
【解密】硅谷互联网公司的大数据平台架构
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
导读:本文分析一下典型硅谷互联网企业的大数据平台架构。

Production Hosts:直接服务用户的生产服务器,也就是业务系统。 MySQL/Gizzard:用户关系图存在于Twitter的大规模MySQL分布式集群中,使用单个MySQL作为存储单位,在上面增加一层分布式协调数据分片(sharding)和调度的系统。 Distributed Crawler, Crane:类似于Sqoop和DataX的系统,可以从MySQL中将业务数据导出到Hadoop、HBase、Vertica里,主要用Java编写。 Vertica:大规模分布式数据处理系统(MPP),可以理解为一个以OLAP为主要任务的分布式数据库,主要用于建设数据仓库。类似的商业产品有Teradata、Greenplum等,类似的开源工具有Presto、Impala等。 Rasvelg:基于SQL的ETL工具,主要用于数据清洗、治理和数据仓库建设。 ScribeAggregators:日志实时采集工具,类似于Flume和Logstash,主要目的是将日志实时采集到Hadoop集群中(图7-2中的RT Hadoop Cluster)。 Log Events:主要是将客户端埋点的数据或其他需要实时处理的数据写入各种消息中间件中。 EventBus、Kafka、Kestrel queue:Kafka是开源的消息中间件,EventBus和Kestrel都是Kafka出现之前Twitter内部开发的消息中间件。需要内部系统的原因是有些业务需要类似于exactly-once(确定一次)的语义或者其他特殊需求,而Kafka成熟较晚,直到2017年的0.11版才推出exactly-once这种语义。 Storm、Heron:消息中间件的数据会被一个实时处理系统处理。Twitter早期用的是Storm,但后来发现Storm性能和开发问题比较大,就自己用C++开发了一个与Storm API兼容的系统Heron来取代Storm,并在2016年开源。 Nighthawk、Manhattan:Nighthawk是sharded Redis,Manhattan是sharded key-value store(用来取代Cassandra),推文、私信等用户信息存放在Manhattan里,Nighthawk作为缓存,这些组件是直接服务业务的;实时处理的数据和一些批处理分析的数据也会放在这里,被业务系统调用。 LogMover:日志复制工具,主要使用Hadoop的distcp功能将日志从实时服务器复制到另一个大的生产集群。 第三方数据:例如苹果应用商店的数据,这些数据使用定制的爬虫程序在Crane框架里执行。 Pig、Hive、Scalding、Spark:各种内部批处理分析框架,也用来开发ETL工具。 DirReplicator:用来在各个数据中心、冷热Hadoop集群、测试/生产集群中同步数据目录。 DAL:Twitter的数据门户,基本上所有的数据操作都要经过DAL的处理。 Tableau、Birdbrain:Twitter的数据可视化/BI工具,Tableau是通用的商业化工具,主要供具有统计背景的数据分析师使用;Birdbrain是内部的BI系统,它将最常用的报表和指标做成自助式的工具,确保从CEO到销售人员都可以使用。
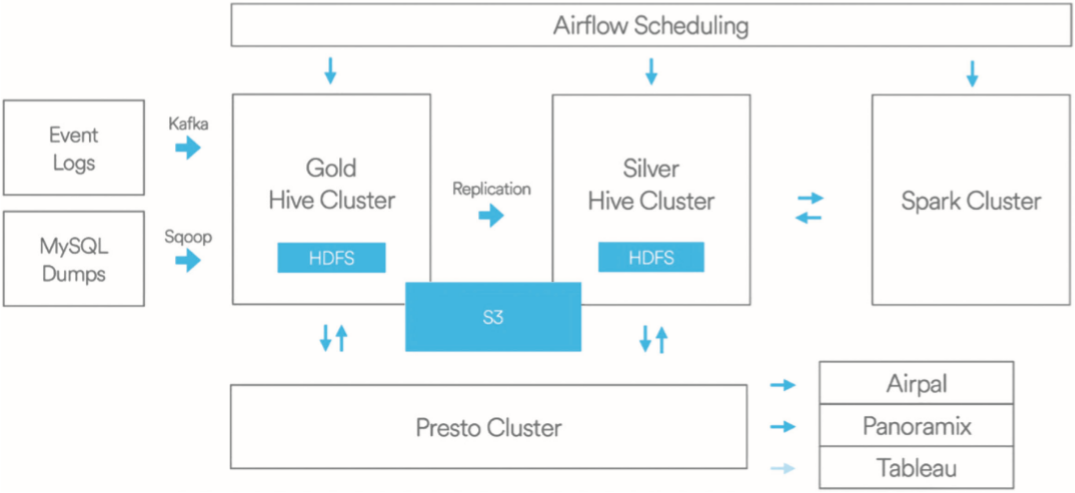
数据源:包含各种业务数据的采集,例如将数据埋点事件日志发送到Kafka,MySQL数据通过数据传输组件Sqoop传输到Hive集群。 存储:使用的是Hadoop的HDFS和AWS的S3。 复制:有专门的复制程序在金、银集群中复制数据。 资源管理:用到了YARN,同时通过Druid和亚马逊的RDS实现对数据库连接的监控、操作与扩展。 计算:主要采用MapReduce、Hive、Spark、Presto。其中,Presto是Facebook研发的一套开源的分布式SQL查询引擎,适用于交互式分析查询。 调度:开发并开源了任务调度系统Airflow,可以跨平台运行Hive、Presto、Spark、MySQL等Job,并提供调度和监控功能。 查询:主要使用Presto。 可视化:开发了负责界面显示的Airpal、简易的数据搜索分析工具Caravel及Tableau公司的可视化数据分析产品。
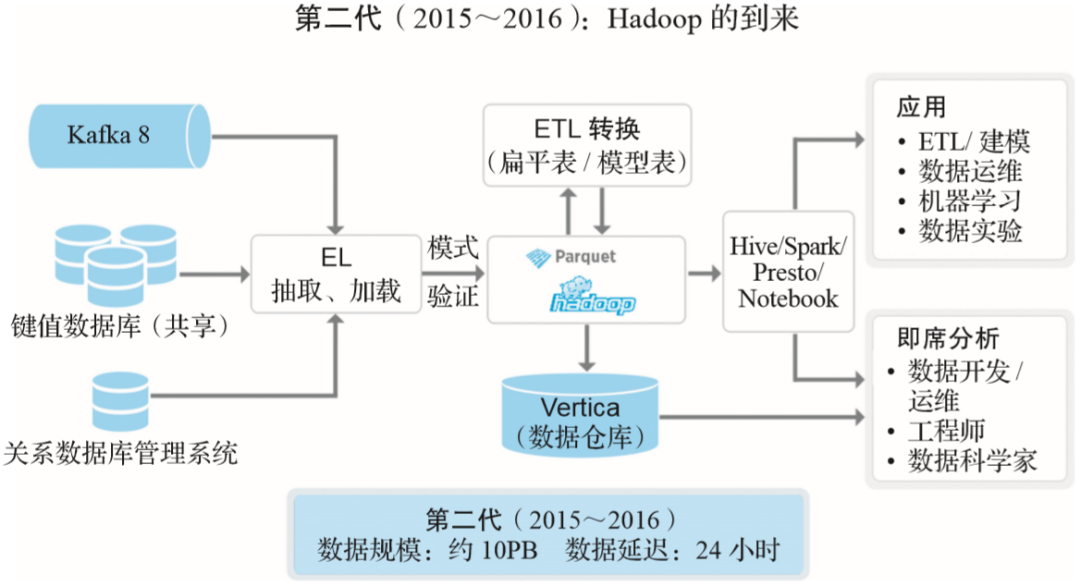
实时数据采集:Kafka。 键值数据库:类似于Twitter的Manhattan。 RDBMS DB:关系型数据库。 Ingestion:数据采集(这里它强调了强制类型检查,即schema enforced,强制类型检查是数据治理中的一环)。 数据采集、存储:主要使用Hadoop,采取Twitter开源的列式存储格式Parquet,构建了一个集中模式服务来收集、存储相关客户端库,将不同服务数据模式集成到这个中央模式服务中。 ETL:在Hadoop数据湖上进行数据的整合、治理、分析。 数据仓库:使用Vertica,主要存储从数据湖中计算出来的宽表,因为处理能力有限,一般只存储最近的数据。 计算框架:采用MapReduce、Hive、Spark和Presto。 查询工具:使用Presto来实现交互式查询,使用Spark对原始数据进行编程访问,使用Hive进行非常大的离线查询,并允许用户根据需求进行选择。 支持的数据应用:建模、机器学习、运营人员、A/B测试。 支持随机查询:运营人员、数据科学家。


