
说说Kafka控制器事件处理全流程
前言
今天来说说 Kafka控制器,即 Kafka Controller。
这篇文章我分为两部分,第一部分就是直接图文来说清整个 Kafka 控制器事件处理全流程,然后再通过Controller选举流程进行一波源码分析,再来走一遍处理全流程。
正文
在深入源码之前我们得先搞明白 Controller是什么?它有什么用?这样在看源码的时候才能有的放矢。
Controller是核心组件,它的作用是管理和协调整个Kafka集群。
具体管理和协调什么呢?
主题的管理,创建和删除主题; 分区管理,增加或重分配分区; 分区 Leader选举;监听 Broker相关变化,即Broker新增、关闭等;元数据管理,向其他 Broker提供元数据服务;
为什么需要Controller?
我个人理解:凡是管理或者协调某样东西,都需要有个Leader,由他来把控全局,管理内部,对接外部,咱们就跟着Leader干就完事了。这其实对外也是好的,外部不需要和我们整体沟通,他只要和一个决策者交流,效率更高。
再来看看朱大是怎么说的,以下内容来自《深入理解Kafka:核心设计与实践原理》。
在Kafka的早期版本中,并没有采用 Kafka Controller 这样一概念来对分区和副本的状态进行管理,而是依赖于 ZooKeeper,每个 broker都会在 ZooKeeper 上为分区和副本注册大量的监听器(Watcher)。
当分区或副本状态变化时,会唤醒很多不必要的监听器,这种严重依赖 ZooKeeper 的设计会有脑裂、羊群效应,以及造成 ZooKeeper 过载的隐患。
