载,否则一旦网站被封,学生党们又要哭了。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典