
ProseMirror实现文本编辑
大厂技术 坚持周更 精选好文
最近搞各种编辑器,也涉及到了富文本编辑器,prosemirror[1]是当前非常流行的富文本编辑器,因此希望通过剖析其实现原理,来窥探编辑器的架构设计。
背景
prosemirror 的官网提供了很多的 example ,最基础的 demo 可以参见这里[2]。
虽然前端研发都知道富文本是基于 html 和 css 来渲染的,但是如何可视化的修改这些 html 以及 css 却是富文本编辑器需要解决的问题。
浏览器提供了 contenteditable 使得元素可以编辑,以及 document.execCommand 让 js 具备能力去改变元素。但直接用这两个能力去做富文本编辑器是很坑的,具体可以参考这篇文章[3]。
所以一般富文本编辑器都采用如下的架构。
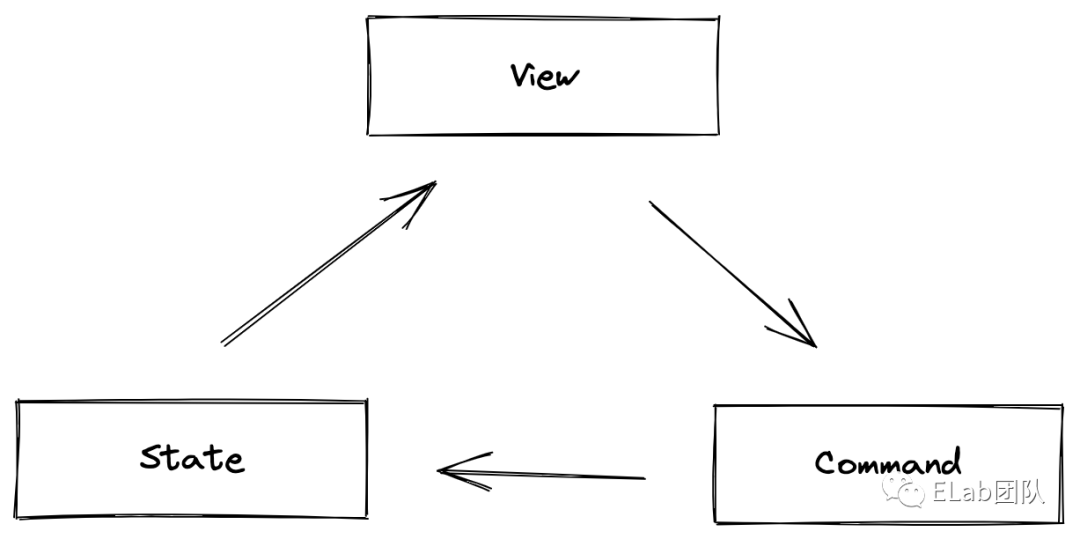
prosemirror 也不例外,所以在剖析代码之前,先整体看一下 prosemirror 的代码组织结构。
代码结构
prosemirror 核心有四个模块。
prosemirror-model:定义编辑器的文档模型,用来描述编辑器内容的数据结构。
prosemirror-state:描述编辑器整体状态,包括文档数据、选择等。
prosemirror-view:UI组件,用于将编辑器状态展现为可编辑的元素,处理用户交互。
prosemirror-transform:修改文档的事务方法。
可以发现,prosemirror 的核心模块和上述架构是完全对应得上的。因此本文就从 state 、view , transform 三个方面来探索 prosemirror 的实现原理。
下面先描述两个典型流程,以便更清晰地达到了解的目的。
典型流程
初始化流程
首先看一下 prosemirror 的初始化代码。
// 创建schema
const demoSchema = new Schema({
