
如何快速搭建智能人脸识别系统(附代码)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

网络安全是现代社会最关心的问题之一,确保只有特定的人才能访问设备变得极其重要,这是我们的智能手机设有两级安全系统的主要原因之一。这是为了确保我们的隐私得到维护,只有真正的所有者才能访问他们的设备。基于人脸识别的智能人脸识别技术就是这样一种安全措施,本文我们将研究如何利用VGG-16的深度学习和迁移学习,构建我们自己的人脸识别系统。
本项目构建的人脸识别模型将能够检测到授权所有者的人脸并拒绝任何其他人脸,如果面部被授予访问权限或访问被拒绝,模型将提供语音响应。用户将有 3 次尝试验证相同,在第三次尝试失败时,整个系统将关闭,从而保持安全。如果识别出正确的面部,则授予访问权限并且用户可以继续控制设备。完整代码将在文章末尾提供Github下载链接。
首先,我们将研究如何收集所有者的人脸图像。然后,如果我们想添加更多可以访问我们系统的人,我们将创建一个额外的文件夹。我们的下一步是将图像大小调整为 (224, 224, 3) 形状,以便我们可以将其通过 VGG-16 架构。请注意,VGG-16 架构是在具有上述形状的图像净权重上进行预训练的。然后我们将通过对数据集执行图像数据增强来创建图像的变化。在此之后,我们可以通过排除顶层来自由地在 VGG-16 架构之上创建我们的自定义模型。接下来是编译、训练和相应地使用基本回调拟合模型。

在这一步中,我们将编写一个简单的 Python 代码,通过单击空格键按钮来收集图像,我们可以单击“q”按钮退出图形窗口。图像的收集是一个重要的步骤,本步骤将授予设备人脸信息收集的访问权限。执行以下代码将完成本步骤:
import cv2import oscapture = cv2.VideoCapture(0)directory = "Bharath/"path = os.listdir(directory)count = 0
我们将“打开”我们的默认网络摄像头,然后继续捕获数据集所需的面部图像。这是由 VideoCapture 命令完成的。然后我们将创建一个指向我们特定目录的路径并将计数初始化为 0。这个计数变量将用于标记我们的图像,从 0 到我们单击的照片总数。执行整个图像采集过程所需的代码:
while True:ret, frame = capture.read()cv2.imshow('Frame', frame)key = cv2.waitKey(1)if key%256 == 32:img_path = directory + str(count) + ".jpeg"cv2.imwrite(img_path, frame)count += 1elif key%256 == 113:breakcapture.release()cv2.destroyAllWindows()
我们确保代码仅在网络摄像头被捕获和激活时运行,然后将捕获视频并返回帧。然后我们将分配变量“key”以获取按下按钮的命令。这个按键给了我们两个选择:
当我们按键盘上的空格键时单击图片。
按下“q”时退出程序。
退出程序后,我们将从网络摄像头中释放视频捕获并销毁 cv2 图形窗口。
在下一个代码块中,我们将相应地调整图像大小。我们希望将我们收集的图像重塑为适合通过 VGG-16 架构的大小,该架构是对 imagenet 权重进行预训练的。
import cv2import osdirectory = "Bharath/"path = os.listdir(directory)for i in path:img_path = directory + iimage = cv2.imread(img_path)image = cv2.resize(image, (224, 224))image)
我们将所有从默认帧大小捕获的图像重新缩放到 (224, 224) 像素,因为我们想尝试像 VGG-16 这样的迁移学习模型,同时已经以 RGB 格式捕获了图像。因此我们已经有 3 个通道,我们不需要指定。VGG-16 所需的通道数为 3,架构的理想形状为 (224, 224, 3)。调整大小步骤完成后,我们可以将所有者的目录转移到图像文件夹中。
我们收集并创建了我们的图像,下一步是对数据集执行图像数据增强以复制副本并增加数据集的大小。可以使用以下代码块来做到这一点:
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=30,shear_range=0.3,zoom_range=0.3,width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=True,fill_mode='nearest')train_generator = train_datagen.flow_from_directory(directory,target_size=(Img_Height, Img_width),batch_size=batch_size,class_mode='categorical',shuffle=True)
重新缩放图像并更新所有参数以适合我们的模型,参数如下:
1,重新调整=重标度由1/255归一化每个像素值的
2 rotation_range =指定旋转随机范围
3. shear_range =指定在逆时针方向范围内的每个角度的强度
4. zoom_range = 指定缩放范围
5. width_shift_range = 指定扩展的宽度
6. height_shift_range = 指定扩展的高度
7. horizontal_flip =水平翻转图像
8. fill_mode= 根据最近的边界填充
train_datagen.flow_from_directory 获取目录的路径并生成批量增强数据。可调用的属性如下:
1. train dir = 指定我们存储图像数据的目录
2. color_mode = 图像灰度或RGB 格式,默认为 RGB
3. target_size = 图像的尺寸
4.batch_size =操作数据批次的数目
5. class_mode = 确定返回的标签数组的类型
6.shuffle= shuffle:是否对数据进行混洗(默认:True)
在下一个代码块中,我们将在变量 VGG16_MODEL 中导入 VGG-16 模型,并确保我们输入的模型没有顶层。使用没有顶层的 VGG-16 架构,我们现在可以添加我们的自定义层。为了避免训练 VGG-16 层,我们给出以下命令:
layers.trainable = False。我们还将打印出这些层并确保它们的训练设置为 False。
VGG16_MODEL = VGG16(input_shape=(Img_width, Img_Height, 3), include_top=False, weights='imagenet')for layers in VGG16_MODEL.layers:layers.trainable=Falsefor layers in VGG16_MODEL.layers:print(layers.trainable)
在 VGG-16 架构之上构建我们的自定义模型:
# Input layerinput_layer = VGG16_MODEL.output# Convolutional LayerConv1 = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='valid',data_format='channels_last', activation='relu',kernel_initializer=keras.initializers.he_normal(seed=0),name='Conv1')(input_layer)# MaxPool LayerPool1 = MaxPool2D(pool_size=(2,2),strides=(2,2),padding='valid',data_format='channels_last',name='Pool1')(Conv1)# Flattenflatten = Flatten(data_format='channels_last',name='Flatten')(Pool1)# Fully Connected layer-1FC1 = Dense(units=30, activation='relu',kernel_initializer=keras.initializers.glorot_normal(seed=32),name='FC1')(flatten)# Fully Connected layer-2FC2 = Dense(units=30, activation='relu',kernel_initializer=keras.initializers.glorot_normal(seed=33),name='FC2')(FC1)# Output layerOut = Dense(units=num_classes, activation='softmax',kernel_initializer=keras.initializers.glorot_normal(seed=3),name='Output')(FC2)model1 = Model(inputs=VGG16_MODEL.input,outputs=Out)
人脸识别模型将使用迁移学习进行训练,我们将使用没有顶层的 VGG-16 模型。