
向高手学习:glib如何来封装跨平台的线程库
一、前言
二、glib 简介
三、线程库的设计
四、总结
一、前言
这篇文章,按照下面这 2 张图,来描述 glib 在 Linux 和 Windows 平台上,是如何来进行线程库的设计的。
Linux 平台:
Windows 平台:
最近写了几篇关于跨平台的应用程序设计思路,有些小伙伴在后台留言询问关于一些通用的跨平台库,看来这方面的需求还是很多的。
所谓的跨平台,无非就是希望用同一份应用程序的代码,可以编译出在多个平台上运行的可执行程序。
那么如何才能做到应用程序代码的平台无关呢?很明显需要中间的一个桥接层,把自己不想处理的、那些与平台相关的、烦人的代码丢给这个中间层去处理。

简单的说:就是那些需要处理与平台相关的脏活、累活,都由这个中间层帮你做好了,我们在写应用程序时,只需要关心自己的业务层事务就可以了。
如果没有这个中间层的话,你的代码中可能会充斥着大量的#if...#else代码。
而 glib 就是这样的一个中间层跨平台库,它提供了很多常用的封装,线程库只是其中的封装之一,这篇文章我们主要来学习一下 glib 是如何来设计跨平台的线程库。
二、glib 简介
第一眼看上去的时候,很容易把 glib 与 glibc 混淆,它俩都是基于 GPL 的开源软件,但是却属于完全不同的概念。
glibc是GNU实现的一套标准C的函数库,而glib是gtk+的一套函数库。
那么 gtk+ 是什么呢?使用 Linux 的小伙伴一定知道 gnome 这个桌面环境,gnome 就是基于 gtk+ 开发的一套桌面系统,而 glib 就是位于 gtk 后面的那位无名英雄。

glib可以在多个平台下使用,比如Linux、Unix、Windows等。glib为许多标准的、常用的 C 语言结构提供了相应的替代物。
作为一名 C 语言开发者,有时候我们会非常的羡慕 C++ 开发者,标准库(SDL)有辣么多的工具可用:链表、向量、字符串处理。。。
可是 C 语言里呢?哪哪都要自己去实现这些轮子。
不过反过来说,如果我们在日常的开发过程中,把自己编写的、从别处借鉴的那些好用的轮子都积累起来,形成自己的“宝库”,这也是一种经验的体现、也是一种竞争力。
如今,在 github 上也有很多雷锋实现了高质量的 C 库:有专注于跨平台的、有专注于某个领域的(比如:网络处理、格式化文本解析)。
glib 在解决跨平台的同时,也提供了其他很多有用的工具箱,例如:事件循环、线程池、同步队列、内存管理等等。
既然它提供的功能多,那么必然会导致体积比较大。这也是很多开发者面对不同的选择时,放弃 glib 的原因。
不管如何,既然 glib 这么厉害,我们可以来学习它的设计思想,这可是比盲目的敲几千行代码更能提升一个人的元技能!
三、线程库的设计
1. 线程相关的文件
在 Linux 系统中,创建线程一般都是通过 POSIX 接口(可移植操作系统接口),例如:创建线程 API 函数是 pthread_create(...)。
在 Windows 系统中,创建线程有好几种方式:
CreateThread()
_beginthread()
既然 glib 库时专门用来解决跨平台问题的,那么它向上面对应用层程序时,一定是提供一个统一的接口;而向下面对不同的操作系统时,调用不同系统中的线程函数。
glib 把这些线程相关的操作分别封装在了平台相关的代码中,具体来说如下图:

Linux 系统:gthread.c, gthread_posix.c 参与编译,生成 glib 库;
Windows 系统:gthread.c, gthread_win32.c 参与编译,生成 glib 库;
关于这种跨平台的文件构建方式(也就是编译啦),建议您看一下这篇小短文:跨平台代码的3种组织方式
2. 数据结构
你一定听说过这个公式:程序 = 数据结构 + 算法,对于一个 C 语言项目,明白了数据结构的设计,对于理解整个程序的思路是非常重要的,在 glib 中也是如此。
glib 在设计线程库的时候,分成 2 个层次:平台无关部分,平台相关部分。
平台无关的数据结构有(一些不影响理解的代码就删掉了):
struct _GThread
{
GThreadFunc func;
gpointer data;
gboolean joinable;
};
typedef struct _GThread GThread;
struct _GRealThread
{
GThread thread;
gint ref_count;
gchar *name;
};
typedef struct _GRealThread GRealThread;
平台相关的数据结构有:
Linux 系统:
typedef struct
{
GRealThread thread;
pthread_t system_thread;
gboolean joined;
GMutex lock;
void *(*proxy) (void *);
const GThreadSchedulerSettings *scheduler_settings;
} GThreadPosix;
Windows 系统:
typedef struct
{
GRealThread thread;
GThreadFunc proxy;
HANDLE handle;
} GThreadWin32;
仔细看一下每个结构体的第一个成员变量,是不是发现点什么?