nodes: addListNodes(schema.spec.nodes, "paragraph block*", "block"),
marks: schema.spec.marks
})
// 创建state
let state = EditorState.create({
doc: DOMParser.fromSchema(demoSchema).parse(document.querySelector("#content")),
plugins: exampleSetup({ schema: demoSchema })
})
// 创建view
let view = EditorView(document.querySelector('.full'), { state })
初始化的代码非常清晰,先是创建文档数据的规范标准,类似约定了数据协议。其次创建了 state,state 是需要满足 schema 规范的。最后根据 state 创建了 view,view 就是最终展现在用户面前的富文本编辑器UI。因为初始化的时候还没有用户操作的介入,所以并不涉及 command 也就是 transform 的引入。
编辑器初始化的详细流程图。
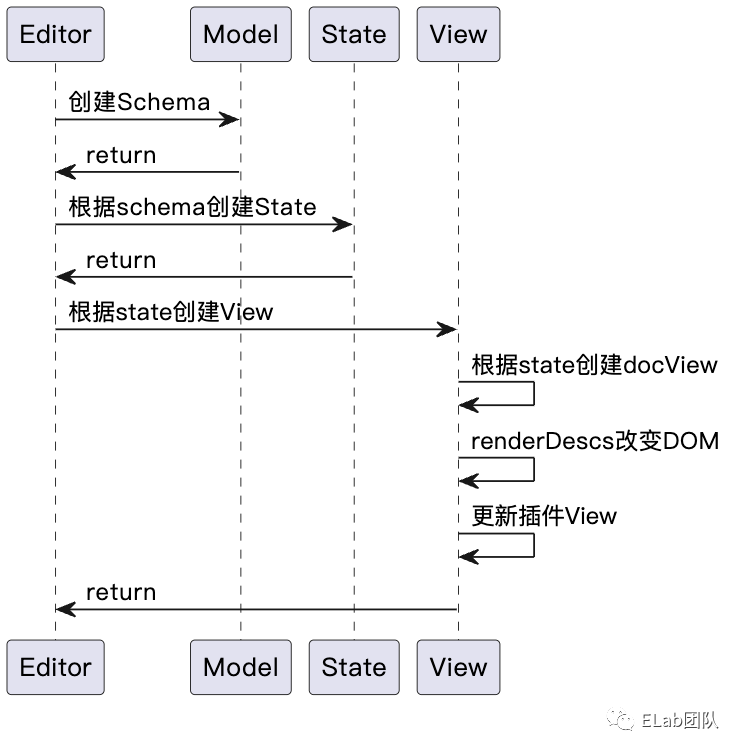
因为此类架构的富文本编辑器本质是 F(state) = view ,界面是由数据驱动的,而 contenteditable 的元素又是非受控的,所以保证状态和界面的一致性是非常重要的。
在上述创建状态的代码中,DOMParser 解析了 id 为 content 的元素的内容,并将其传给了状态的工厂函数。DOMParser ,顾名思义就是解析 DOM 元素的,其核心作用就是将元素内容同步到状态中,准确的说是 state 中的 doc 属性。
let state = EditorState.create({
