
Etcd Watch 居然会丢事件?
v1.27 的 K8s,在 kube-apiserver 的日志中会看到 "etcd event received with PrevKv=nil" 的字样,资源对象被删除后在 Etcd 中已经不存在了但在 Reflector store 中仍然存在,可以在 Informer 或者 watchCache 中看到对应的对象,依赖 Informer 的组件也不会感知到资源对象被删除,通过 List API 设置 RV="0" 去 kube-apiserver 的 watchCache 中获取的话也可以看到已经被删除的对象仍然存在。
根因先说结论,etcd watch 实现存在 bug,会导致客户端在使用 etcd client watch 时出现丢事件的现象。
Etcd Watchetcd 本身是客户端 + 服务端实现的 CS 架构,协议层通过 raft 算法保证了服务的强一致性和高可用性,同时 etcd 还提供了针对于存储数据的 watch 监听回调功能。所谓 watch 机制,指的是应用方可以针对存储在 etcd 中特定范围的数据创建 watch 监听器,在 watch 过程中,当对应数据发生变化时,etcd 会根据 watch 记录追溯到应用方,对变更事件进行同步。不清楚 etcd watch 流程的话,墙裂推荐先看小徐先生的编程世界公众号的两篇文章。
客户端
以下小节直接摘自《etcd watch 机制源码解析--客户端篇》
创建 watch 链路
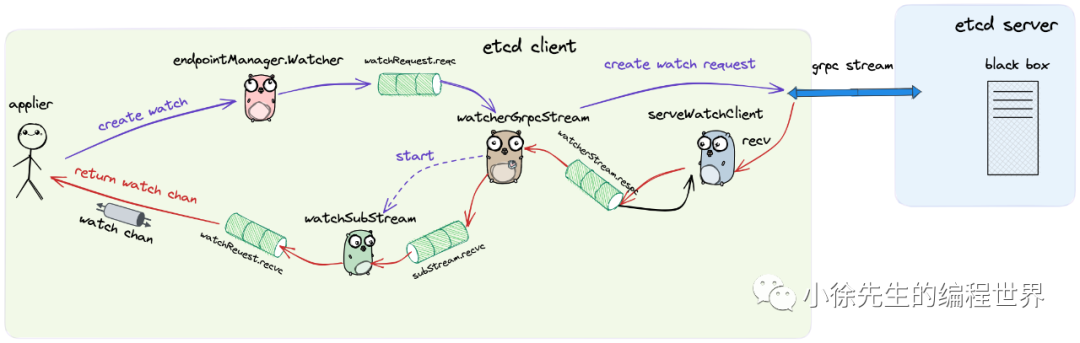
当应用方首次尝试通过 etcd 客户端发起创建 watch 的请求时,首先会进行 etcd 客户端与 etcd 服务端间通信架构的初始化,在之后的请求中可以统一复用. 在这部分准备工作中,客户端侧会创建并异步运行 grpc 长连接代理对象 watcherGrpcStream;同时会启动协程 serveWatchClient,持续轮询处理来自 etcd 服务端的响应.
在创建 watch 的主链路中,etcd 客户端会创建好一个 channel(称之为 upch) 提前返回给应用方,后续 watch 监听的数据发生变更时,应用方可以通过这个 channel 接收到 watch 回调事件.
接下来,etcd 客户端会通过 watcherGrpcStream 将创建 watch 的请求通过 grpc 长连接推送到 etcd 服务端,并且 watcherGrpcStream 会针对每个 watch 异步启动一个 watchSubStream 进行对应 watch 下回调事件的监听和处理.