从层次关系上看,这几个结构体的关系为:
Linux 平台:

Windows 平台:

结构体在内存模型中意味着什么?占据一块内存空间。
而这几个数据结构都把"子"结构体,放在"父"结构体的第一个位置,就可以方便的进行强制类型转换。

在以上内存模型中,GRealThread 结构体的第一部分是 GThread,那么就完全可以把 GRealThread 所处内存的开始部分,当做一个 GThread 结构体变量来操作。
用 C++ 中面向对象的术语来描述更准确:基类指针可以指向派生类对象。
在下面的代码中,可以看到这样的操作。
3. 线程的创建
(1) 函数原型
平台无关函数(gthread.c 中实现)
GThread *g_thread_new (const gchar *name,
GThreadFunc func,
gpointer data);
GThread *
g_thread_new_internal (const gchar *name,
GThreadFunc proxy,
GThreadFunc func,
gpointer data,
gsize stack_size,
const GThreadSchedulerSettings *scheduler_settings,
GError **error);
平台相关函数(gthread_posix.c or ghread_win32.c 中实现)
GRealThread *
g_system_thread_new (GThreadFunc proxy,
gulong stack_size,
const GThreadSchedulerSettings *scheduler_settings,
const char *name,
GThreadFunc func,
gpointer data,
GError **error);
(2) Linux 平台函数调用链
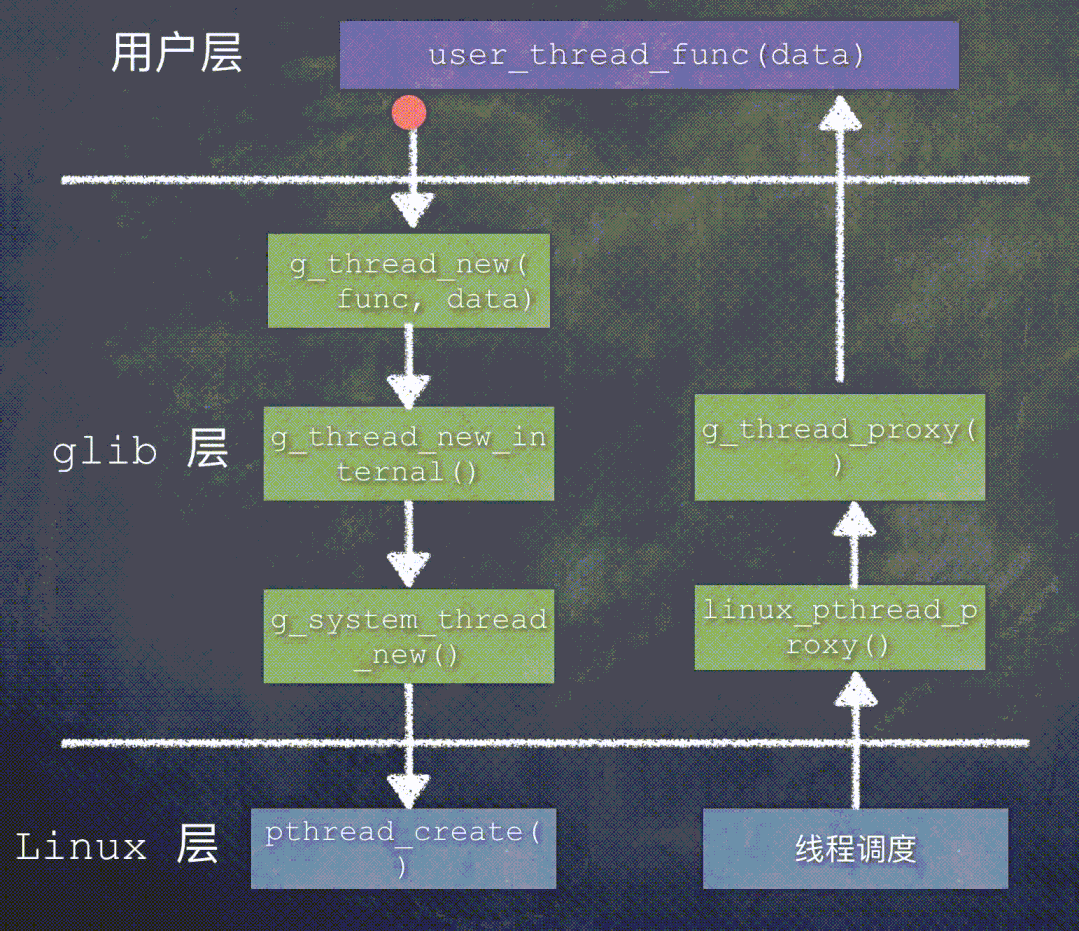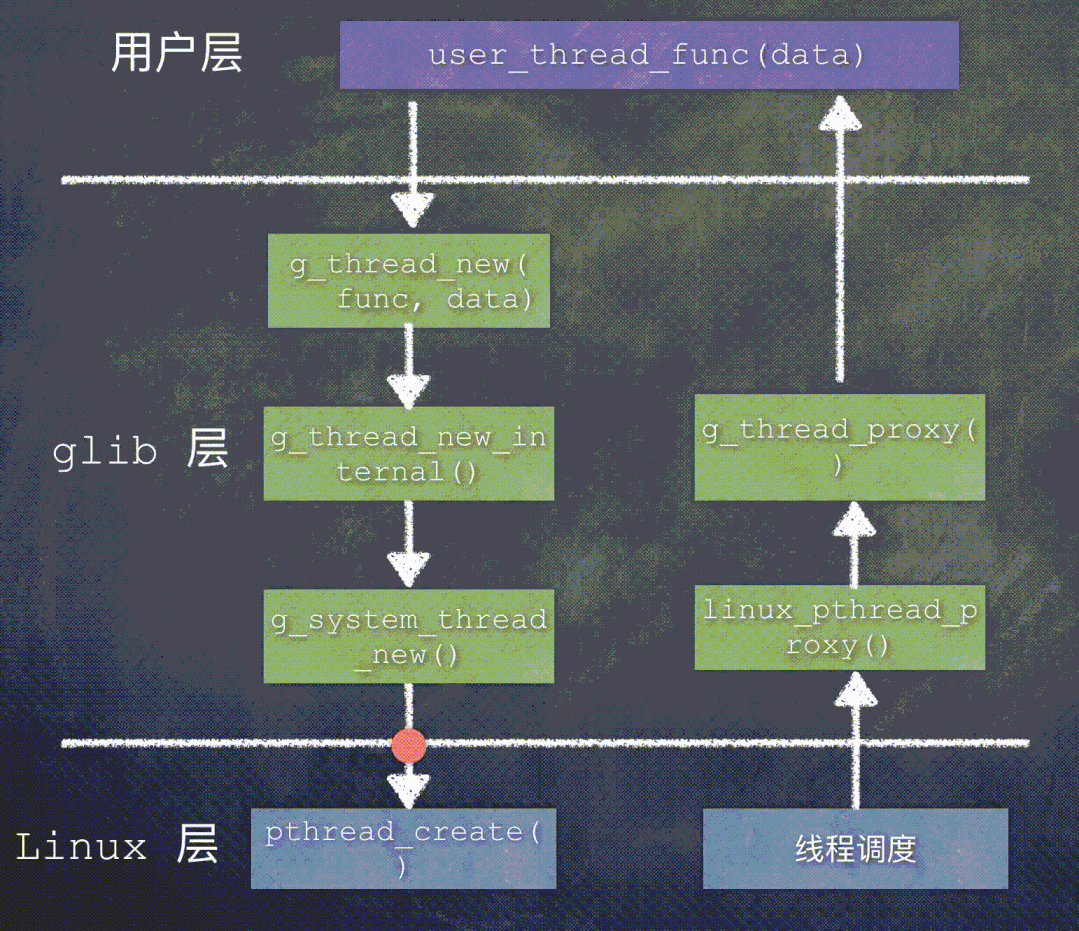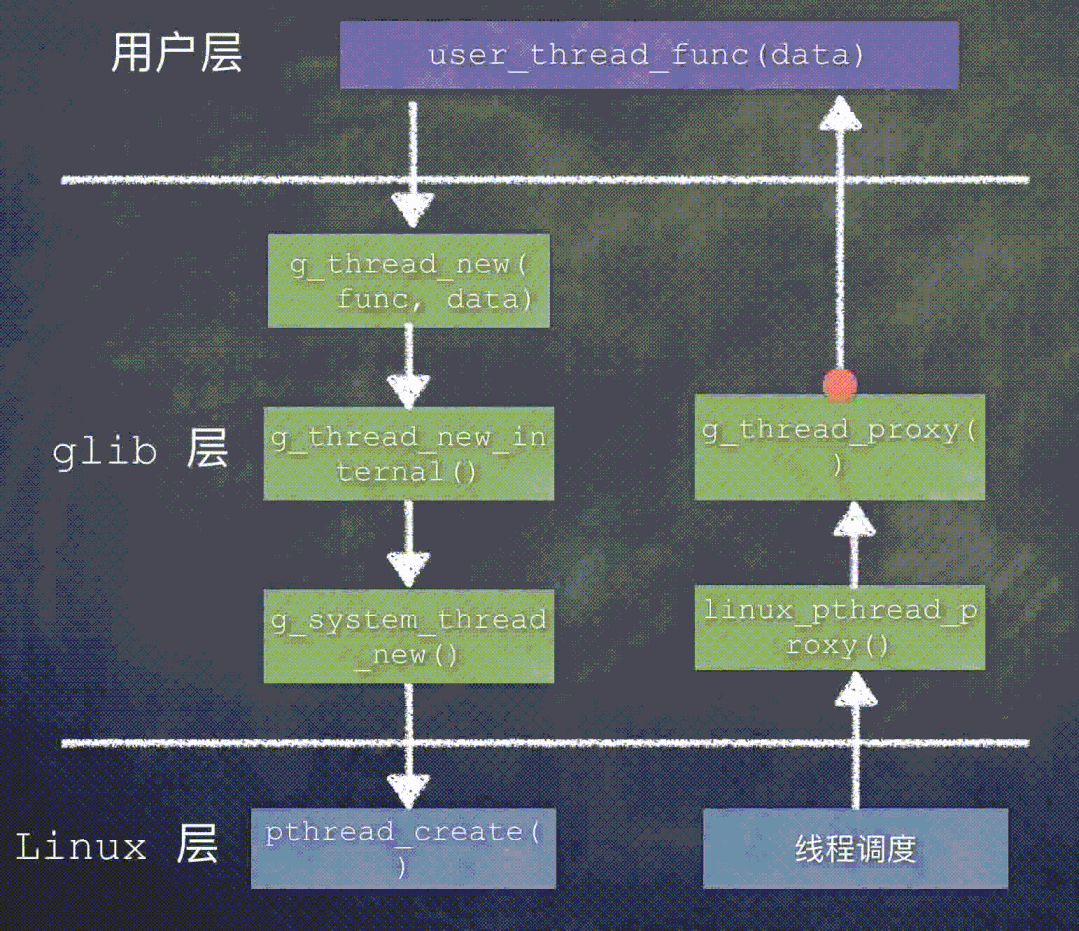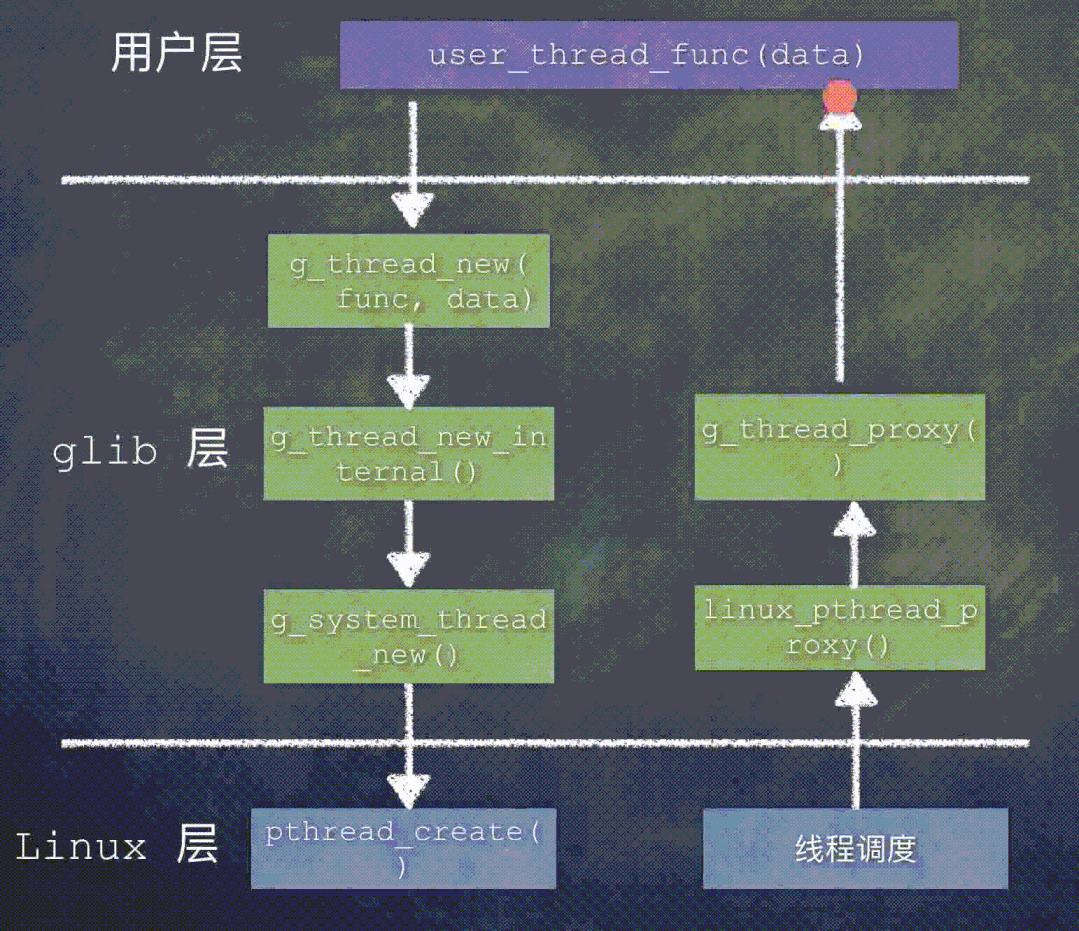
先来看一下 Linux 平台上的函数调用关系:
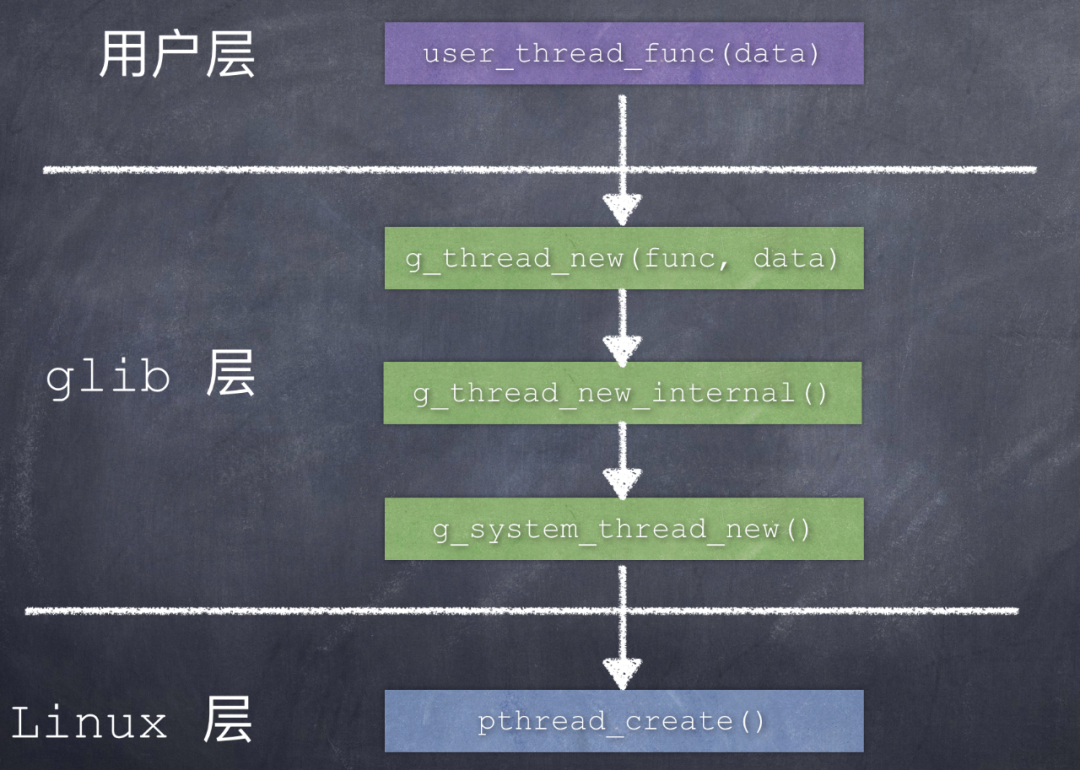
如果你的手边有源代码,请关注 g_thread_new() 这个函数中的 func 和 data 这2个参数。
func 是最开始用户层传入的线程执行函数,也就是用户创建这个线程,最终想执行的函数。data 是 func 函数所接收的函数参数。
