
谈谈过拟合
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

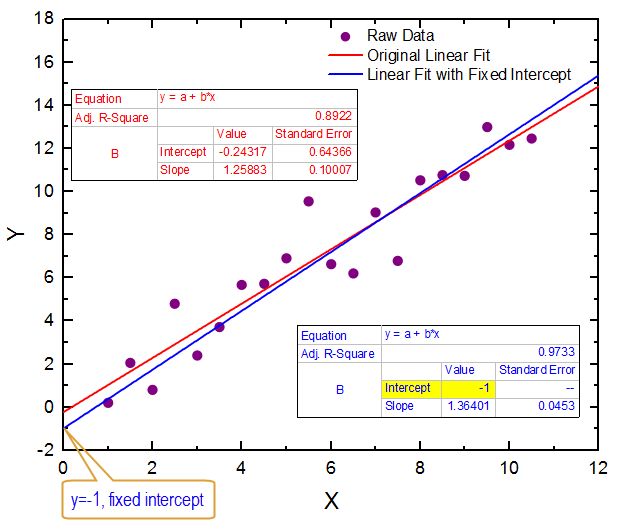
前段时间和部门里两位同事大佬一起参加天池算法竞赛。熟悉kaggle的朋友一定知道,比赛一般不会只给定一个测试集,而是在前期先用一个测试集,到了后期在换一个测试集,这叫A/B榜。为的就是不让有些同学不好好做模型而是去猜测试集的真值来改数据。我们做的是一个集成的高级回归模型,xgboost、lightgbm这些,在特征工程上做不动的时候,模型用lightgbm跑出来最多也就0.8的得分,但排行榜上的分数就一天比一天过分了,当我们还在0.8左右徘徊的时候,排行榜首页的得分就迅速降到了0.7(模型评价指标是均方误差,指标值越小模型越好),过几天又迅速向0.6逼近。这时候上比赛论坛,一位朋友说这排行榜首页都是过拟合,要么改了高低值,要么在猜测试集真值,不要太在意排行榜,等着换榜的时候就知道了。果然,后来官方换了一批测试集,原先的榜单首页那先眼熟的ID一个都不见了。过拟合真是害死人。
笔者之前曾分享过特征工程决定了机器学习模型上限的这样一个观点,认为特征工程才是机器学习的关键。其实这个说法也不是说不对,无非是为了凸显出特征工程对于机器学习模型好坏的重要性。这个观点多半为一些喜欢打kaggle等数据科学竞赛的爱好者们所推崇。笔者今天再分享一个观点:防止过拟合是机器学习的最关键问题之一。在机器学习的发展过程中,与欠拟合和过拟合做斗争一直影响着机器学习这门学科的进展,这场旷日持久的斗争是每一位学习机器学习的朋友都会亲身参与进来的一个实际存在的问题。
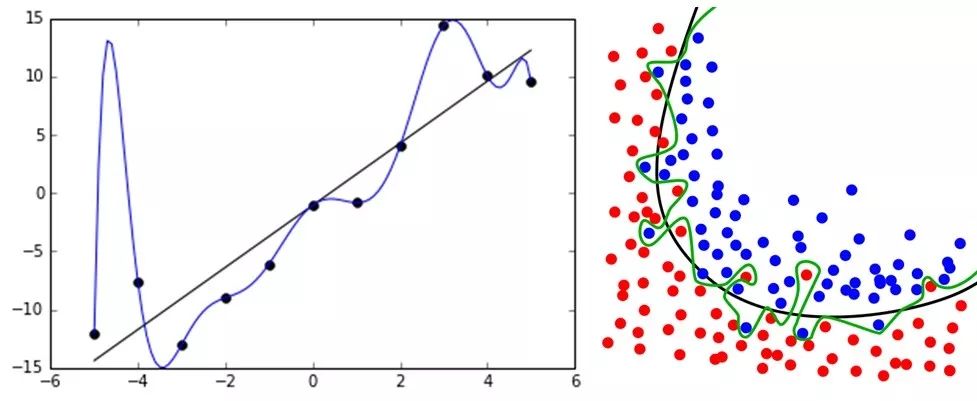
