LSTM要过气了,用什么来取代?

大数据文摘出品
来源:medium
编译:Hippo、coolboy
LSTM(The Long Short-Term Memory,长短期记忆网络)已成为深度学习的主流之一,并作为循环神经网络(RNN,recurrent neural networks)的一种更好的变体而被广泛应用。但是随着机器学习研究的加速,各种方法的更迭越来越快,LSTM似乎已经开始变得落伍。
让我们退后几步,从0到1来探索语言建模的发展历程。
从根本上讲,像其他任何监督机器学习问题一样,语言建模的目标是预测给定文档d的输出结果y。该文档d必须以数字形式表示,使其可以通过机器学习算法进行处理。
将文档表示为数字的最初解决方案是单词袋(BoW)。每个单词在向量中占一个维度,每个值代表单词在文档中出现的次数。
但是,这种方法没有考虑单词的排序,而这很重要(比如:“我为工作而生”,“我为生活而工作”)。
为了解决这个问题,人们引入了n-grams概念,即n个单词的序列,其中每个元素表示某个单词组合。如果我们的数据集中有10,000个单词,并且我们要存储二元组,则需要存储10,000²个唯一组合。对于任何足够完善的建模,我们可能都需要三元组甚至四元组,而它们分别将词汇量提高了一个幂次。
显然,这个解决方案所涉及的矢量过程过于稀疏和庞大,无法捕捉语言本质,稍微复杂的语言任务都无法用n-grams和BoW来处理。那么如何解决呢?这里就要用到循环神经网络(RNN)了。
高维、稀疏矢量化解决方案尝试将整个文档一次性输入模型当中。与此不同,循环神经网络的运作机制更加靠近文档的序列特征。RNN可以表示为递归函数,其中A表示对应每个时间点的转换函数,h表示隐藏层状态的集合,x表示数据集合。
每个时间点都是在前一个时间点的知识的基础上,通过对前一个输出引用相同的函数来创建的。当RNN处于“展开状态”时,我们可以了解到各个时间的输入如何利用之前积累的知识反馈到模型中。
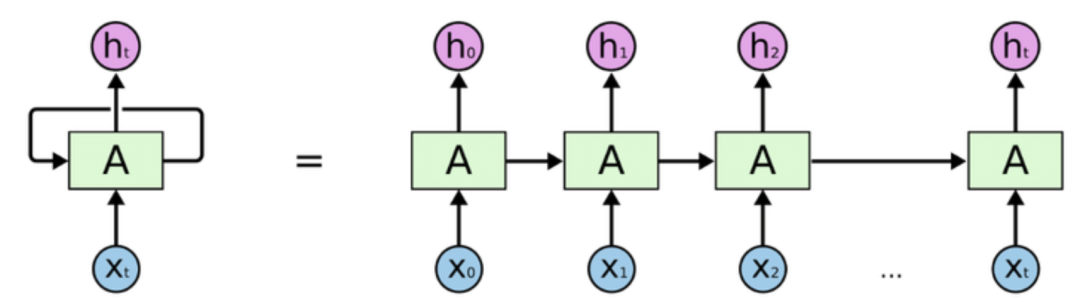
由于RNN对每个输入都引用相同的函数,因此它的另一个优势是能够处理可变长度的输入。对每个时间点使用相同函数的原理,可以视为对每个时间点应用通用语言(或通用时序)的规则。
RNN的递归思路有很大的优势,但同时也产生了一些问题。将我们对RNN的递归定义简单地扩展到第四个隐藏状态,我们看到A函数被多次引用。
A(x)实际上只是乘以权重矩阵并加到偏差矩阵上。当然,要进行很大的简化,在10个时间点之后,初始输入x₀实际上要乘以w¹⁰,其中w是权重矩阵。正如任何计算所得出的那样,将数字取幂会返回极端结果:
0.3¹⁰= 0.000005
0.5¹⁰= 0.0009
1.5¹⁰= 57.7
1.7¹⁰= 201.6
这引起很多问题。权重矩阵将导致值趋向于零(递减)、无穷大或负无穷大(激增)。因此,RNN受梯度递减(或激增)问题的困扰。权重更新时,这不仅会导致计算问题,还意味着知识的“遗忘”:模型会“遗忘”仅仅几步之前的输入,因为这些输入已经被递归乘法所掩盖或放大而导致无法理解。
因此,当使用RNN生成文本时,您可能会看到无限循环:
我走在大街上,走在大街上,走在大街上,走在大街上,走在大街上,…
当神经网络生成第二轮“走”时,模型已经忘记了上一次曾经说过。通过它的简单机制,它认为在先前的输入为“ 在大街上…”的情况下,下一个输出应为“ 走”。因为关注范围太小,所以循环不断持续。