如果直接面对 Linux 操作系统编程,在调用 POSIX 接口函数 pthread_create() 时,一般是直接传入用户想要执行的函数以及参数。
但是 glib 层并没有直接把用户层的函数直接交给 Linux 操作系统,而是自己提供了 2 个线程代理函数,在调用 pthread_create() 时,根据不同的情况,把这2个代理函数之一传递给操作系统:
第一个线程代理函数:g_thread_proxy();
第二个线程代理函数:linux_pthread_proxy();
至于传递哪一个代理函数,取决于宏定义 HAVE_SYS_SCHED_GETATTR 是否有效。
下面是 g_system_thread_new() 函数简化后的代码:
g_system_thread_new (proxy, stack_size, scheduler_settings,
name, func, data, error);
GThreadPosix *thread;
GRealThread *base_thread;
// 填充 base_thread 字段,重点关注下面2句
base_thread->thread.func = func;
base_thread->thread.data = data;
thread->scheduler_settings = scheduler_settings;
thread->proxy = proxy;
#if defined(HAVE_SYS_SCHED_GETATTR)
ret = pthread_create (&thread->system_thread, &attr, linux_pthread_proxy, thread);
#else
ret = pthread_create (&thread->system_thread, &attr, (void* (*)(void*))proxy, thread);
#endif
4. 线程的执行
我们就假设这个宏定义 HAVE_SYS_SCHED_GETATTR 被定义了、是有效的,Linux 系统中的 pthread_create() 接收到 linux_pthread_proxy() 函数。
当这个新建的线程被调度执行时,linux_pthread_proxy() 函数被调用执行:
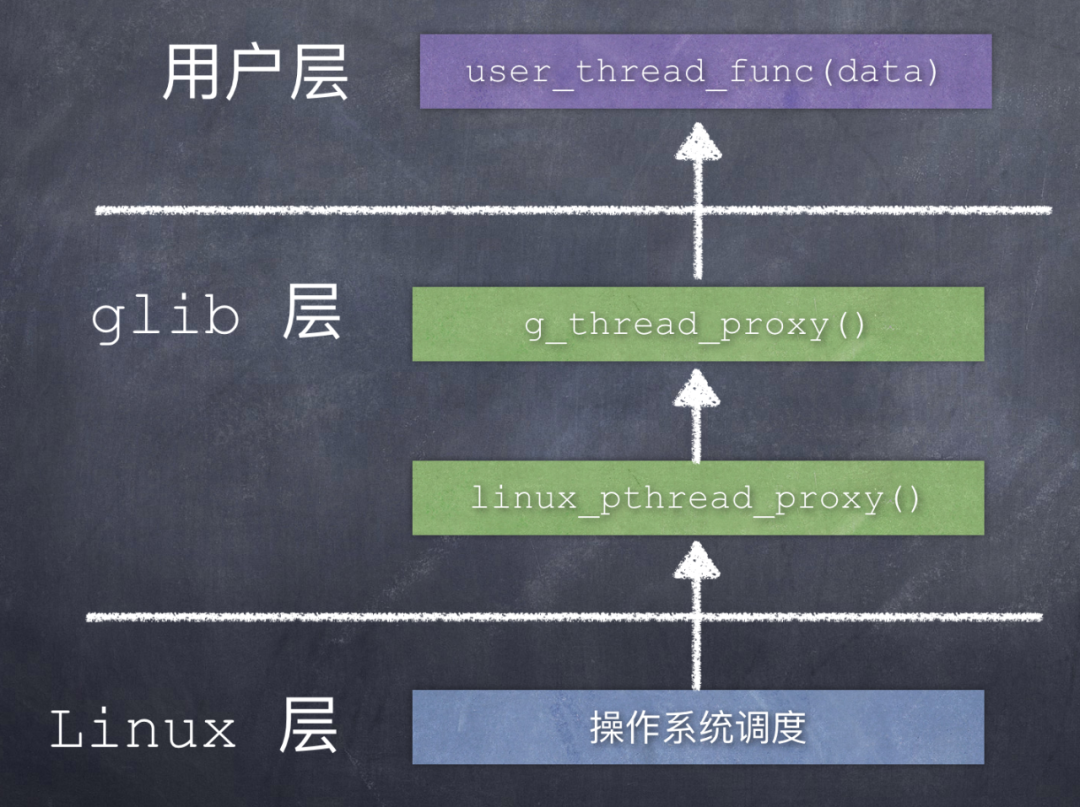
简化后的 linux_pthread_proxy() 函数:
static void *
linux_pthread_proxy (void *data)
{
// data 就是 g_system_thread_new 中 GThreadPosix 类型指针,这是平台相关的。
GThreadPosix *thread = data;