watch 回调链路
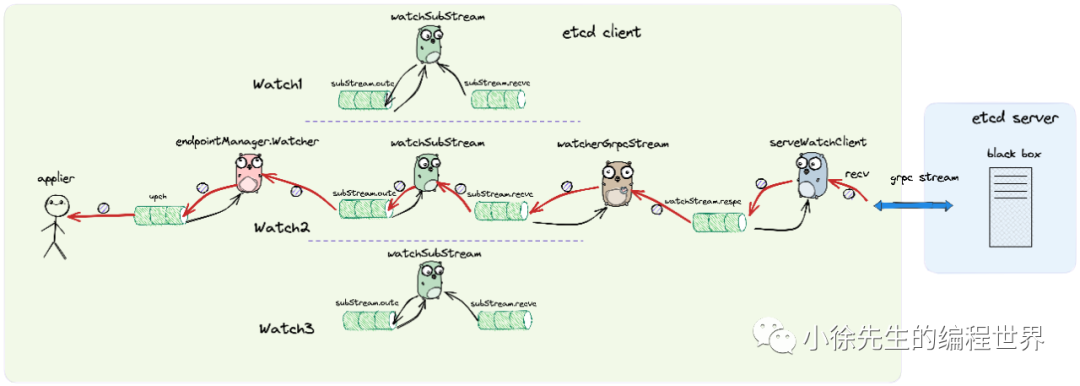
每当 watch 监听的数据发生变更后,etcd 服务端会通过 grpc 长连接将变更事件推送到 etcd 客户端.
etcd 客户端会通过常驻的 serveWatchClient 协程接收到 watch 回调事件,接下来 watcherGrpcStream 会根据回调事件所属的 watch 将其分配给对应的 watchSubStream,最终通过 endpointManager 的周转,并通过应用方持有的 upch,将回调事件推送到应用方的手中.
服务端
以下小节直接摘自《etcd watch 机制源码解析--服务端篇》
创建 watch
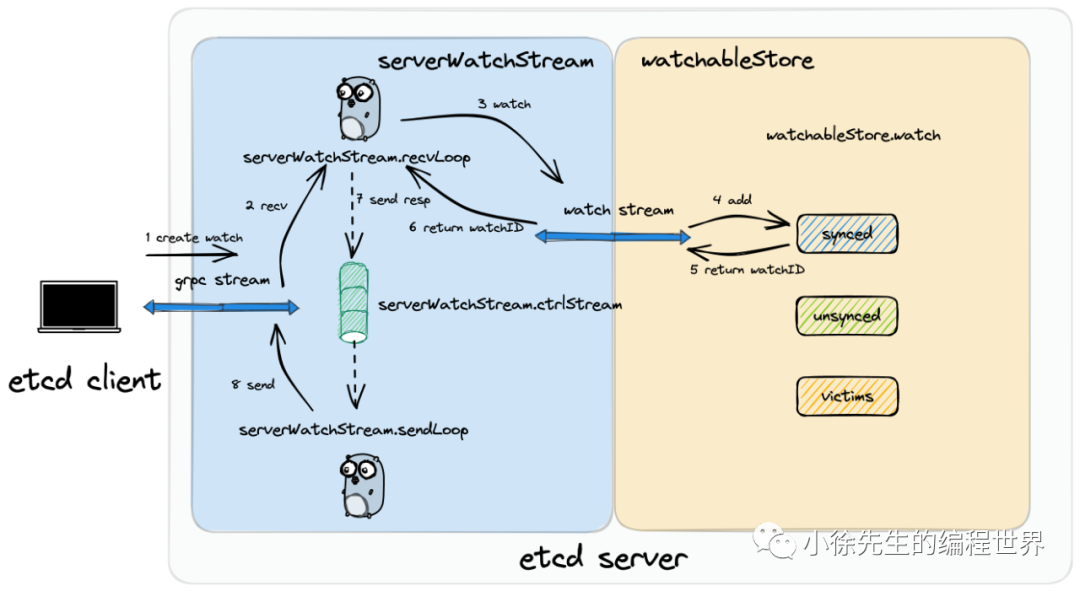
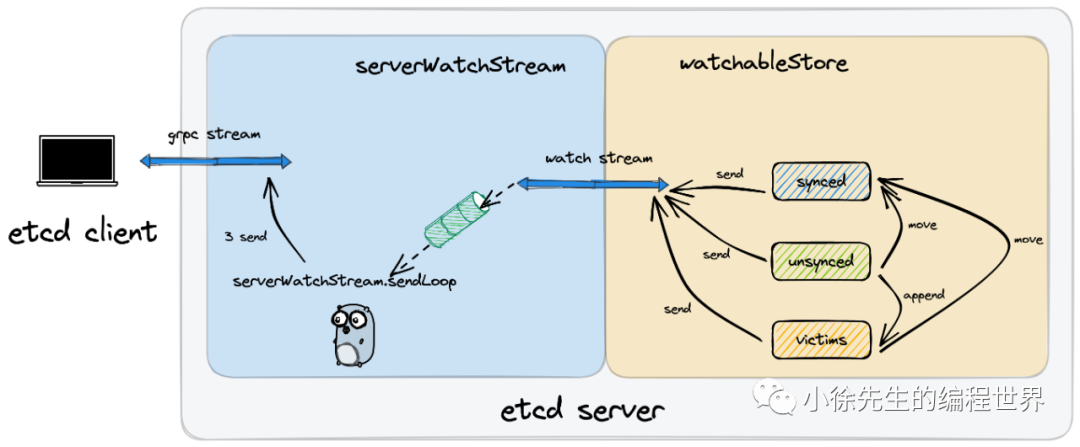
- 首先,etcd 客户端通过 grpc 长连接向 etcd 服务端发送创建 watch 请求
- serverWatchStream 中持续运行的读协程 recvLoop 通过 grpc 长连接接收到创建 watch 请求
- recvLoop 通过 watchStream,将创建 watch 的请求传递至底层的 watchableStore 模块
- watchableStore 根据新增的 watcher 是否需要回溯历史变更记录,会将 watcher 添加到 synced group 或者 unsynced group 当中存储
- revLoop 接收到来自 watchableStore 的响应后,会通过 ctrlStream 将响应数据发往写协程 sendLoop
- sendLoop 通过 ctrlStream 接收到响应后,通过 grpc 长连接将其发往 etcd 客户端
watch 回调
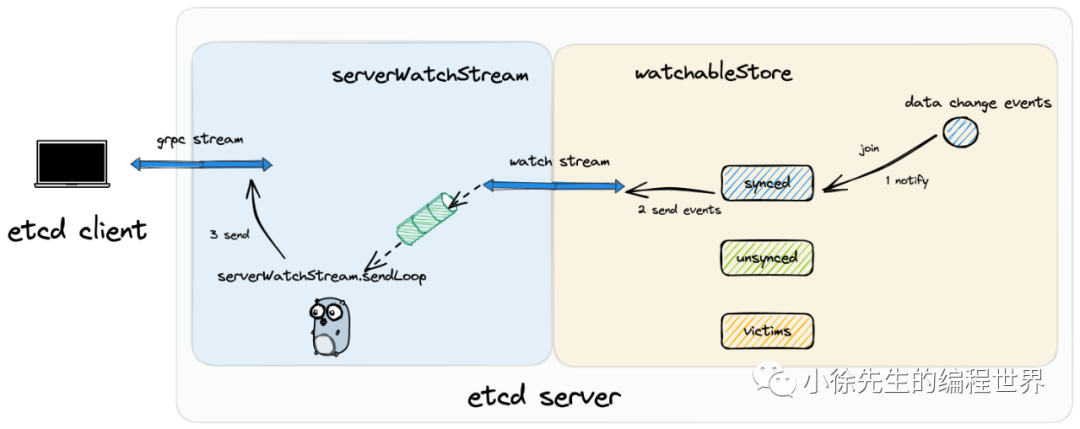
- 首先需要明确的是,不管是 etcd 客户端和 etcd 服务端节点建立的 grpc 长连接还是创建的 watcher 监听器,其生效范围都局限于某个特定的 etcd 服务端节点当中.
- 在一个 etcd 服务端节点发生写状态机数据的动作时,会执行 notify 动作,将变更的数据和 watchableStore synced group 中的 watcher 监听器进行 join,产生出一个批次的 watch 回调事件