在目前的新版本的设计中,只有 Kafka Controller 在 ZooKeeper 上注册相应的监听器,其他的 broker 极少需要再监听 ZooKeeper 中的数据变化,这样省去了很多不必要的麻烦。
简单说下ZooKeeper
了解了 Controller的作用之后我们还需要在简单的了解下ZooKeeper,因为Controller是极度依赖ZooKeeper的。(不过社区准备移除ZooKeeper,文末再提一下)。
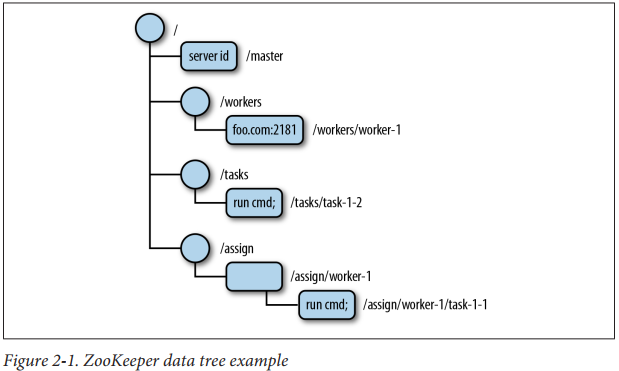
ZooKeeper是一个开源的分布式协调服务框架,最常用来作为注册中心等。ZooKeeper的数据模型就像文件系统一样,以根目录 "/" 开始,结构上的每个节点称为znode,可以存储一些信息。节点分为持久节点和临时节点,临时节点会随着会话结束而自动被删除。
并且有Watcher功能,节点自身数据变更、节点新增、节点删除、子节点数量变更都可以通过变更监听器通知客户端。
Controller是如何依赖ZooKeeper的
每个Broker在启动时会尝试向ZooKeeper注册/controller节点来竞选控制器,第一个创建/controller节点的Broker会被指定为控制器。这就是是控制器的选举。
/controller节点是个临时节点,其他Broker会监听着此节点,当/controller节点所在的Broker宕机之后,会话就结束了,此节点就被移除。其他Broker伺机而动,都来争当控制器,还是第一个创建/controller节点的Broker被指定为控制器。这就是控制器故障转移,即Failover。
当然还包括各种节点的监听,例如主题的增减等,都通过Watcher功能,来实现相关的监听,进行对应的处理。
Controller在初始化的时候会从ZooKeeper拉取集群元数据信息,保存在自己的缓存中,然后通过向集群其他Broker发送请求的方式将数据同步给对方。
Controller 底层事件模型
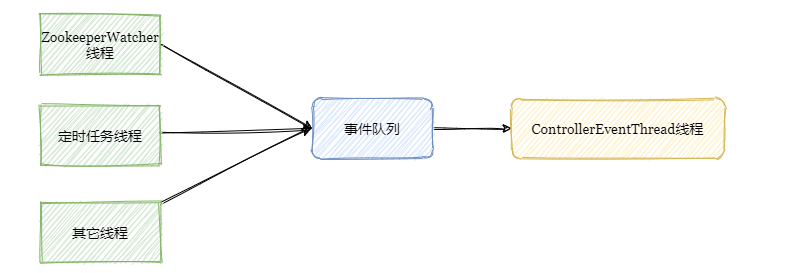
不管是监听Watcher的ZooKeeperWatcher线程,还是定时任务线程亦或是其他线程都需要访问或更新Controller从集群拉取的元数据。多线程 + 数据竞争 = 线程不安全。因此需要加锁来保证线程安全。
一开始Kafka就是用大量的锁来保证线程间的同步,各种加锁使得性能下降,并且多线程加锁的方式使得代码复杂度急剧上升,一不小心就会出各种问题,bug难修复。
因此在0.11版本之后将多线程并发访问改成了单线程事件队列模式。将涉及到共享数据竞争相关方面的访问抽象成事件,将事件塞入阻塞队列中,然后单线程处理。
也就是说其它线程还是在的,只是把涉及共享数据的操作封装成事件由专属线程处理。
先小结一下
到这我们已经清楚了Controller主要用来管理和协调集群,具体是通过ZooKeeper临时节点和Watcher机制来监控集群的变化(当然还有来自定时任务或其他线程的事件驱动),更新集群的元数据,并且通知集群中的其他Broker进行相关的操作(这部分下文会讲)。
而由于集群元数据会有并发修改问题,因此将操作抽象成事件,由阻塞队列和单线程处理来替换之前的多线程处理,降低代码的复杂度,提升代码的可维护性和性能。
接下来我们再讲讲Controller通知集群中的其他Broker的相关操作。
Controller的请求发送
Controller从ZooKeeper那儿得到变更通知之后,需要告知集群中的Broker(包括它自身)做相应的处理。
Controller只会给集群的Broker发送三种请求:分别是 LeaderAndIsrRequest、StopReplicaRequest和 UpdateMetadataRequest
LeaderAndIsrRequest
告知Broker主题相关分区Leader和ISR副本都在哪些 Broker上。
StopReplicaRequest
告知Broker停止相关副本操作,用于删除主题场景或分区副本迁移场景。
UpdateMetadataRequest
更新Broker上的元数据。
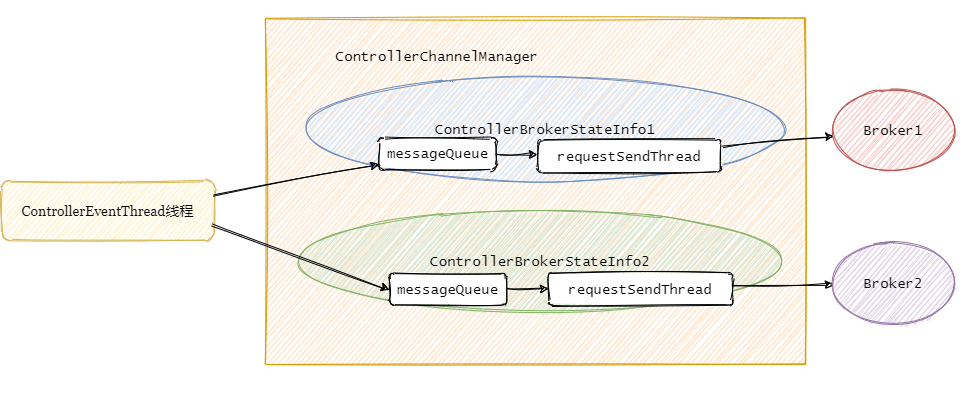
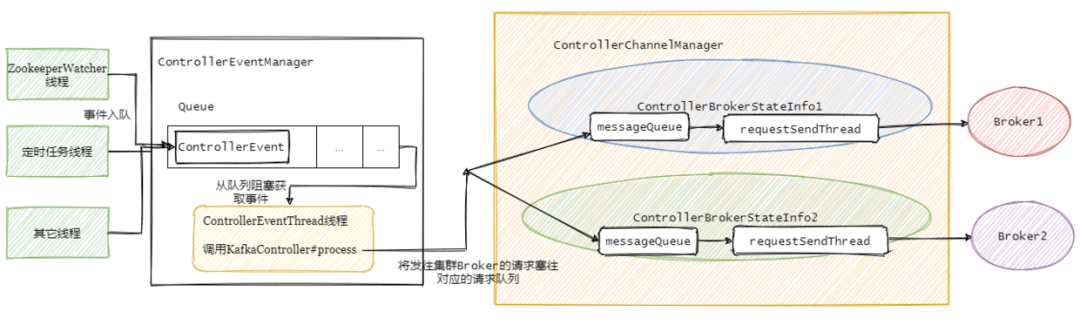
Controller事件处理线程会把事件封装成对应的请求,然后将请求写入对应的Broker的请求阻塞队列,然后RequestSendThread不断从阻塞队列中获取待发送的请求。
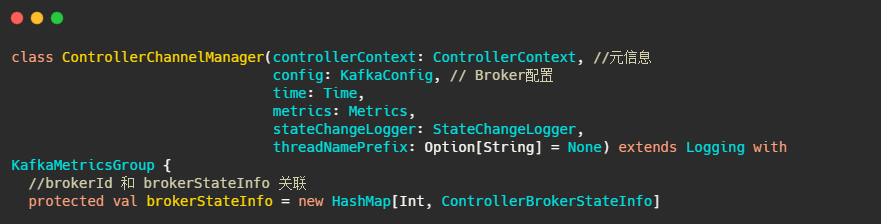
先解释下controllerBrokerStateInfo,它就是个 POJO类,可以理解为集群每个broker对应一个controllerBrokerStateInfo.
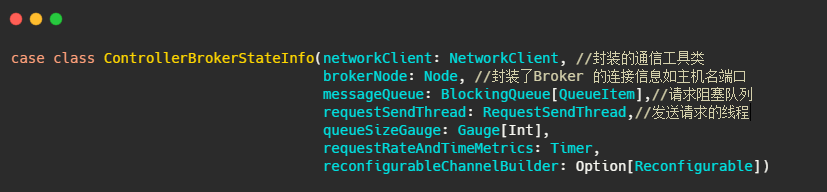
然后再看下ControllerChannelManager,从名字可以看出它管理Controller和集群Broker之间的连接,并为每个Broker创建一个RequestSendThread线程。
再小结一下
接着上个小结,事件处理线程将事件队列里面的事件处理之后再进行对应的请求封装,塞入需要通知的集群Broker对应的阻塞队列中,然后由每个Broker专属的requestSendThread发送请求至对应的Broker。
总的步骤如下图:
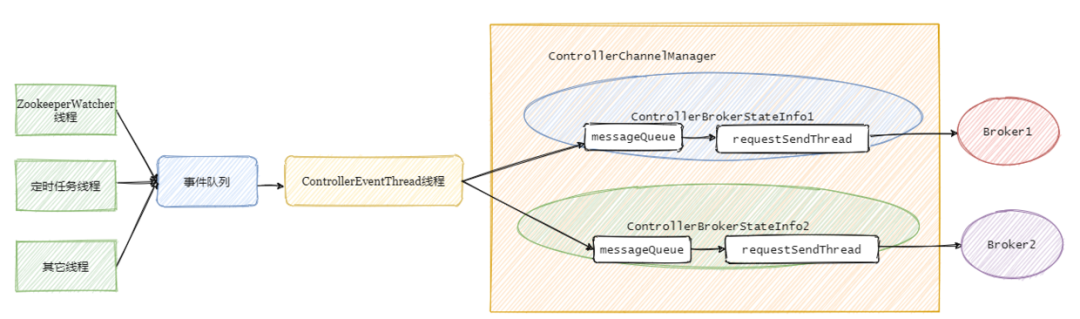
现在应该已经清楚Controller大概是如何运作的,整体看起来还是生产者-消费者模型。
接下来就进入源码环节。
Controller选举流程源码分析
事件处理的流程都是一样的,只是具体处理的事件逻辑不同,我们从Controller选举入手,来走一遍处理流程。
ControllerChangeHandler
选举会触发此handler,可以看到直接往ControllerEventManager的事件队列里塞。
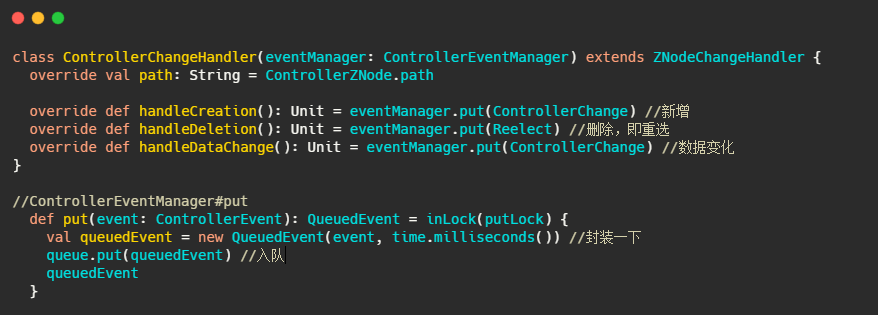
这个QueueEvent和ControllerEventManager,我们先来看看是啥。不过在此之前先了解下ControllerEvent和ControllerEventProcessor。
ControllerEvent:事件

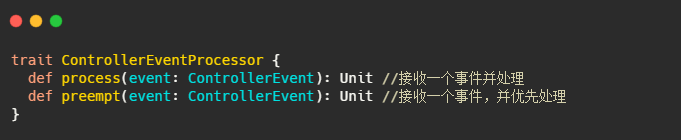
ControllerEventProcessor :事件处理接口
此接口的唯一实现类是 KafkaController。
ControllerEventManager:事件处理器