解决方法:LSTM网络于1997年首次推出(哇!20多年前),但直到最近才收到广泛青睐,当今快速发展的计算资源使这项发现变得更加实用。
它仍然是一个循环网络,但是对输入进行了更加精确的转换。每个单元的输入都通过复杂的操作进行管理,产生两个输出,可以将其视为“长期记忆”(下图中贯穿整个单元的顶行)和“短期记忆”(下图中底部输出)。
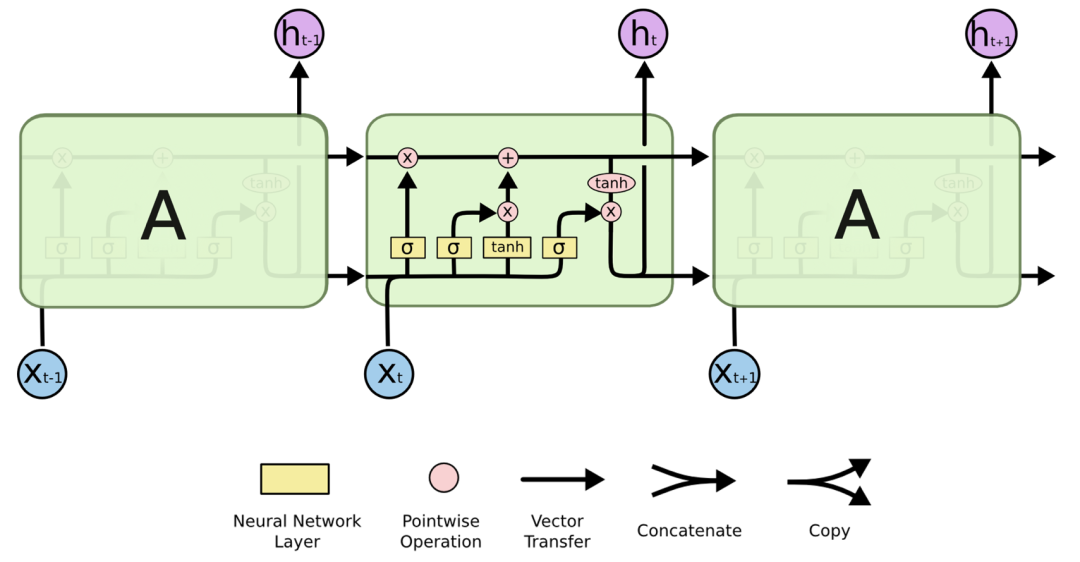
资料来源:Chris Olah
通过长期记忆通道的向量可以通过整个链路而不会受到任何干扰。只有门(粉红色圆点)可以阻止或添加信息。因此,只要神经网络做出选择,它可以保留从任意数量的单元中发现有用的数据。
长期信息流的添加极大地扩展了神经网络的关注范围。它可以访问很早以前的单元状态,同时也可以学习不久前的有用信息,从而使其能够联系上下文语境(多数人际交流的关键属性)。
很长一段时间LSTM都运作良好。它可以在较短的文本长度上很好地实现文字生成,并且克服了很多早期自然语言处理发展过程中遇到的问题,不局限于对单一单词的理解,而是对文档进行更全面的深度理解。
但是,LSTM网络也有缺点。它仍然是一个循环网络,因此,如果输入序列具有1000个字符,则LSTM单元被调用1000次,即长梯度路径。虽然增加一个长期记忆通道会有所帮助,但是它可以容纳的存储空间是有限的。
另外,由于LSTM本质上是递归的(要找到当前状态,您需要找到先前的状态),因此不能进行并行训练。
也许更紧迫的是,迁移学习(transfer learning)在LSTM(或RNN)上不能很好地运作。深度卷积神经网络之所以得到普及,部分原因是像Inception之类的预训练模型可以轻松下载和微调。在已知任务通用规则的前提下开始训练,任务可以变得更加容易和可行。
有时,经过预训练的LSTM可以成功迁移,但这没有成为普遍做法是有原因的。因为每段文字都有自己独特的风格。这与图像不同,图像几乎总是遵循某种严格的通用规则(带有阴影和边缘),而文本的结构并不那么显而易见,而且更加多变。
是的,有一些基本的语法规则可以支持文本框架,但是它不如图像严格。最重要的是,不同的语言表达形式有不同的语法规则集,比如不同的诗歌形式、不同的方言(莎士比亚和古英语)、不同的用例(Twitter上的文字语言,即兴演讲的书面版本)。因此,从Wikipedia上经过预训练的LSTM开始,似乎并不比从头学习数据集要容易很多。
除了预训练的嵌入之外,LSTM在遇到更苛刻的现代问题时也受到限制,例如跨多种语言的机器翻译、与人工文本无法区分的机器文本。为此,一个新的框架被越来越多的用在这些更具挑战的课题上:transformer(出自google,被广泛应用于NLP的各项任务中)。
该框架最初在论文《Attention is All You Need》中发布以解决机器翻译问题,框架的体系结构非常复杂。但是,它最核心的概念是所谓的“注意力(attention)”。

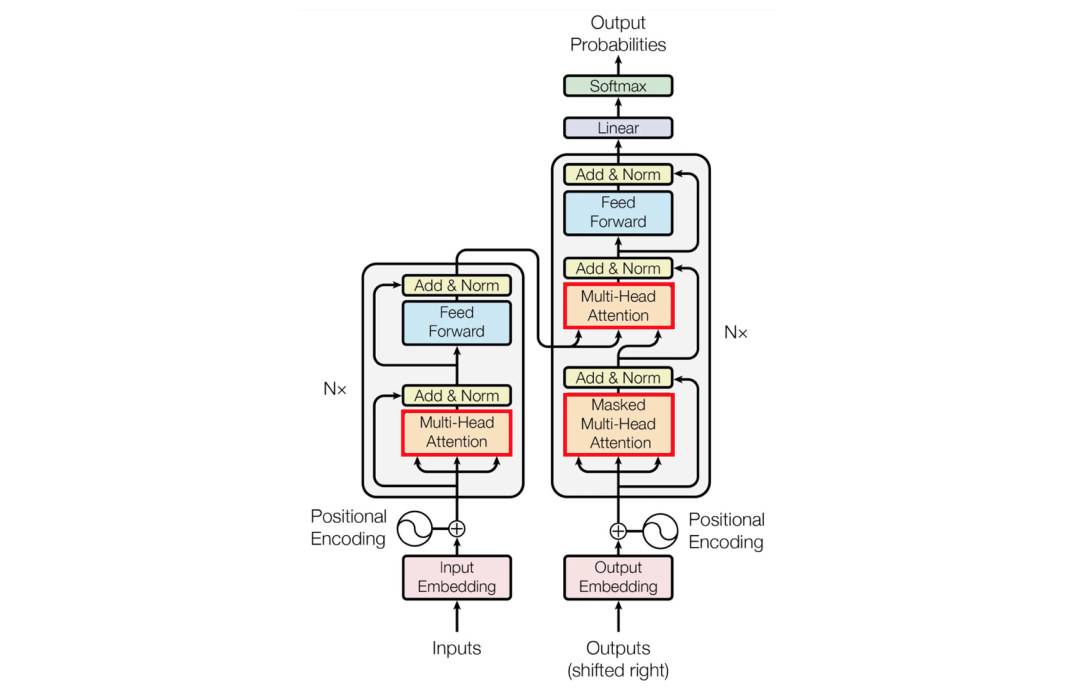
资料来源:Hong Jing
本文的前面我们讨论了注意力跨度,即递归神经网络可以回顾多少之前的隐藏状态。Transformer的注意力大小是无限的,这是它优于LSTM的核心。实现这一优势的关键在哪呢?