doc: DOMParser.fromSchema(demoSchema).parse(document.querySelector("#content")),
plugins: exampleSetup({ schema: demoSchema })
})
更新流程
当用户在编辑器里面输入一个字符的时候,会触发更新流程。详细的更新流程如下。
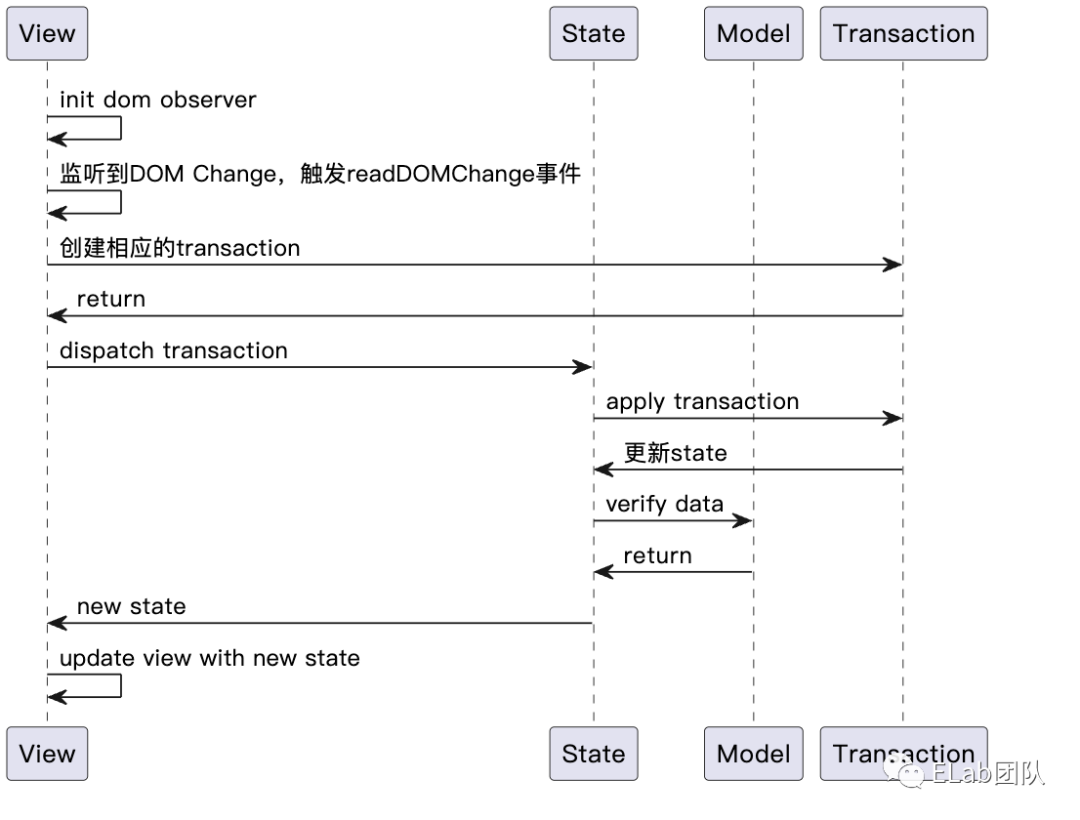
可以看到输入字符会触发 view 变化,继而更新 state ,保证 state 和 view 的一致性。如果我们输入的是自定义的元素,就会在触发 state 更新之后,再通过 updateState 方法更新 view,展示自定义的元素。
可以发现上述流程都和 state, view 以及 transform 紧密相关,下面就结合这两个流程来详细阐述下各层的设计。
state层
prosemirror 的 state 并不是固定的,而是可以扩展的,但其有基本的四个属性:doc 、 selection 、 storedMarks 、 scrollToSelection。不过其中最核心的应该是 doc ,也就是文档结构,里面存放的是文档数据。在初始化流程中,有提到 DOMParser 会把初始富文本信息同步到 doc 属性中。
每一次编辑都会产生一份新的编辑器数据,如何优化存储,也是比较有意思的话题,不在本文描述。
另外值得提一嘴的是,其 plugin 机制也是基于 state 来做的。
文档结构
众所周知,HTML的文档结构是树状的,而 prosemirror 采用的是基于 inline + mark 的数据结构。每个文档就是一个 node , node 包含一个 fragment ,fragment 包含一个或者多个子 node 。其中核心是 node 的数据结构。
对比如下(来自官网)。

在 prosemirror 中,p 是一个节点,其有三个子节点 this is , string text with 以及 emphasis 。而类似 strong ,em 这些非内容本身,仅仅是用来装饰内容的东西,就作为文本的 mark 存储在文本节点里面了。这样就从树状结构变成了 inline 的结构。
这里面有一个核心的好处是,如果是树状结构,我们对于一个既 strong 又 em 的文字,有如下两种描述方式。
hello world
和
hello world
显然,这样的话,文档数据就会不稳定,同样的展示将会对应不用的数据,问题很大。如果采用 prosemirror 的存储结构,类似上图的 emphasis ,只要保证各 mark 的排序是稳定的,其数据结构就是唯一的。
除了上述这个优点以外,针对富文本编辑这个场景,这种数据结构还有其他的优势。
更符合用户对文本操作的直观感受,可以通过偏移量来描述位置,更加轻易的做分割。
通过偏移量来操作性能上会比操作树要好很多。
view层
这一部分主要描述,view 层是如何根据 state 来展示界面的。
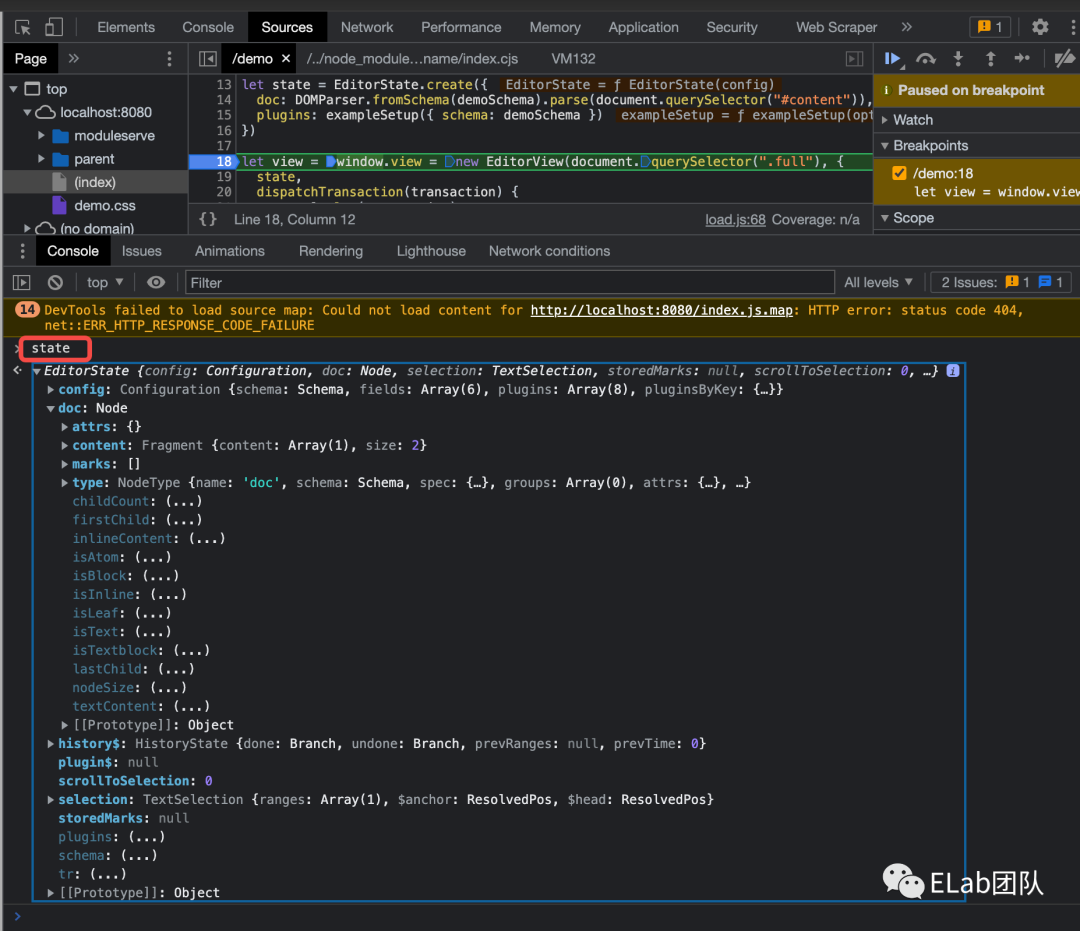
如下是在编辑器中新增图片节点时候的调试图。
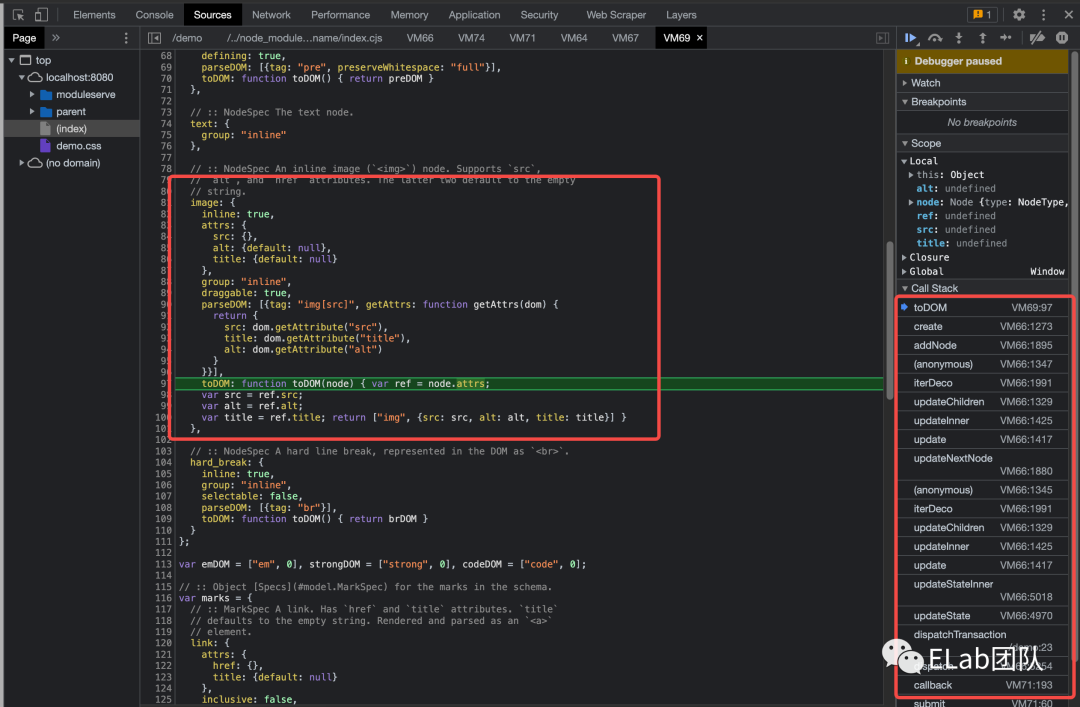
view 调用 updateState (也就是根据 state 来更新视图, 在更新流程中有提到)时,会调用节点的 toDOM 方法来创建 DOM 元素,从而渲染到浏览器上。
相应的还有 parseDOM 方法,可以根据 DOM 元素,序列化成文档数据。
每次初始化,或者有 state 有更新的时候,都会触发 updateState 方法,从而完成界面的更新。
transform层
在更新流程中,当 view 发生变化时,会构建 transaction (其父类就是 transform),来更新 state。
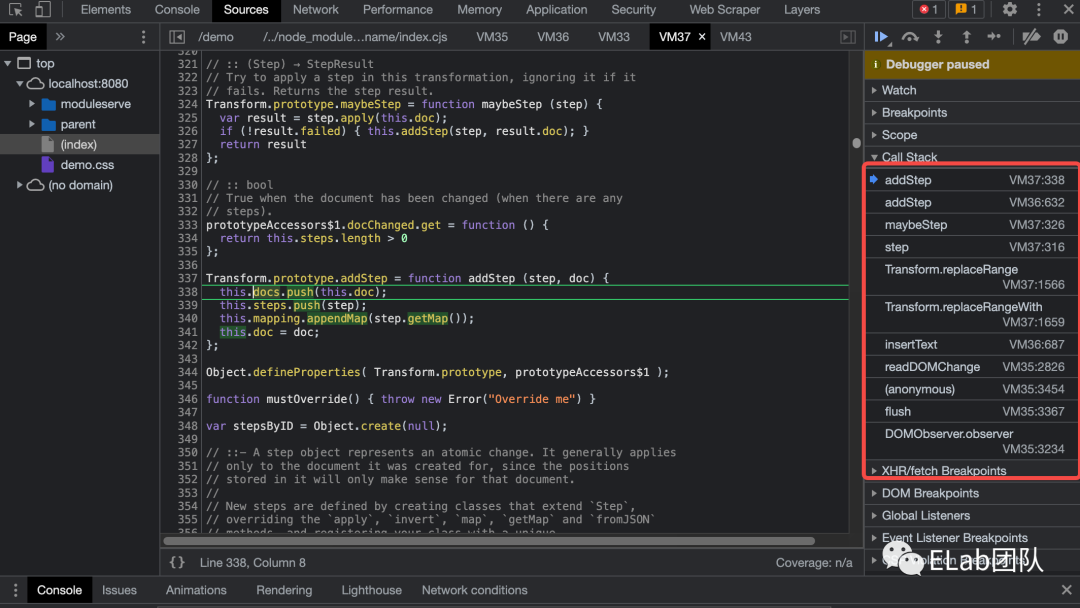
通过该堆栈可以发现,在富文本编辑器输入内容的时候,会触发 DOM 变更事件,进而通过 view.state.tr.insertText 来创建一个 insertText 的 transaction。一个 transaction 内部有一个或者多个 step ,insertText 这个 transaction 内部只有一个 ReplaceStep。
prosemirror 内置的 Step 包括:
AddMarkStep
RemoveMarkStep
ReplaceStep
ReplaceAroundStep
这些 step 都有核心的两个方法,一个是 apply ,另外一个是 invert 。apply 就是运行这个 step , invert 就是恢复用的动作。这对于做回退操作是非常有用的。
参考文档
prosemirror github[4]
参考资料
prosemirror: https://prosemirror.net/
[2]https://glitch.com/edit/#!/maple-probable-song?path=index.js%3A1%3A0
[3]https://zhuanlan.zhihu.com/p/123341288
[4]prosemirror github: https://github.com/prosemirror
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 趣谈前端 收货大厂一手好文章~
LowCode可视化低代码社区介绍
LowCode低代码社区(http://lowcode.dooring.cn)是由在一线互联网公司深耕技术多年的技术专家创办,意在为企业技术人员提供低代码可视化相关的技术交流和分享,并且鼓励国内拥有相关业务的企业积极推荐自身产品,为国内B端技术领域积累知识资产。同时我们还欢迎开源大牛们分享自己的开源项目和技术视频。
如需入驻请加下方小编微信: lowcode-dooring