此类主要用来管理事件处理线程和事件队列。
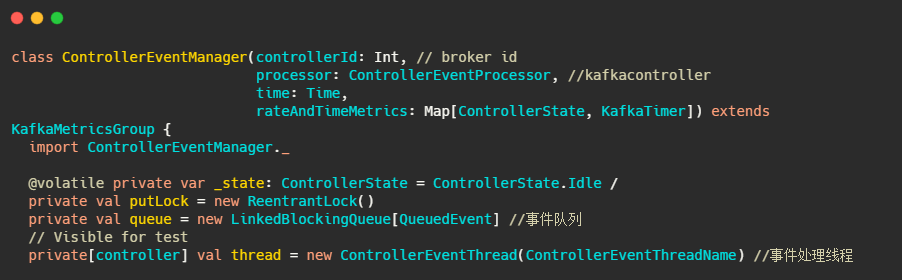
QueuedEvent:封装了ControllerEvent的类
主要是记录了下入队时间,并且提供了事件需要调用的方法。
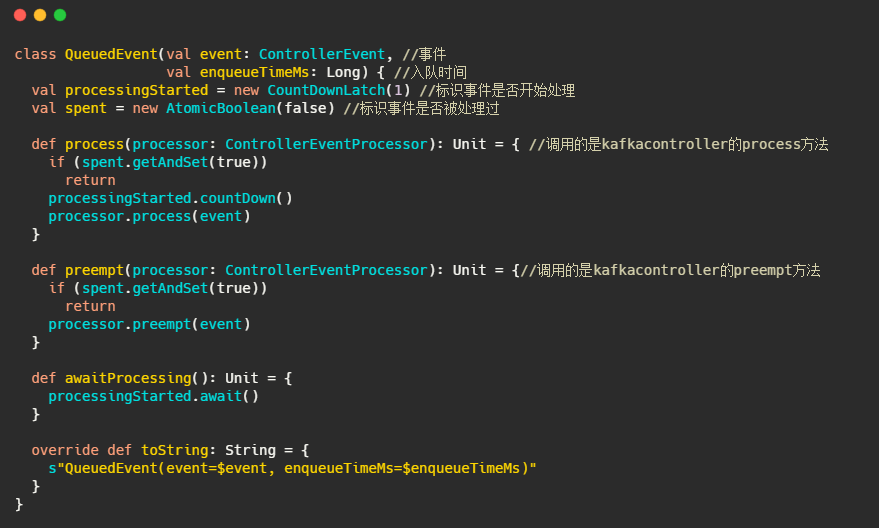
ControllerEventThread:事件处理线程
整体而言还是很简单的,从队列拿事件,然后处理。
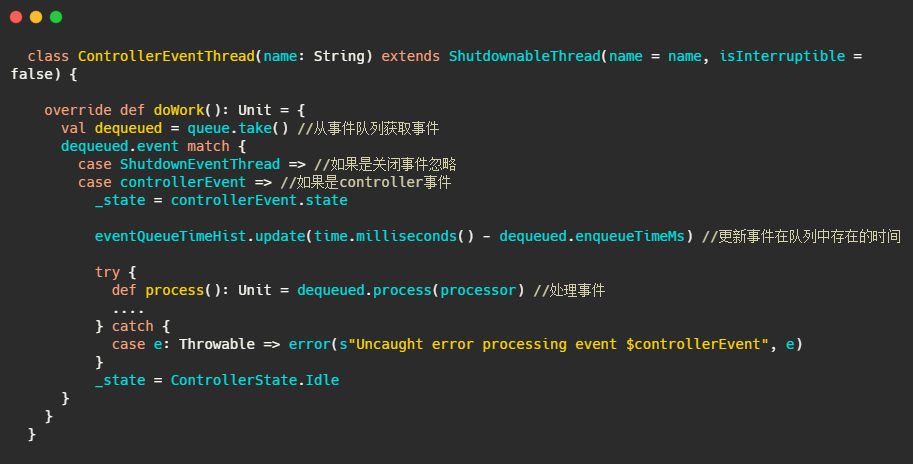
KafkaController#process
就是个switch,根据事件调用对应的processXXXX方法。
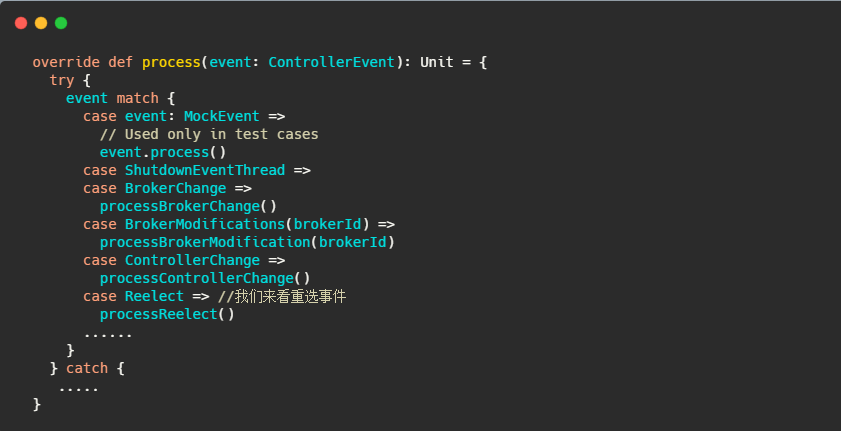
来关注下controller 重选事件
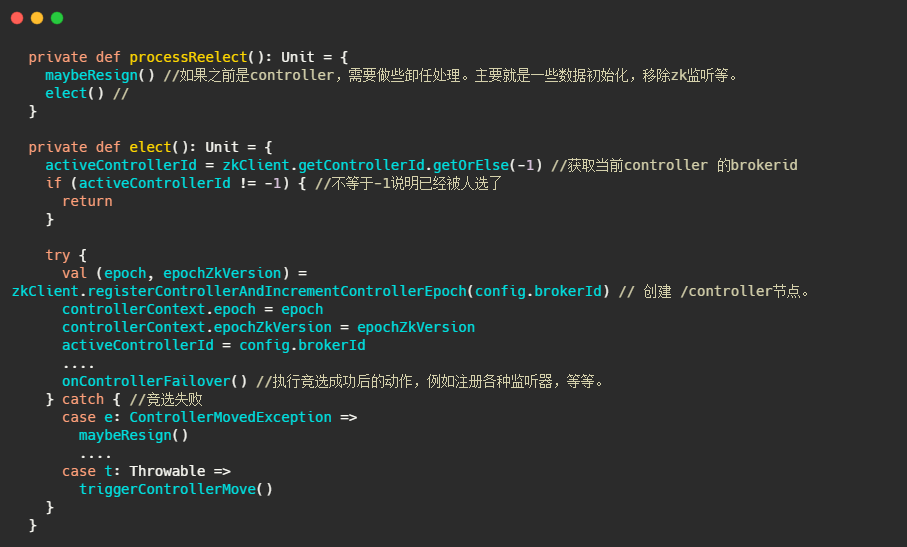
然后在onControllerFailover里面会调用sendUpdateMetadataRequest方法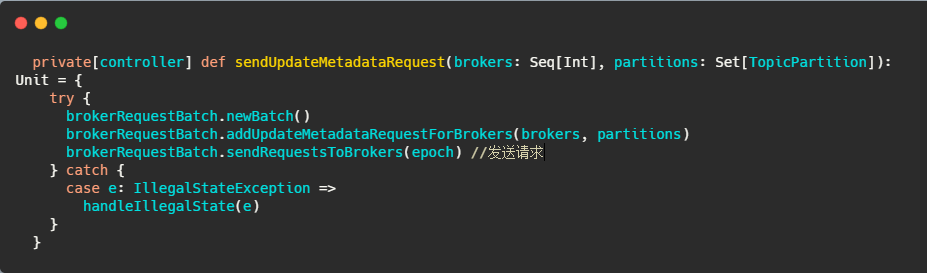
中间省略调用,内容太多了,不是重点,到后来调用ControllerBrokerRequestBatch#sendRequest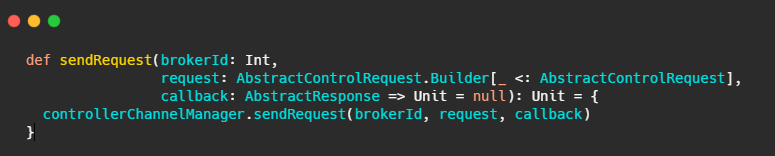
最后还是调用了controllerChannelManager#sendRequest.

然后 RequestSendThread#doWork,不断从请求队列里拿请求,发送请求。