Transformer不使用递归。
Transformer通过使用全局对比来实现无限的注意力跨度。它无需按顺序处理每个单词,而是一次性处理整个序列并创建“注意力矩阵”,其中每个输出都是输入的加权总和。举个例子来说,我们可以将法语单词“accord”表示为“ The(0)+agreement”(1)+…神经网络通过学习得到注意力矩阵的权重。

资料来源:NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
红框内的区域很有趣:尽管“European Economic Area(欧洲经济区)” 翻译成“européenne économique zone”,但在法语中,单词的排序实际上是“zone économique européenne”。注意力矩阵能够直接捕获这些关系。
注意力机制允许在输出值之间直接访问,而LSTM必须通过存储通道间接和按照一定顺序的访问同一信息。
Transformer的计算成本很高,毕竟构造矩阵的 O(n²)时间复杂度是不可避免的(O(n²)简单的说是指当n足够大的时候,复杂度将按平方增长)。但由于各种原因,它并不像某些人想象的那么严重。其中很关键的一点在于由于Transformer的非递归性质,可以使用并行计算来训练模型,这在应用LSTM或RNN时是不可能实现的。
此外,GPU和其他硬件的规模已经发展到可以令人难以置信的程度,1000乘以1000矩阵基本上可以与10乘以10矩阵相提并论。
现代transformer的长时间计算大部分都与注意力机制无关。相反,在其帮助下,递归语言模型的问题得以解决。
Transformer模型在迁移学习应用时也显示出了出色的结果,这对它的普及发挥了很大的作用。
那么LSTM还有未来吗?
要真正实现“退役”,还有很长的路要走,但是它的应用肯定处于下降状态。首先,LSTM的变体通常在序列建模方面显示出成功的应用,例如在音乐创作或预测股票价格方面,对这些应用来说引用和保留无限长的关注范围的能力并不那么重要,即使考虑到额外的计算负担。
小结
循环神经网络(RNN)通过将先前的输出传递给下一个输入来解决传统n-gram和BoW方法的稀疏性、效率低下和信息匮乏的问题,是一种更加序列化的建模方法。
LSTM的建立通过引入由门控制的长期和短期记忆通道,解决RNN会“遗忘”几个时间点之前的输入的问题。
LSTM的缺点包括:对迁移学习不友好、无法用于并行计算、以及即使扩展后的关注范围也有限。
Transformer模型直接丢掉了递归建模。与之不同的是,借助注意力矩阵,Transformer可以直接访问输出的其他元素,从而使它们具有无限的注意力区间。此外,它还可以进行并行计算。
LSTM在音乐创作或股票预测之类的顺序建模中仍然具有应用前景。但是,随着Transformer变得更加易于访问、功能强大和实用,与LSTM有关的语言建模可能逐渐销声匿迹。
相关报道:
https://towardsdatascience.com/long-short-term-memory-networks-are-dying-whats-replacing-it-5ff3a99399fe
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn