
关于pytorch中使用detach并不能阻止参数更新这档子事儿

极市导读
文章分三个部分解释了pytorch中detach和参数更新的问题:1)detach后参数依旧更新的原因 2)step函数的操作 3)如何达到之前提到的效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
最近做实验,虽然没做出什么有价值的成果,但是对pytorch中detach和参数更新有了进一步的认识。众所周知,detach能够阻断梯度回传。首先来看一下detach的基本用法, 下面这个模型有两层线性变换组成,中间使用relu激活:
class TestDetach(nn.Module):def __init__(self, InDim, HiddenDim, OutDim):super().__init__()self.layer1 = nn.Linear(InDim, HiddenDim, False)self.layer2 = nn.Linear(HiddenDim, OutDim, False)def forward(self, x, DetachLayer1):x = torch.relu(self.layer1(x))x = x.detach()x = self.layer2(x)return x
第一层的输出后detach,那么第一层的参数将永远不会更新。然而在一些情况下单纯的detach可能并不能达到固定参数的作用,这也就是这篇文章要谈的:在哪些情况下单纯的detach不能阻断参数的更新,然后应该如何去做。
首先来看一个具体的场景:还是上面的模型,它有两个参数layer1的权重矩阵,记为weight1和layer2的权重矩阵,记为weight2,但是我并不想让他们同步更新,而是weight2每更新N次,weight1才更新一次(先不讨论这样做有没有实际的应用意义)。一开始想的很简单,通过detach来阻断梯度的计算,从而阻止参数更新。模型的代码如下:
class TestDetach(nn.Module):def __init__(self, InDim, HiddenDim, OutDim):super().__init__()self.layer1 = nn.Linear(InDim, HiddenDim, False)self.layer2 = nn.Linear(HiddenDim, OutDim, False)def forward(self, x, DetachLayer1): # 多传了一个bool参数,以指示是否detachx = torch.relu(self.layer1(x))if DetachLayer1:x = x.detach()x = self.layer2(x)return x
前向传播的时候为模型传递一个bool参数DetachLayer1,当其为真的时候对第一层的输出进行detach,以阻止梯度的反向传播。之后是训练的代码:
def train():# 随机生成数据N, F = 5000, 196x = torch.Tensor(np.random.randn(N, F))y = torch.LongTensor(np.random.randint(0, 3, (N,)))# 生成损失函数,模型,优化器LossFunc = nn.CrossEntropyLoss()model = TestDetach(F, 64, 3)optimizer = torch.optim.Adam(model.parameters(), lr=1, weight_decay=0.5)# 训练for epoch in range(100):# 将DetachLayer1交替置为True和FalseDetachLayer1 = False if epoch % 2 == 0 else TrueYhat = model(x, DetachLayer1)Loss = LossFunc(Yhat, y)print(f"Epoch {epoch}, DetachLayer1: {DetachLayer1}, Loss: {Loss:.4f}")Loss.backward()optimizer.step()optimizer.zero_grad()
猛地一看并没有什么问题,我们控制bool参数的值,每次进行翻转,epoch为奇数,detach有效,参数不更新;反之,偶数则更新,以使得weight1能够隔一次更新一次。然而,实际运行起来,并不能达到我想要的效果:
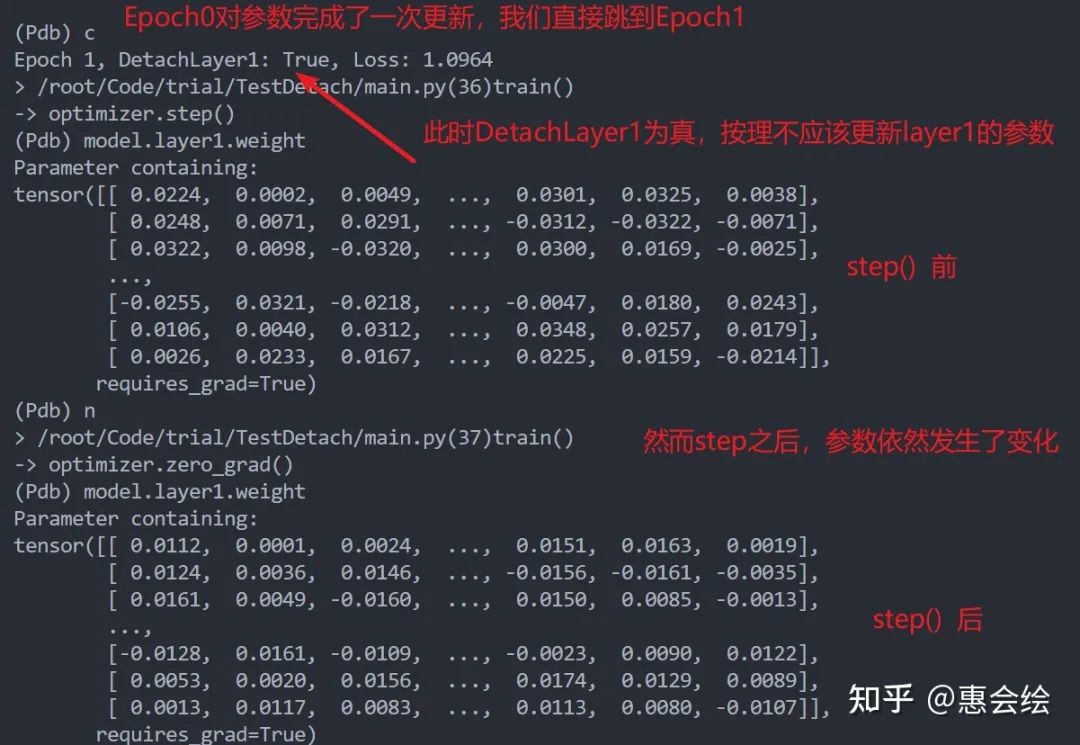
如果你亲自单步调试的话,会发现第一层的参数再一直变化,并没有被固定住,就像是detach没有起到作用一样。进一步观察第一层变量的梯度的话,你会发现梯度确实也是0,但是参数确实也在更新:

这时候,如果没有意识到真正的问题所在的话,很可能以为是pytorch出了什么bug,或者如果你的模型很复杂,就会很容怀疑是不是模型哪里写错了。然而,问题不在模型,而在于优化器,那么下面我们就来仔细看看。当然, 如果你已经意识到了问题出在哪里,那么我估计也不用花时间往下看了,因为问题完全是因为基础知识不牢固而导致的一个愚蠢的问题,除此之外或许你也可以划到后面简单看看step函数和zero_grad的操作,或许会有一点儿收获。
下面文章分为三个部分:1)detach后参数依旧更新的原因 2)step函数的操作 3)如何达到之前提到的效果
1)detach后参数依旧更新的原因
谜底揭晓,其实就一句话:参数更新并不只依靠当前梯度。如果你知道有一些优化器更新参数的时候会利用历史信息,那就很好理解了。detach确实有用,确实是没有计算当前回传时的梯度,但是优化器可能利用了历史的梯度信息对参数进行了更新。比如我们这里使用的adam:

可以看出(或者没有看出,但是问题不大,直接告诉你):它有累计一阶动量和二阶动量,简单地说也就是,虽然当前的梯度为零,但是因为之前计算过梯度,所以累积量不为零,每次迭代仍然能利用累积量更新参数。
那么更换优化器为最朴素的SGD(默认动量系数为0):
optimizer = torch.optim.SGD(model.parameters(), lr=1)
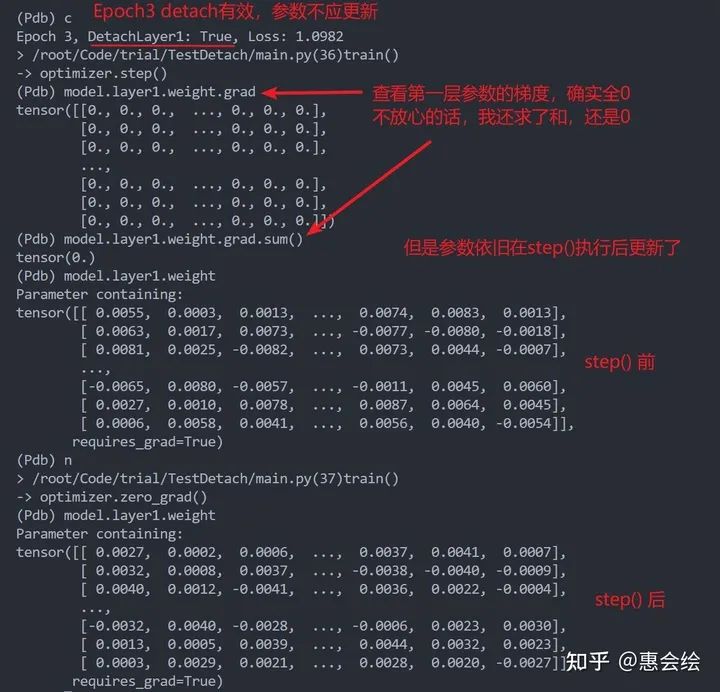
我们会发现确实达到了我们想要的效果:第一层的参数在detach的情况下也不会更新了,之后可以将动量的参数"momentum"设置为非零,那么也会观察到我们前面提到的:detach时,也会有参数更新。值得一提的是,pytorch的优化器自带weight_decay参数,来为参数提供正则化的约束(可以简单理解为参数每次更新都有一个递减量),如果这个参数非零,也会出现之前的问题。
那问题又来了,如果第一层参数一直被detach的话,第一层的参数就不会变,也就是weight_decay并不会影响第一层的参数;但是为啥更新一次之后,再detach,weight_decay就会影响到明明已经被detach了的参数呢?这个要从step的操作说起了。
2)step函数的操作
pytorch中参数更新的一个套路性操作:backward,step, zero_grad。backward计算梯度,step根据当前计算的梯度和历史更新记录去更新参数,zero_grad将梯度置零,以防止梯度累计。下图单步展示了三者的功能:
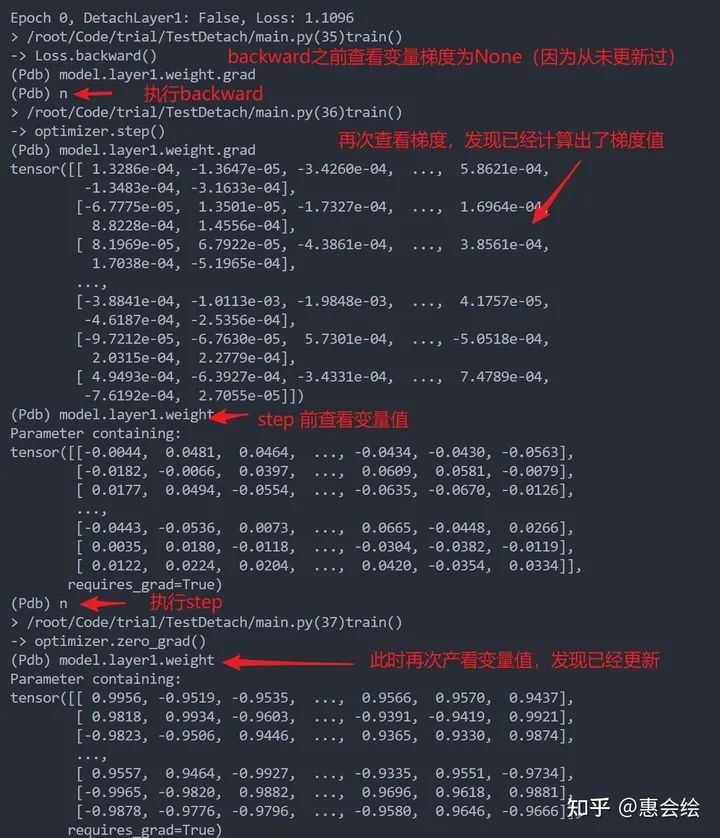
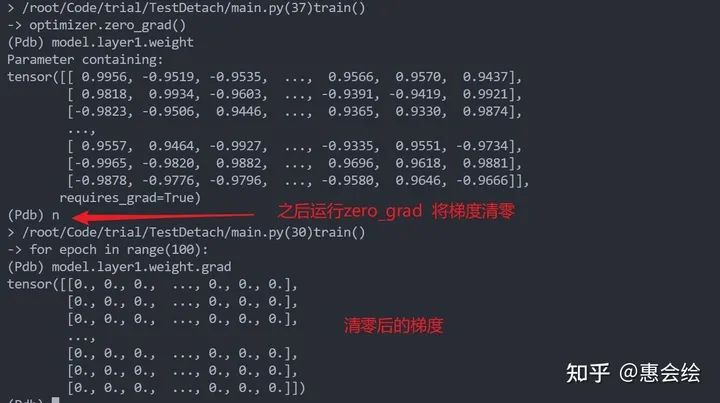
值得一提的是:上面zero_grad将梯度清零,而不是置为之前的None。然后,我们跳转到step的实现部分,注意观察第62行:
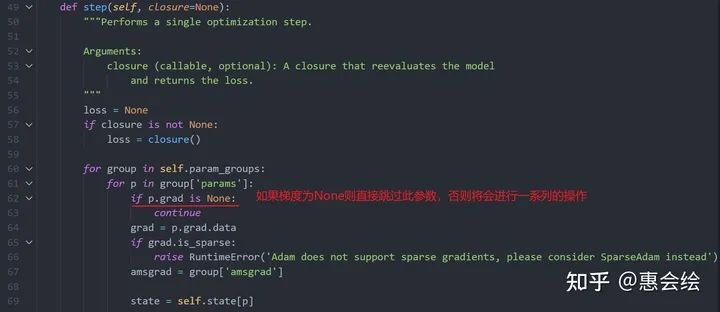
只要参数的grad为None,那么优化器就什么都不做,直接跳过这个参数;然而如果不是None,即使是全零,优化器仍然会进行后续的操作,以更新参数。所以一个参数如果一开始没有被detach,使得它的梯度由None转化为tensor,那么之后即使再被detach,参数很可能依旧被更新(被历史梯度的累计或者是weight_decay更新)。
3)如何解决
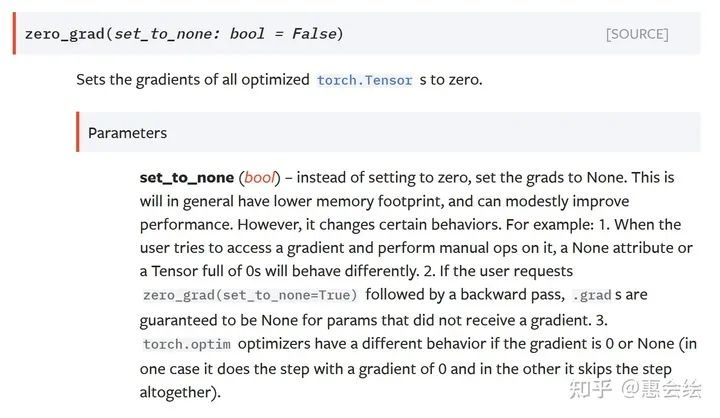
我最开始的想法是使用两个优化器分别去更新两层的参数。但是如果仔细分析一下就能发现,导致这个问题的原因是,zero_grad将计算得的梯度变为全零张量,而不是变为之前的None。只要将梯度再次转化为None,那么就会避免历史信息和weight_decay对参数的更新了。pytorch已经考虑到了这一点,调用zero_grad时可以指定参数:set_to_none,将其置为True即可。
4)结束
对detach和参数更新的一点认识,欢迎讨论交流和批评指正。
其他文章,欢迎阅读:
惠会绘:关于把图神经网络做到大图(large-scale)上这档事儿
https://zhuanlan.zhihu.com/p/345233657
推荐阅读
2021-04-14

2021-04-13

2021-03-27


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
