Jeff Dean大规模多任务学习SOTA遭吐槽,复现一遍要6万美元!

新智元报道
新智元报道
编辑:David 好困 袁榭
【新智元导读】谷歌大神Jeff Dean最近亲自操刀发新作,提出了一个大规模多任务学习框架µ2Net,基本把各大数据集多任务学习的SOTA刷了个遍,但这次为何网友有点不买账了?很简单,差钱。
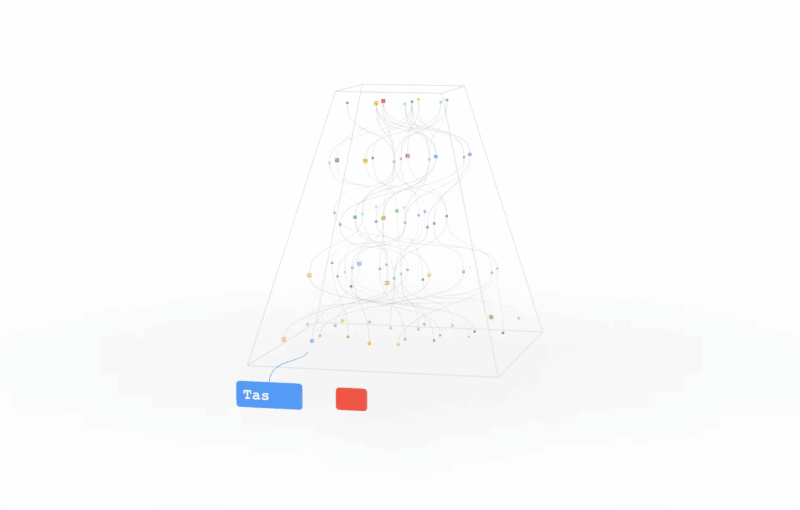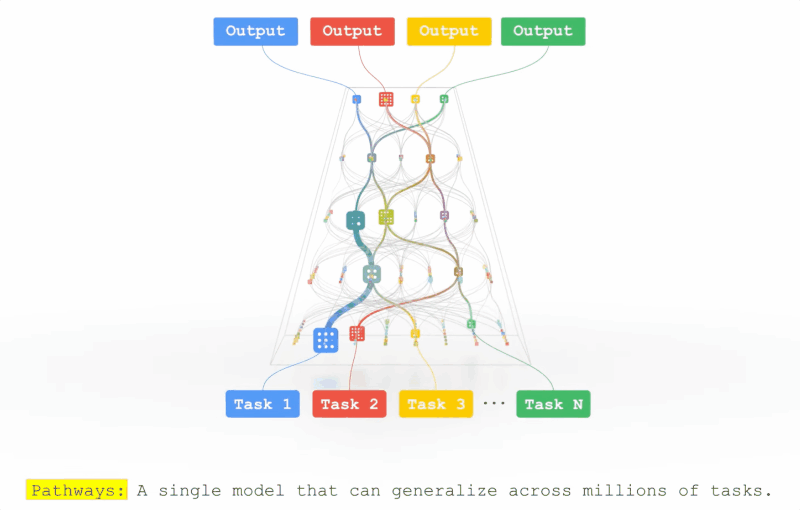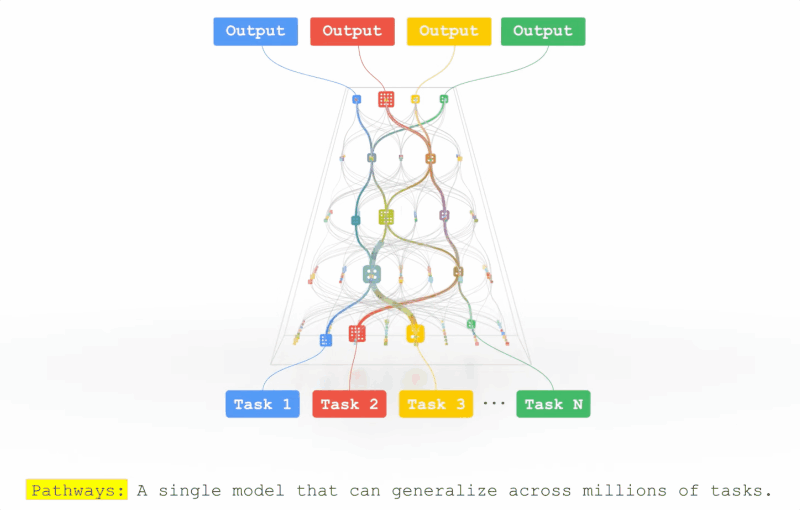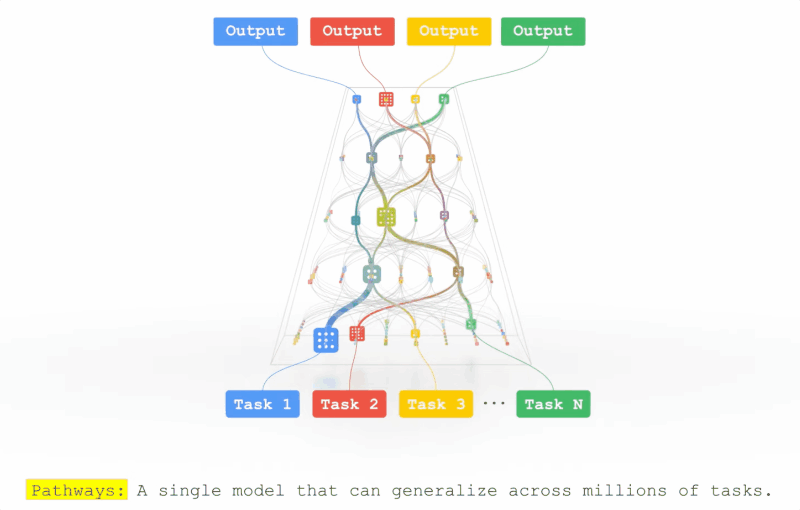

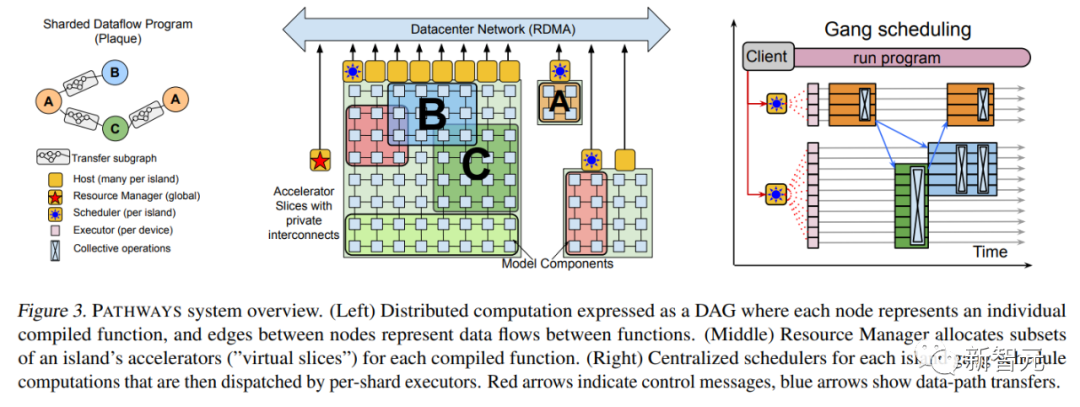

Pathways的拼图又合上了一块?

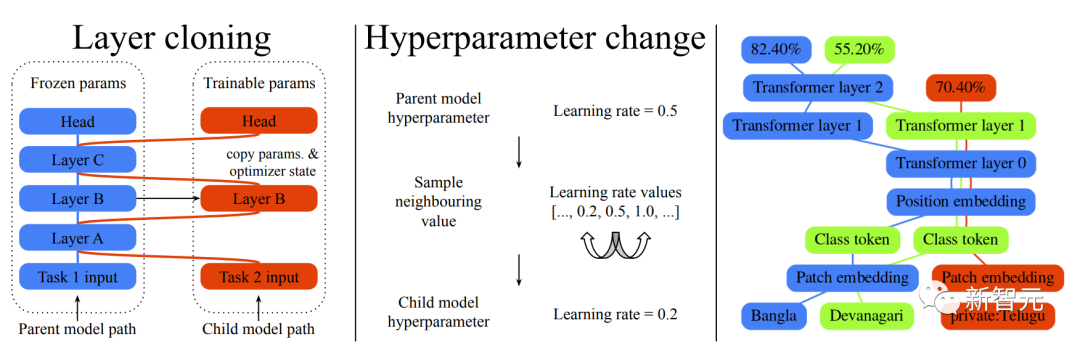
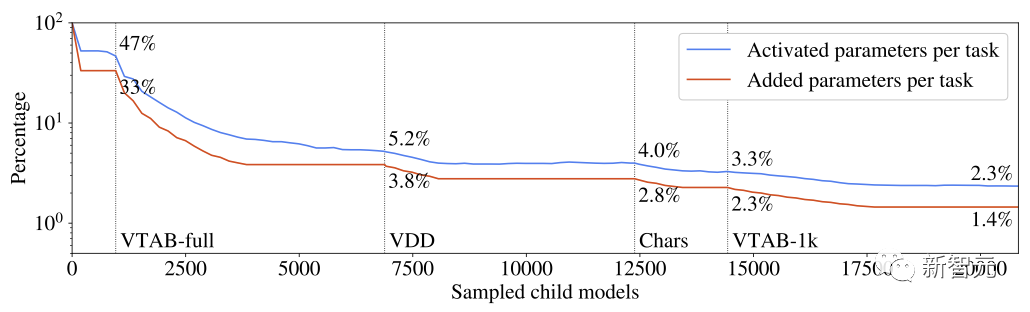



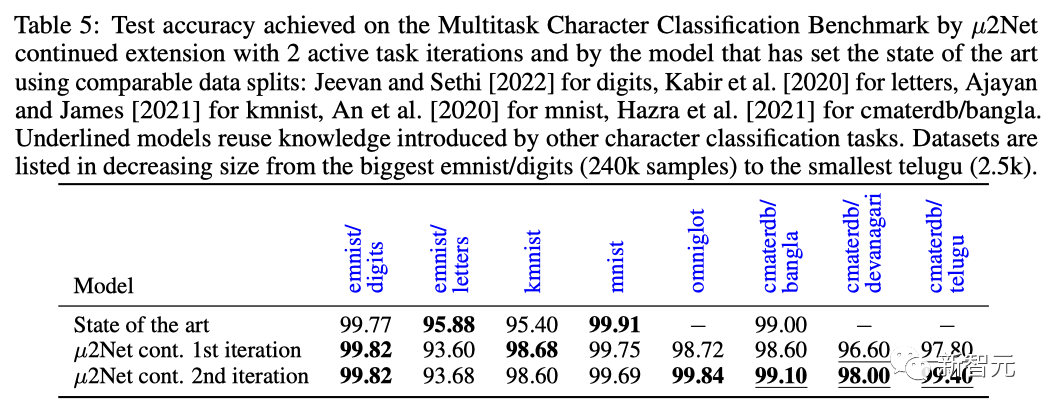
网友:论文很好,但……
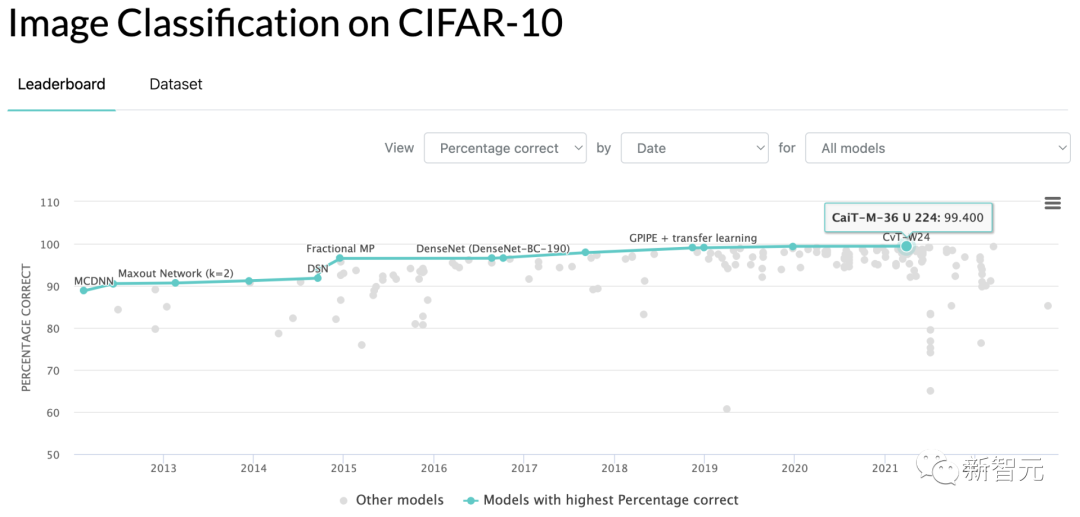



参考资料:
https://arxiv.org/abs/2205.12755

评论
 下载APP
下载APP
新智元报道
编辑:David 好困 袁榭
Pathways的拼图又合上了一块?
网友:论文很好,但……
参考资料:
https://arxiv.org/abs/2205.12755