if (thread->scheduler_settings)
{
// 设置线程属性
tid = (pid_t) syscall (SYS_gettid);
res = syscall (SYS_sched_setattr, tid, thread->scheduler_settings->attr, flags);
}
// 调用 glib 中的线程代理函数,其实就是 g_thread_proxy()
return thread->proxy (data);
}
这个函数关注 3 点:
data参数: 就是g_system_thread_new函数中的GThreadPosix类型指针,这是平台相关的。中间部分是设置线程属性;
最后的
return语句,调用了 glib 中第一个线程代理函数g_thread_proxy。
继续贴一下这个函数的简化后代码:
gpointer
g_thread_proxy (gpointer data)
{
// data 就是 g_system_thread_new 中 GThreadPosix 类型指针,这是平台相关的。
// 这里把它强转成平台无关的 GRealThread 类型。
GRealThread* thread = data;
if (thread->name)
{
// 设置线程属性:名称
g_system_thread_set_name (thread->name);
}
// 调用应用层的线程入口函数
thread->retval = thread->thread.func (thread->thread.data);
return NULL;
}
这个函数也只要关注 3 点:
data参数:linux_pthread_proxy函数传过来的是GThreadPosix类型指针,但是这里直接赋值给了GRealThread类型的指针,因为它们的内存模型是包含的关系;中间部分是设置线程名称;
最后的
thread->thread.func (thread->thread.data)语句,调用了用户最开始传入的函数并传递用户的data参数。
至此,用户层定义的线程函数 user_thread_func(data) 就得以执行了。
那么,如果 glib 层没有定义宏 HAVE_SYS_SCHED_GETATTR,那么 Linux 系统中 pthread_create() 接收到的就是 glib 中的第一个线程代理函数 g_thread_proxy。
线程执行的调用关系为:
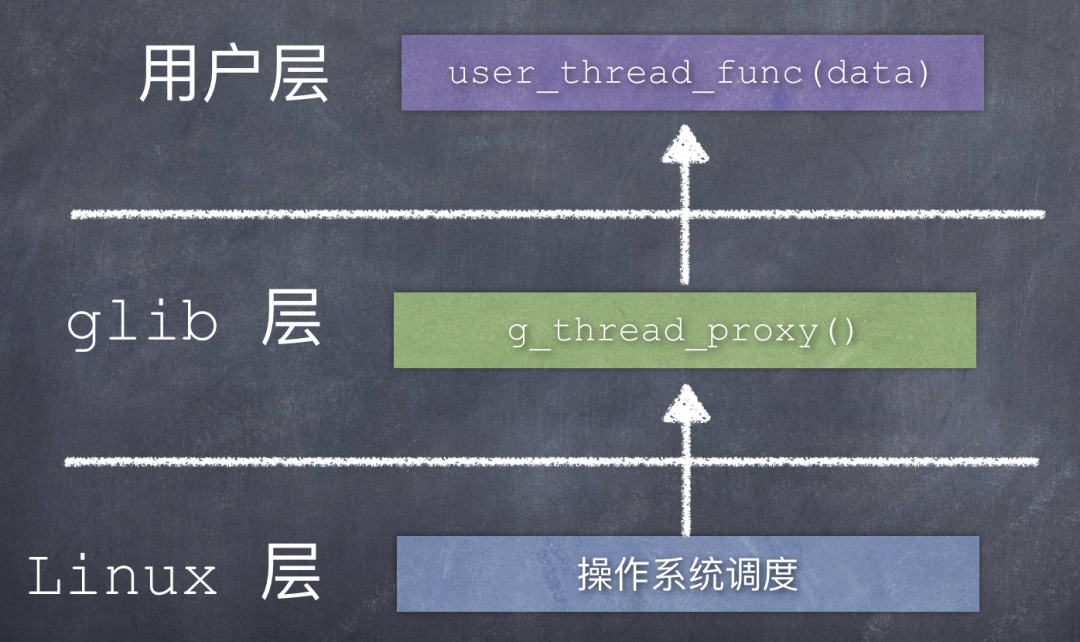
5. Windows平台函数调用链