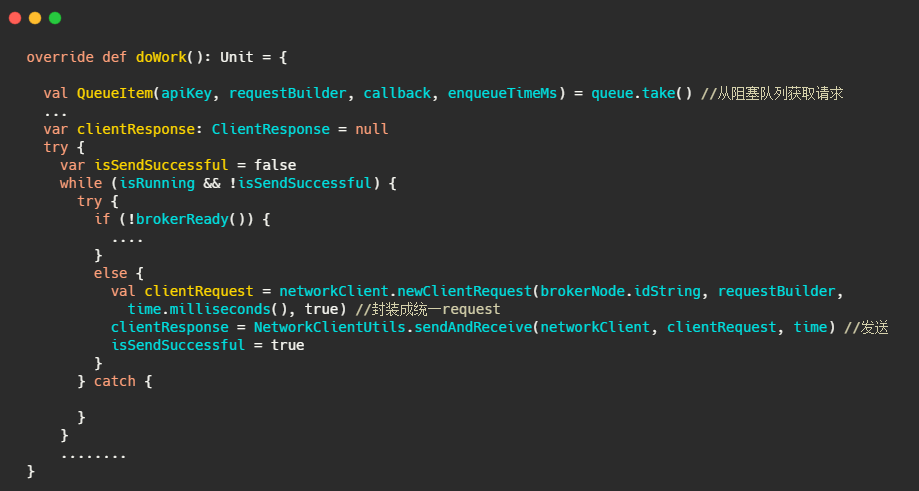
一个环节完成了!我们来看下整体流程图
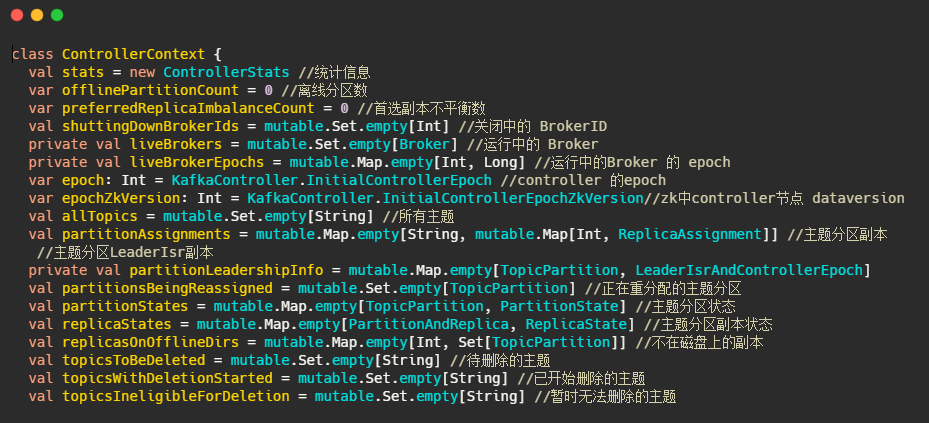
最后我们来看下元数据到底有啥和KafkaController的一些字段。
ControllerContext:元数据
主要有运行中的Broker、所有主题信息、主题分区副本信息等。
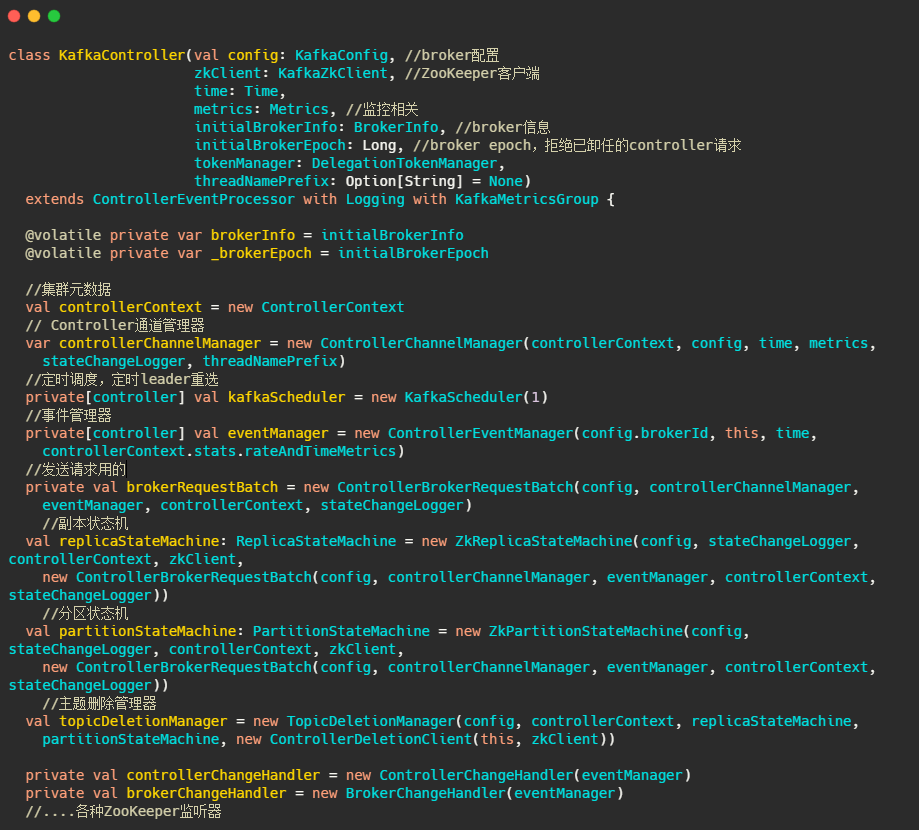
KafkaController
基本上关键的字段都解释了,关于状态机那一块篇幅有限,之后再说。
最后
整体的流程就是将Controller相关操作都封装成一个个事件,然后将事件入队,由一个事件处理线程来处理,保证数据的安全(从这也可以看出,不是多线程就是好,有利有弊最终还是看场景)。
最后在通知集群中Broker的过程是每个Broker配备一个发送线程,因为发送是同步的,因此每个Broker线程隔离可以防止某个Broker阻塞而导致整体都阻塞的情况。
前面有说到Kafka Controller 强依赖 ZooKeeper。但是现在社区打算移除 ZooKeeper,因为ZooKeeper不适合频繁写,并且是CP的。而且用Kafka还需要维护ZooKeeper集群,提升了系统的复杂度和运维难度,降低了系统的稳定性。
像位移信息,已经通过内部主题的方式保存,绕开了ZooKeeper。
社区打算通过类 Raft 共识算法来选举Controller,并且把元数据存储在 Log 中的方式来做。
往期推荐:
看完本文有收获?点赞、分享是最大的支持
明天见(。・ω・。)ノ♡