将在 VGG-16 模型的顶层添加自定义层,然后我们将使用此迁移学习模型来预测它是否是授权所有者的脸。自定义层由输入层组成,它基本上是 VGG-16 模型的输出。我们添加了一个带有 32 个过滤器的卷积层,kernel_size 为 (3,3),默认步幅为 (1,1),我们使用激活作为 relu,he_normal 作为初始化器。我们将使用池化层对卷积层中的层进行下采样。2 个完全连接的层与激活一起用作 relu,即在样本通过展平层后的密集架构。输出层有一个 num_classes 为 2 的 softmax 激活,它预测num_classes的概率,即授权所有者或额外的参与者或被拒绝的人脸。最终模型将输入作为 VGG-16 模型的开始,输出作为最终输出层。
在下一个代码块中,我们将查看面部识别任务所需的回调。
from tensorflow.keras.callbacks import ModelCheckpointfrom tensorflow.keras.callbacks import ReduceLROnPlateaufrom tensorflow.keras.callbacks import TensorBoardcheckpoint = ModelCheckpoint("face_rec.h5", monitor='accuracy', verbose=1,save_best_only=True, mode='auto', period=1)reduce = ReduceLROnPlateau(monitor='accuracy', factor=0.2, patience=3, min_lr=0.00001, verbose = 1)logdir='logsface'tensorboard_Visualization = TensorBoard(log_dir=logdir, histogram_freq=True)
我们将导入 3 个必需的回调来训练我们的模型:ModelCheckpoint、ReduceLROnPlateau 和 Tensorboard。
ModelCheckpoint — 此回调用于存储训练后模型的权重。我们通过指定 save_best_only=True 只保存模型的最佳权重。
ReduceLROnPlateau — 此回调用于在指定的epoch数后降低优化器的学习率。在这里,我们将耐心指定为 10。如果在 10 个 epoch 后准确率没有提高,那么我们的学习率就会相应地降低 0.2 倍。
Tensorboard — tensorboard 回调用于绘制图形的可视化,即精度和损失的图形。
='categorical_crossentropy',optimizer=Adam(lr=0.001),metrics=['accuracy'])epochs = 20model1.fit(train_generator,epochs = epochs,callbacks = [checkpoint, reduce, tensorboard_Visualization])
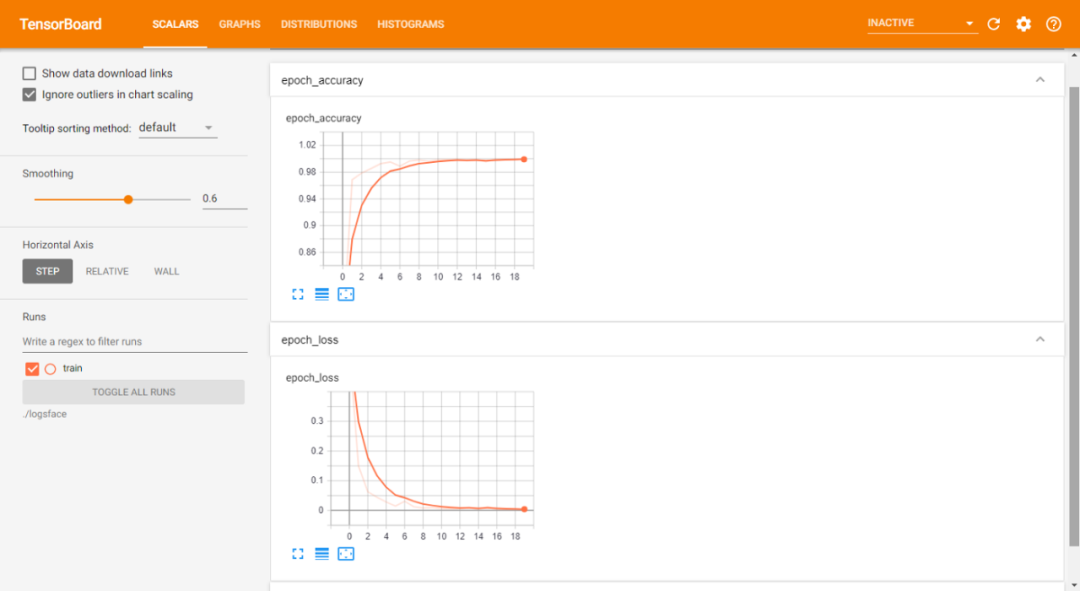
编译和拟合我们的模型。将训练模型并将最佳权重保存到 face_rec.h5,这样就不必反复重新训练模型,并且可以在需要时使用我们保存的模型。本文使用的损失是 categorical_crossentropy,它计算标签和预测之间的交叉熵损失。我们将使用的优化器是 Adam,其学习率为 0.001,我们将根据度量精度编译我们的模型。我们将在增强的训练图像上拟合数据。在拟合步骤之后,这些是我们能够在训练损失和准确性方面取得的结果:

训练数据表:
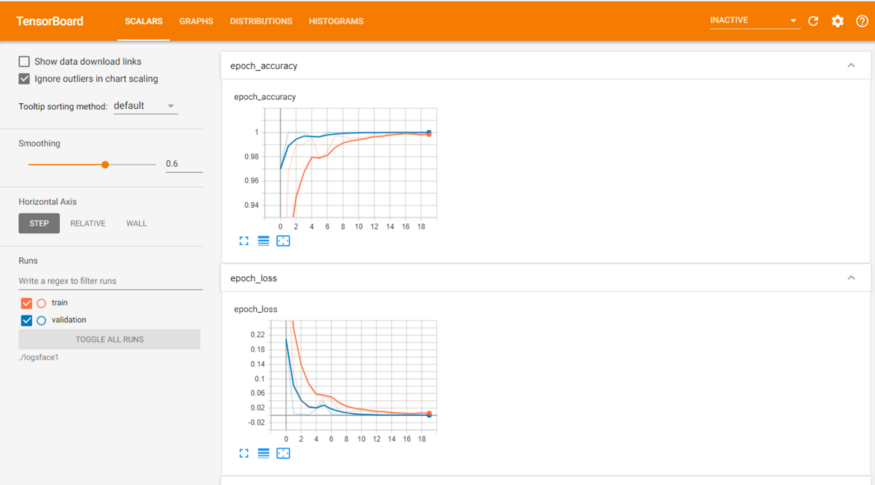
训练和验证数据表:
本文GITHUB代码链接:
https://github.com/Bharath-K3/Smart-Face-Lock-System
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~