统一的平台支持端到端的数据工具体系,尤其强调体现数据价值的应用。 强调数据能力的闭环,从数据的产生、使用到最后反馈到产品。 数据的采集、治理、分析、使用由所有部门在统一体系中完成。 主要的基础组件大部分采用成熟系统,如Hadoop、Hive、Kafka、Spark、Vertica。 自己开发一些侧重用户交互的组件,如ETL开发调度平台、数据门户、建模/数据治理。
全局的数据和应用资产的管理和运营; 明确平台团队和业务团队的分工和合作; 重视可衡量的数据能力。
重复造轮子风险大、投入高、见效慢; 自己造的轮子没有社区,原始开发人员离职后难以招人替代; 开发人员更愿意使用现有开源工具,闭源系统很难招到顶尖人才; 闭源开发的系统迭代一般比开源要慢很多,如果赶不上,差距会越来越大; 涉及系统越来越复杂,一个公司很难自己覆盖所有系统。
基础架构组件:这方面的产品或组件最好选择成熟的开源体系,因为成熟的开源体系经过了众多企业的千锤百炼,具有较高的稳定性和可靠性,而如果自己重新来做,未知因素太多,坑也太多。 用户交互组件:在基础架构之上与用户打交道的交互产品,因为各个企业使用习惯不一样,底层技术栈不一样,所以最好选择定制服务或者自主开发。

也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论