- watchableStore 通过 watchStream 将 watch 回调事件发往上层的 serverWatchStream
- serverWatchStream 的 sendLoop 协程接收到 watch 回调事件,通过 grpc 长连接将其发送到 etcd 客户端
WatchableStore 刷新
watchableStore 模块的存储介质分为三部分,都是完全基于内存实现的存储,并且不同节点之间这部分数据内容是相互独立的:
- synced:用于存储 watcher 监听器. 存放着的 watcher 是监听数据无需回溯历史变更记录、倘若有新数据变更事件发生即可立即发起 watch 回调的监听器
- unsynced:同样用于存储 watcher 监听器. 存放着的 watch 是监听数据仍存在历史变更记录需要回溯,因此新数据变更事件发生时也无法立即发起回调的这部分监听器
- victims:用于临时存放一部分 watch 回调事件. 这部分回调事件是由于在通过 watchStream 发往上层途中发现 channel 容量不足,为避免 notify 协程陷入阻塞,而选择先将这部分变更事件追加到一个容量无上限的 victims 列表当中
创建连接
调用 clientv3.New 创建新的 client 时会最终调用 grpc.DialContext 函数创建一个 grpc connection 出来。
创建流
通过 client.Watch 发起一次 Watch 请求,如下示例代码
client, err := clientv3.New(clientv3.Config{
DialTimeout: 15 * time.Second,
DialKeepAliveTime: 15 * time.Second,
DialKeepAliveTimeout: 15 * time.Second,
DialOptions: []grpc.DialOption{
grpc.WithBlock(), // block until the underlying connection is up
// use chained interceptors so that the default (retry and backoff) interceptors are added.
// otherwise they will be overwritten by the metric interceptor.
//
// these optional interceptors will be placed after the default ones.
// which seems to be what we want as the metrics will be collected on each attempt (retry)
grpc.WithChainUnaryInterceptor(grpcprom.UnaryClientInterceptor),
grpc.WithChainStreamInterceptor(grpcprom.StreamClientInterceptor),
},
Endpoints: []string{"https://127.0.0.1:2379"},
TLS: tlsConfig,
})
if err != nil {
panic(err)
}
wc := client.Watch(clientv3.WithRequireLeader(context.TODO()), keyPrefix)
这里就是是利用已经建立起来的连接发起了一次 watch 请求。etcd 支持基于流的多路复用,与传统基于连接的多路复用不同。如下代码
// Watch posts a watch request to run() and waits for a new watcher channel
func (w *watcher) Watch(ctx context.Context, key string, opts ...OpOption) WatchChan {
ow := opWatch(key, opts...)
var filters []pb.WatchCreateRequest_FilterType
if ow.filterPut {
filters = append(filters, pb.WatchCreateRequest_NOPUT)
}
if ow.filterDelete {
filters = append(filters, pb.WatchCreateRequest_NODELETE)
}
wr := &watchRequest{
ctx: ctx,
createdNotify: ow.createdNotify,
key: string(ow.key),
end: string(ow.end),
rev: ow.rev,
progressNotify: ow.progressNotify,
fragment: ow.fragment,
filters: filters,
prevKV: ow.prevKV,
retc: make(chan chan WatchResponse, 1),
}
ok := false
ctxKey := streamKeyFromCtx(ctx)
var closeCh chan WatchResponse
for {
// find or allocate appropriate grpc watch stream
w.mu.Lock()
if w.streams == nil {
// closed
w.mu.Unlock()
ch := make(chan WatchResponse)
close(ch)
return ch
}
wgs := w.streams[ctxKey]
if wgs == nil {
wgs = w.newWatcherGrpcStream(ctx)
w.streams[ctxKey] = wgs
}
...
}
}
etcd 客户端会先通过 streamKeyFromCtx(ctx) 获取一个 key,一个 key 对应一个 grpc stream。kube-apiserver cacher 在访问 etcd 时的使用方式为每种资源类型有一个自己的 etcd client,也就是会为每种资源类型建立一个连接。但在 v1.27 中纠正了 RV="" 在 watch 请求中的语义,在这之前此类请求并不会穿透到 etcd,而在 v1.27 开始此类请求将直接穿透到 etcd。同一种资源类型的 watch 使用的是相同的 etcd client,且调用 client.Watch 时传入的 ctx 也一样,也就是同一种资源最终只对应一个 grpc stream。从上面介绍的服务端实现可以看出针对每个 grpc stream 会有一个对应的serverWatchStream 和 watchStream 对象。这就导致
- etcd 客户端:同一种 k8s 资源的 watch 请求使用了同一个 grpc stream
- etcd 服务端:同一种 k8s 资源的所有 watcher 共用了同一个 ch (来自 watchStream)
最终的结果就是 serverWatchStream 通过 sendLoop 不断的消费 ch 里面的数据并写回到 grpc stream,众多的 watcher 通过 notify 收到时间变更后将事件写到 ch 里面。相当于多个生产者,一个消费者,ch 是一个带缓冲区的 chan,长度 hard code 为 128。当 watcher 越来越多后,会出现生产速度大于消费速度,最终导致生产者 watcher 在写 ch 时阻塞从而被放入 unsynced 中。
丢事件
WatchableStore 会在后台启动两个 goroutine:syncWatchersLoop 和 syncVictimsLoop 定时的执行 watchers 同步,刷新的任务,对应上文 WatchableStore 刷新部分。
syncWatchersLoop
每 100ms 尝试从 unsynced 里面找到固定数量的 watch,尝试重新为这些 watcher 发送对应的 events。关键代码如下