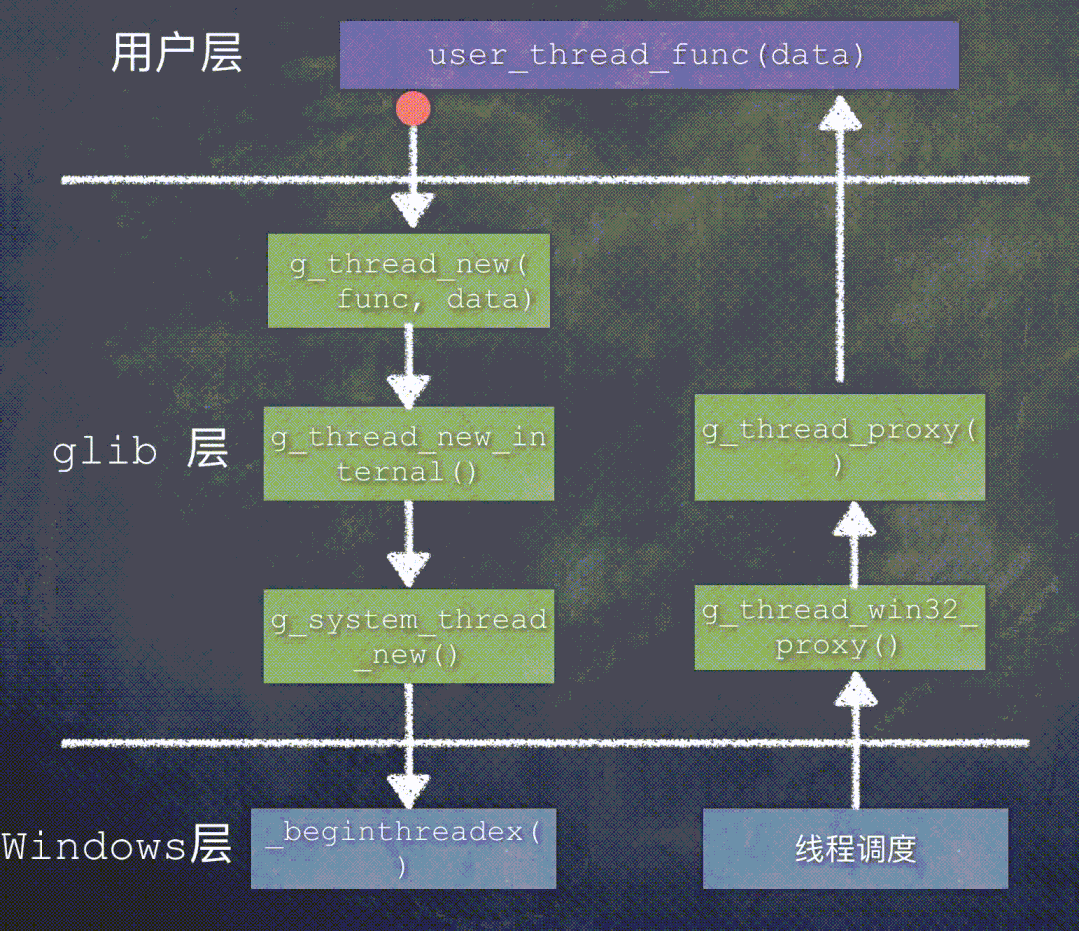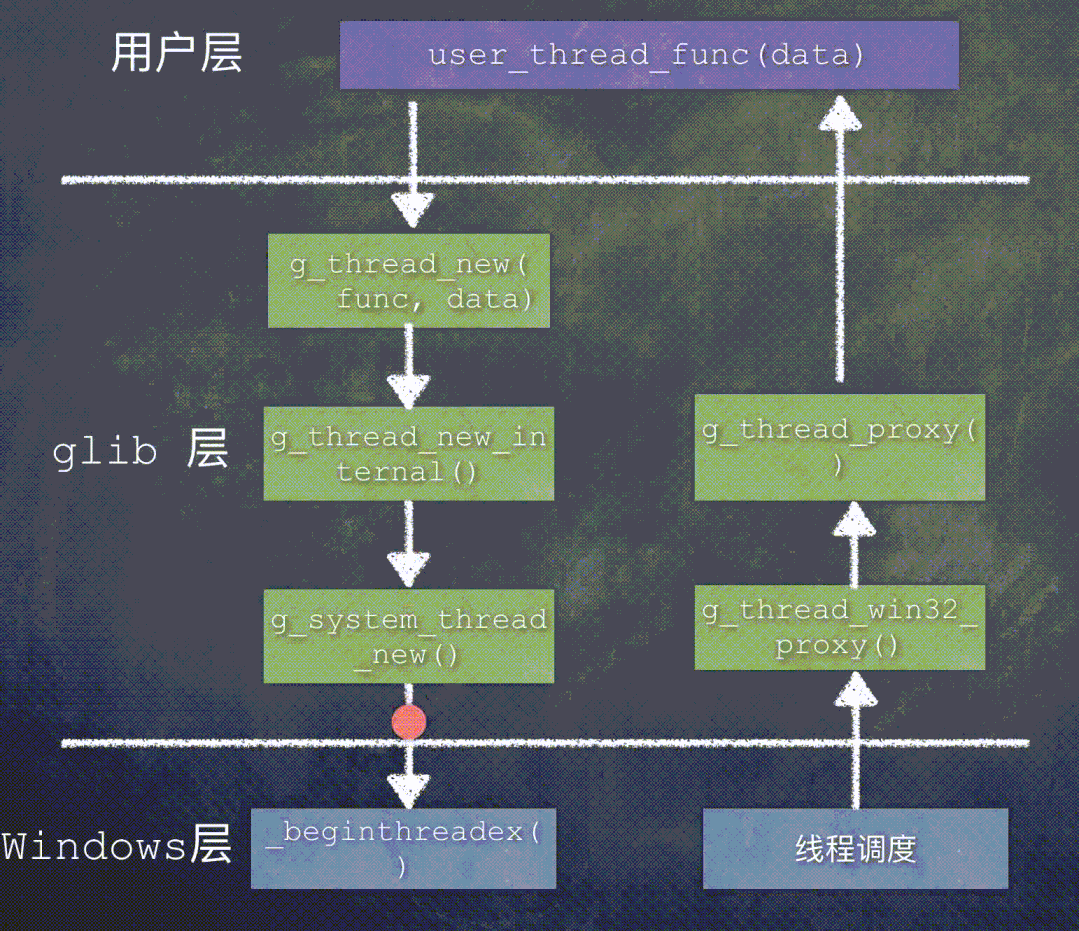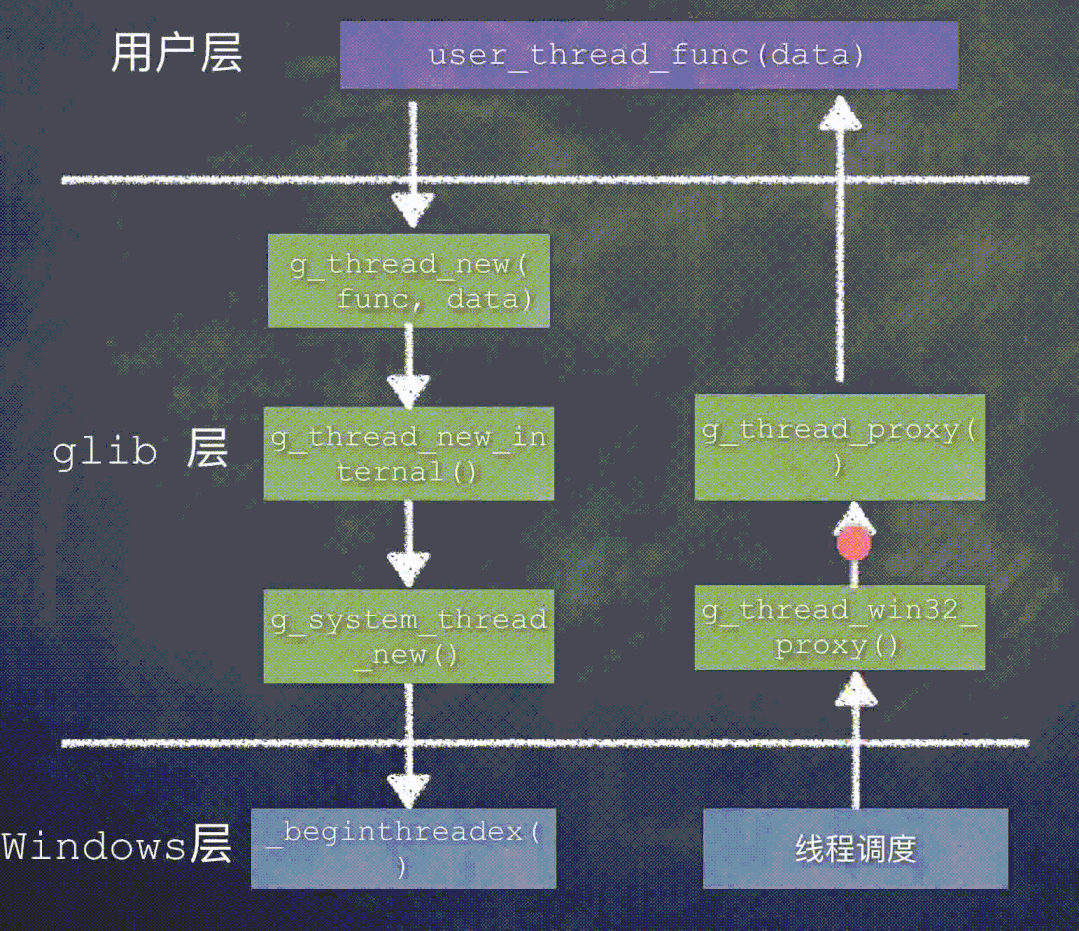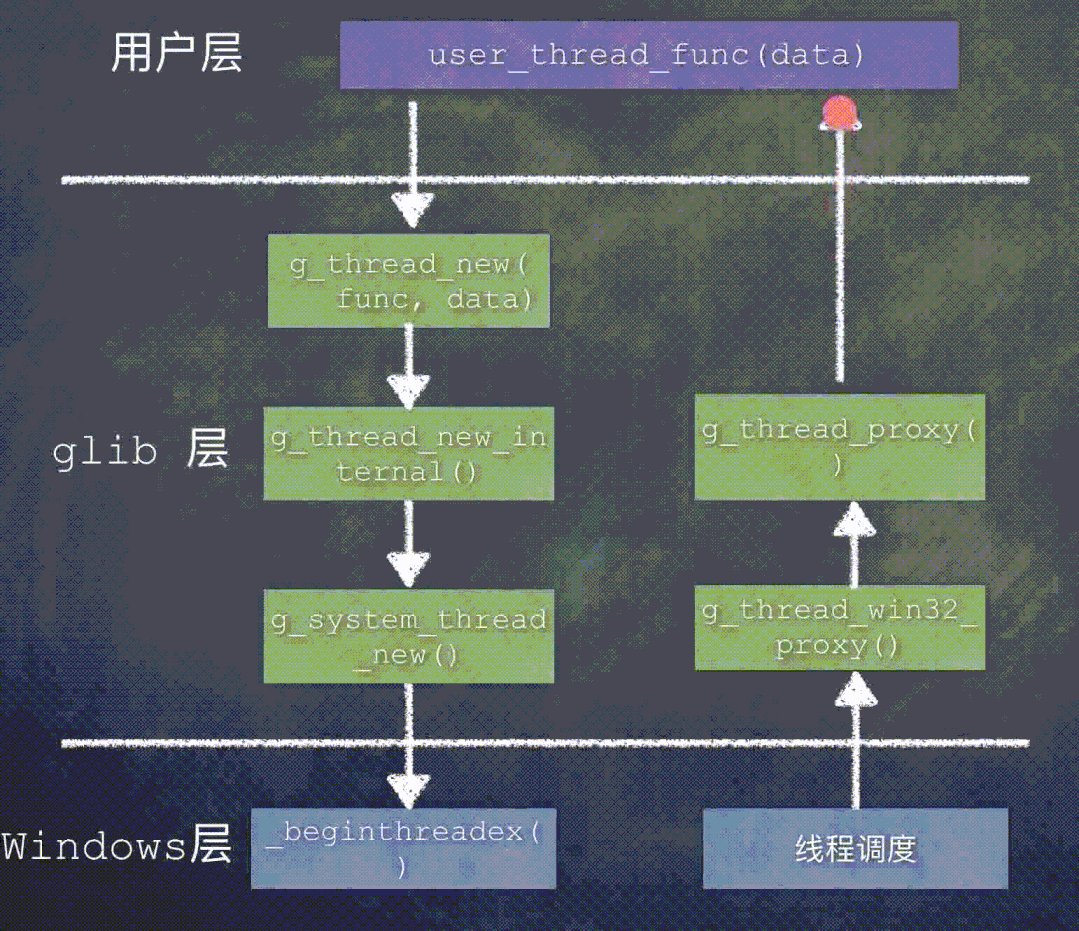
先来看一下 Windows 平台上创建线程时函数调用关系:
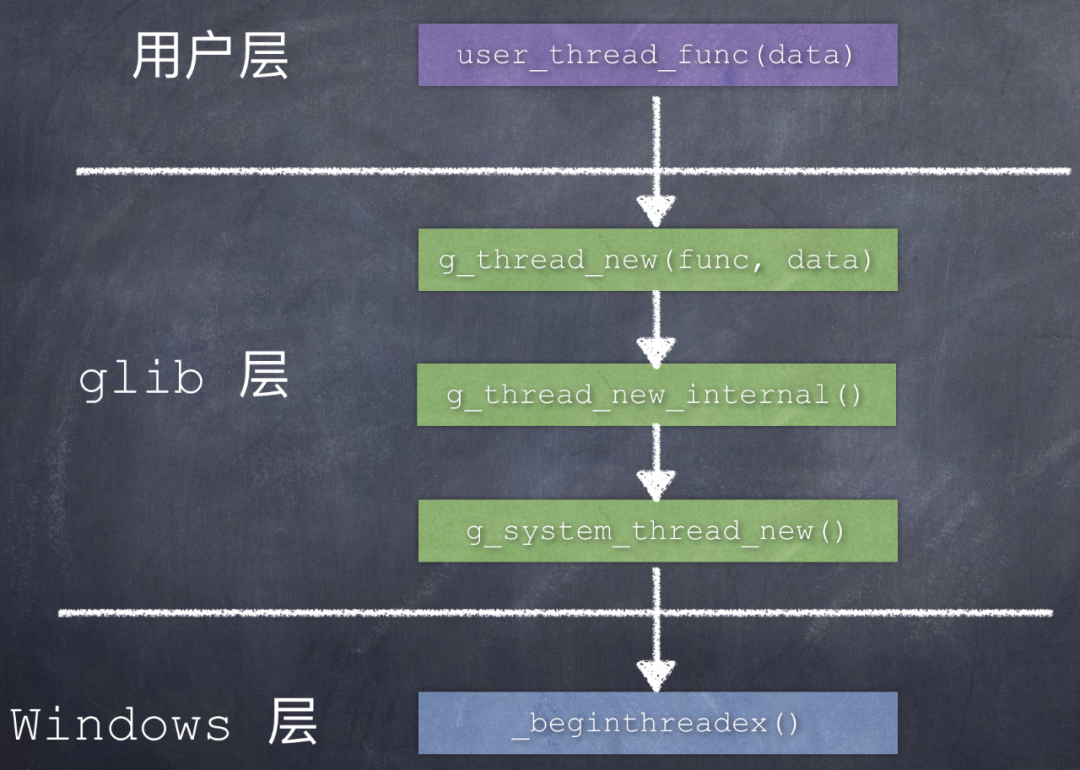
在 Windows 平台上,glib 的线程代理函数是 g_thread_win32_proxy()。
当这个新建的线程被调度执行时,函数调用关系是:
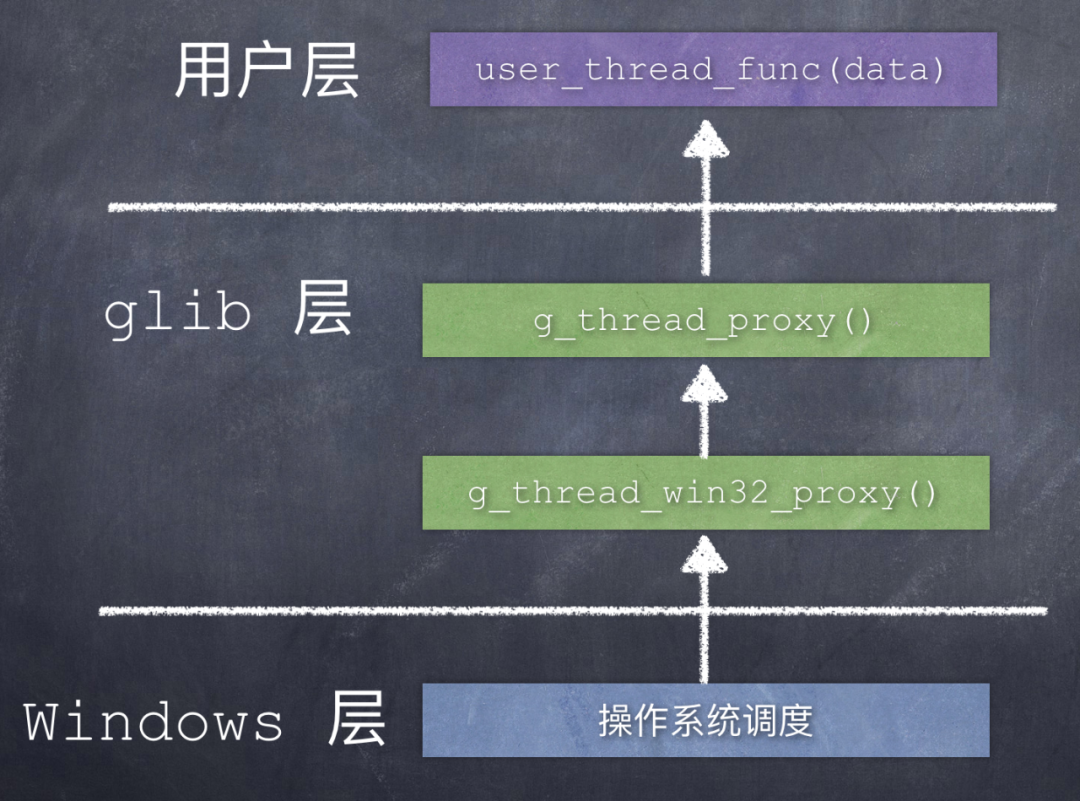
四、总结
实现这样的线程函数代理设计,关键是利用了 C 语言中的结构体类型中,把“父”结构体类型变量强制转换成“子”结构体类型变量来使用,因为它俩在内存模型中,刚开始部分的空间中,内容是完全一样的。
最后,我把文中的这些图合并起来,绘制成下面这 2 张图,完整的体现了 glib 中的线程设计思路:
Linux 平台:
Windows 平台:
让知识流动起来,越分享,越幸运!
星标公众号,能更快找到我!
【1】C语言指针-从底层原理到花式技巧,用图文和代码帮你讲解透彻
【2】一步步分析-如何用C实现面向对象编程
【3】原来gdb的底层调试原理这么简单
【4】内联汇编很可怕吗?看完这篇文章,终结它!
【5】都说软件架构要分层、分模块,具体应该怎么做