为了把过拟合这个关键问题说清楚,笔者有必要再和大家掰扯一下有监督机器学习。有监督机器学习的核心问题无非就是确定正则化参数的同时最小化经验风险。最小化经验风险是为了让模型更加充分的拟合给定的训练数据,而正则化参数则是控制这模型的复杂度,防止我们过分的拟合训练数据。你看,监督机器学习的核心哲学就是这句话,大道至简,无上真理。假设空间中模型千千万,当我们站在上帝视角,心里相信总会有个最好的模型可以拟合我们的训练数据,而且这个模型不会对训练集过度学习,它能够从训练集中尽可能的学到适用于所有潜在样本的“普遍规律”,不会将数据中噪声也学习了。这样的模型也就是我们想要的、能够有较低的泛化误差的模型。
监督机器学习的核心公式如下:
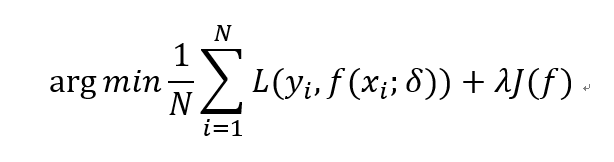
从公式就可以看出:监督机器学习的模型效果的控制有两项,第一项就是经验风险项,这项主要是由训练集所控制,一般我们要求模型要将经验误差训练的尽可能的小,如果该项过大则可能导致欠拟合,欠拟合好办,继续训练就是了。但正如上面所说,我们最后关注的重点更应该是第二项正则化项,从统计学习的角度来看,对监督机器学习加入正则化项是结构风险最小化策略的实现,正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大,所以正则化项的存在能够使得我们的模型避免走向过拟合。
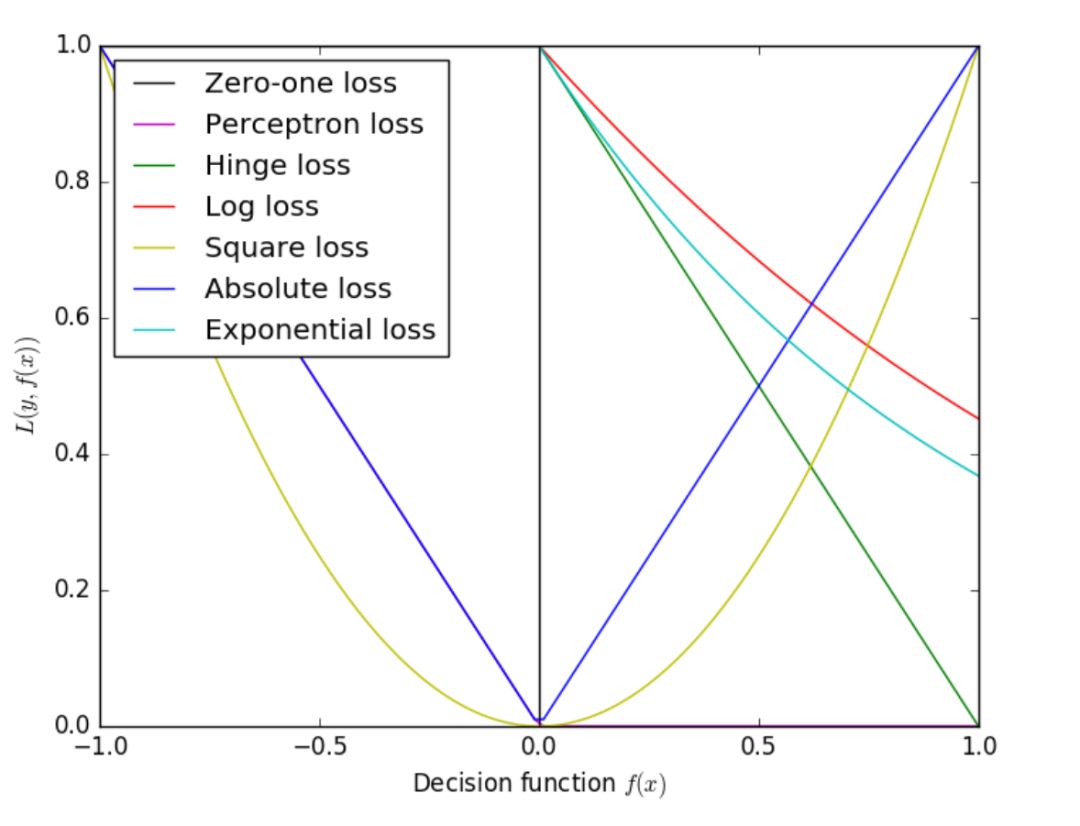
这里还想多说几句,大家在学习机器学习算法的时候,想必对线性回归、对数几率回归(逻辑回归)、支持向量机这些非概率模型定会下足功夫去学。当你再机器学习领域浸淫的足够长,你会发现至少80%的单一机器学习模型都是上面这个公式可以解释的。无非就是对这两项变着法儿换样子而已。对于第一项的损失函数,如果形式是平方损失(square loss),那就是线性回归了;如果是对数损失(log loss),那就是一直在叫法上搅不清的对数几率回归了;如果是合页损失(hingeloss),那就是大名鼎鼎的支持向量机了;如果是指数损失(exp loss),那就是牛逼哄哄的Adaboost啦!对于第二项正则化项,最常用的则是L0、L1和L2范数,本篇在这里不做过多解释,后续笔者会以专题形式对正则化范数进行解释。