func (wg *watcherGroup) chooseAll(curRev, compactRev int64) int64 {
minRev := int64(math.MaxInt64)
for w := range wg.watchers {
if w.minRev > curRev {
// after network partition, possibly choosing future revision watcher from restore operation
// with watch key "proxy-namespace__lostleader" and revision "math.MaxInt64 - 2"
// do not panic when such watcher had been moved from "synced" watcher during restore operation
if !w.restore {
panic(fmt.Errorf("watcher minimum revision %d should not exceed current revision %d", w.minRev, curRev))
}
// mark 'restore' done, since it's chosen
w.restore = false
}
if w.minRev < compactRev {
select {
case w.ch <- WatchResponse{WatchID: w.id, CompactRevision: compactRev}:
w.compacted = true
wg.delete(w)
default:
// retry next time
}
continue
}
if minRev > w.minRev {
minRev = w.minRev
}
}
return minRev
}
每个 watcher 对象维护了自己的 minRev 属性,代表这个 watcher 接受的 event 的最小 RV,用来避免 event 的重复发送,注意 minRev 并不代表已经发送成功的最大的 RV,不管发送成功与否,minRev 都会被更新,发送失败的 watcher 和 events 会被保存在 watcherBatch 结构中,最终保存到 victims 中。在 syncVictimsLoop 中处理 victims,继续尝试发给对应的 watcher 发送对应的 events,并根据结果同步 watcher 的状态。
上述有一段关键代码 if w.minRev < compactRev 代表 watcher 可接受的 event 的最小 Rev 比最新一次压缩后的 Rev 还要小,意味着从 minRev 到 compactRev 的 event 已经无法返回了,所以命中此逻辑之后会给 ch 发一个 WatchResponse 并且给 CompactionRevision 赋值,etcd 客户端收到这个 WatchResponse 之后会判断 CompactRevision>0 的话,代表 etcd server 端发生了压缩,无法继续正常返回数据,会返回一个 ErrCompacted 报错。
上述逻辑没有问题,考虑到了异常情况。现实是上述代码由于其他 bug 导致可能不会触发,如下
func (s *watchableStore) syncWatchers() int {
...
// in order to find key-value pairs from unsynced watchers, we need to
// find min revision index, and these revisions can be used to
// query the backend store of key-value pairs
curRev := s.store.currentRev
compactionRev := s.store.compactMainRev
wg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)
minBytes, maxBytes := newRevBytes(), newRevBytes()
revToBytes(revision{main: minRev}, minBytes)
revToBytes(revision{main: curRev + 1}, maxBytes)
// UnsafeRange returns keys and values. And in boltdb, keys are revisions.
// values are actual key-value pairs in backend.
tx := s.store.b.ReadTx()
tx.RLock()
revs, vs := tx.UnsafeRange(buckets.Key, minBytes, maxBytes, 0)
evs := kvsToEvents(s.store.lg, wg, revs, vs)
// Must unlock after kvsToEvents, because vs (come from boltdb memory) is not deep copy.
// We can only unlock after Unmarshal, which will do deep copy.
// Otherwise we will trigger SIGSEGV during boltdb re-mmap.
tx.RUnlock()
var victims watcherBatch
wb := newWatcherBatch(wg, evs)
for w := range wg.watchers {
w.minRev = curRev + 1
// send to ch
...
}
}
先通过 unsynced.choose 找到需要同步的 watchers 和其中最小的 minRev,获取 minRev 之后的所有 events,将对应的 events 发送给对应的 watcher。问题在 w.minRev = curRev + 1,执行到这里的时候有可能已经 w.minRev < compactedRev 了,也就是说 etcd server 端在 s.unsynced.choose 执行结束后,在遍历 wg.watchers 前进行了压缩的操作了。这里直接执行 w.minRev 的赋值操作将有可能导致 wminRev 不再小于 compactedRev,如果接下来的 send 由于仍然阻塞而没有执行成功,这个 watcher 会被放在 civtims 中,最后在同步 victims 后如果这个 watcher 发送成功一部分 event 但没有全部发送完,会被再次放入 unsynced 中,当再次走到 syncWathers 中,通过 chooseAll 去找 unsynced 的 watcher 时,就不会触发里面 w.minRev < compactRev 的逻辑,也就是说最终导致一个本该结束的 watcher 无法正常结束,继续从 curRev + 1 返回 events,compactedRev 到 curRev 的 events 就会丢失。
PrevKV == nil
经过上面分析,在 etcd server 端压缩后,可能出现无法正常结束异常 watcher 的情况,同时由于在 watherBatch 中保存了未发送成功的 watcher 和 events,所以 serverWatchStream 仍然可能会收到异常 watcher 的异常 event,如下
func (sws *serverWatchStream) sendLoop() {
...
for {
select {
case wresp, ok := <-sws.watchStream.Chan():
if !ok {
return
}
// TODO: evs is []mvccpb.Event type
// either return []*mvccpb.Event from the mvcc package
// or define protocol buffer with []mvccpb.Event.
evs := wresp.Events
events := make([]*mvccpb.Event, len(evs))
sws.mu.RLock()
needPrevKV := sws.prevKV[wresp.WatchID]
sws.mu.RUnlock()
for i := range evs {
events[i] = &evs[i]
if needPrevKV && !IsCreateEvent(evs[i]) {
opt := mvcc.RangeOptions{Rev: evs[i].Kv.ModRevision - 1}
r, err := sws.watchable.Range(context.TODO(), evs[i].Kv.Key, nil, opt)
if err == nil && len(r.KVs) != 0 {
events[i].PrevKv = &(r.KVs[0])
}
}
}
...
}
调用 Range 方法寻找此 event 的上一个版本,由于中间进行了压缩,找不到了,会返回如下报错:mvcc: required revision has been compacted,但是这里只判断了正常情况下去给 event.PrevKV 赋值,未考虑异常情况,最终在 kube-apiserver 侧就会看到 "etcd event received with PrevKv=nil" 的报错。这是一个比较低级的问题,golang 任何返回 err 的地方都应该去判断 err 是否为 nil,这里居然没有判断。
问题修复
判断 if w.minRev < compectedRev,则直接跳过下面所有逻辑的执行,等待下一次 chooseAll 执行时返回给客户端带了 CompactRevision 的 WatchResponse,参考 Fix watch event loss #17555[1],已经合入 master,并 backport 回了 release-3.4 和 release-3.5 上。
总结Etcd 侧丢事件的问题虽然修复了,但由于基于流的复用,仍然存在事件处理延迟的问题,以及阻塞时 etcd server 内存暴涨的问题,关于后者,有另外一个 PR 在解决此问题,后续会再安排一篇专门解释这个问题。对于前者,在前一篇中介绍了 k8s 侧已经通过给 cacher 发起的 watch 请求设置特定的 ctx,最终会和直接访问 etcd 的请求区分开,别分使用两个不同的 grpc stream。这样就解决了 kube-apiserver cache 因为 etcd 丢事件导致的问题,但那些 RV="" 的 watch 请求之间仍然共用一个 grpc stream,虽然不会丢事件了,但这种请求多了之后仍然存在 event 接收延迟的风险。
对于众多的 k8s 用户来说:
- 如果使用的是 v1.25(不包括) 之前的版本,那么无需担心此问题,因为 k8s 侧有兜底,即使不升级 etcd 也可以完全避免丢事件的问题;
- 如果使用的是 v1.25 ~ v1.27(不包括)的版本,k8s 侧兜底逻辑失效,存在丢事件的风险,但由于这些版本的 watch 请求不会穿透到 etcd,理论上丢事件发生的概率会非常低,可以忽略;
- 如果使用的是 v1.27 到 v1.30 (不包括)的 k8s 版本,墙裂建议升级 etcd,使用修复此问题的版本;
- 如果使用的是 v1.30 及之后的版本(应该不会有,太新了),为 kube-apiserver 关闭这个 featuregate
WatchFromStorageWithoutResourceVersion
如果对上述内容有任何疑问,欢迎加笔者微信讨论 参考资料 [1] pr#17555: https://github.com/etcd-io/etcd/pull/17555