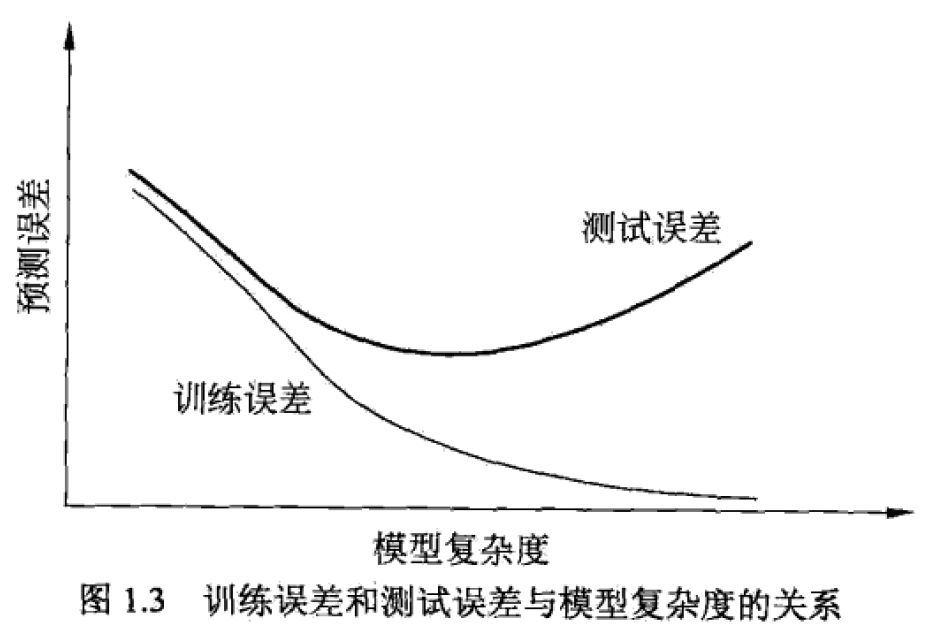
在拿实际的数据进行机器学习实战的时候,虽然我们大部分时间都在跟训练集较劲,但需要明确的一点就是,将训练误差较低并不是我们的最终目标,我们的目标是希望模型在测试集上有较好的表现,也就是模型的泛化误差要小,能够对所有未知的样本都能给出较好的预测结果。这也是我们在做kaggle和天池一类竞赛的时候需要明确的一点,有时候我的模型线下得分真不错,怎么看都顺眼,特征工程做的好,调参到位,哪哪都是最佳模型,可是一提交的线上得分便惨不忍睹。当然这不排除你划分的验证集和给定的测试集的数据分布存在偏差的原因,可能更主要的还是线下模型过拟合了。
okay,扯了这么多,想必各位已经被我这漫无边际的谈法给绕的差不多了。一句话总结过拟合就是:指在机器学习模型训练过程中,模型对训练数据学习过度,将数据中包含的噪声和误差也学习了,使得模型在训练集上表现很好,而在测试集上表现很差的一种现象。那如何解决或者缓解过拟合这种现象呢?除了获取更多的训练数据、选用更好更加集成的模型之外,为损失函数添加正则化项是最为值得一试的方法。
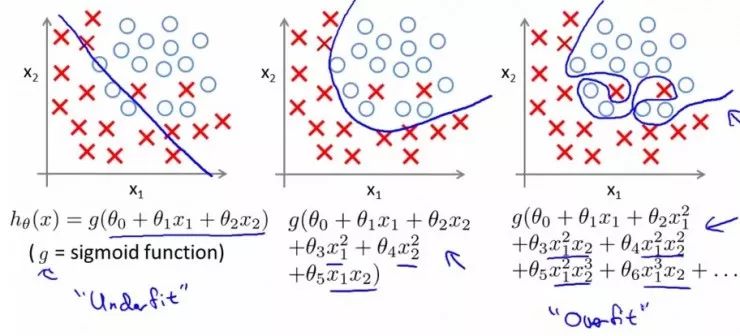
正如在开头所说的那样,与过拟合做斗争贯穿了整个机器学习的发展过程。实际上,我们不可能避免过拟合的产生,而只能通过一些手段来缓解过拟合现象。真实生活和生产环境下产生的数据远比简化后放入模型的数据要复杂,其中的噪声和误差更是极为正常的现象,只要数据中存在噪声,过拟合就一定会产生,所以如何缓解、中和过拟合,既是机器学习中的一个技术方法,也是一门艺术。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~