
强化学习也有基础模型了!DeepMind重磅发布AdA,堪比人类的新环...

新智元报道
编辑:LRS
【新智元导读】强化学习也要进入预训练时代了!
基础模型(foundation models)
在监督和自监督学习问题上展现出强大的领域适应性(adaption)和可扩展性(scalability),但强化学习领域仍然没有基础模型。
最近DeepMind的Adaptive Agents团队提出了一种
人-时间尺度(human-timescale)自适应智能体AdA(Adaptive Agent)
,证明经过大规模训练后的RL智能体也能具有通用上下文的学习能力,该算法可以像人一样快速适应开放式的具身3D问题。
 论文链接:https://arxiv.org/abs/2301.07608
论文链接:https://arxiv.org/abs/2301.07608在一个巨大的动态空间环境中,自适应智能体展现出即时的假设驱动的探索,能够有效地利用获得的知识,而且可以接受第一人称演示作为提示(prompt)。
研究人员认为其适应性主要来源于
三个因素
:
1. 在一个巨大的、平滑的和多样化的任务分布中进行元强化学习;
2. 一个参数化的、基于注意力的大规模记忆结构的策略;
3. 一个有效的自动curriculum,在代理能力的前沿对任务进行优先排序。
实验部分展示了与网络规模、记忆长度和训练任务分布的丰富程度有关的特征性扩展规律;研究人员认为该结果为日益普遍和适应性强的RL智能体奠定了基础,智能体在开放领域环境仍然表现良好。
RL基础模型
人类
往往能够在
几分钟内适应一个新的环境
,这是体现人类智能的一个关键特性,同时也是通往通用人工智能道路上的一个重要节点。
不管是何种层次的有界理性(bounded retionality),都存在一个任务空间,在这个空间中,智能体无法以zero-shot的方式泛化其策略;但如果智能体能够非常快速地从反馈中学习,那么就可能取得性能提升。
为了在现实世界中以及在与人类的互动中发挥作用,人工智能体应该能够在「几次互动」中进行快速且灵活的适应,并且应该在可用数据量提升时继续适应。
具体来说,研究人员希望训练出的智能体在测试时,只需要在一个未见过的环境中给定几个episode的数据,就能完成一个需要试错探索的任务,并能随后将其解决方案完善为最佳的行为。
元强化学习(Meta-RL)
已经被证明对快速的语境适应是有效的,然而,不过元RL在奖励稀疏、任务空间巨大且多样化的环境中作用有限。
这项工作为训练RL基础模型铺平了道路;也就是说,一个已经在庞大的任务分布上进行了预训练的智能体,在测试时,它能以few-shot的方式适应广泛的下游任务。
自适应智能体(AdA)能够在具有稀疏奖励的巨大开放式任务空间中进行人类时间尺度适应,不需要任何提示、微调或访问离线数据集。
相反,AdA表现出假设驱动的探索行为,利用即时获得的信息来完善其策略,能够有效地获取知识,在第一人称像素观察的部分可观察的三维环境中,在几分钟内适应奖励稀疏的任务。
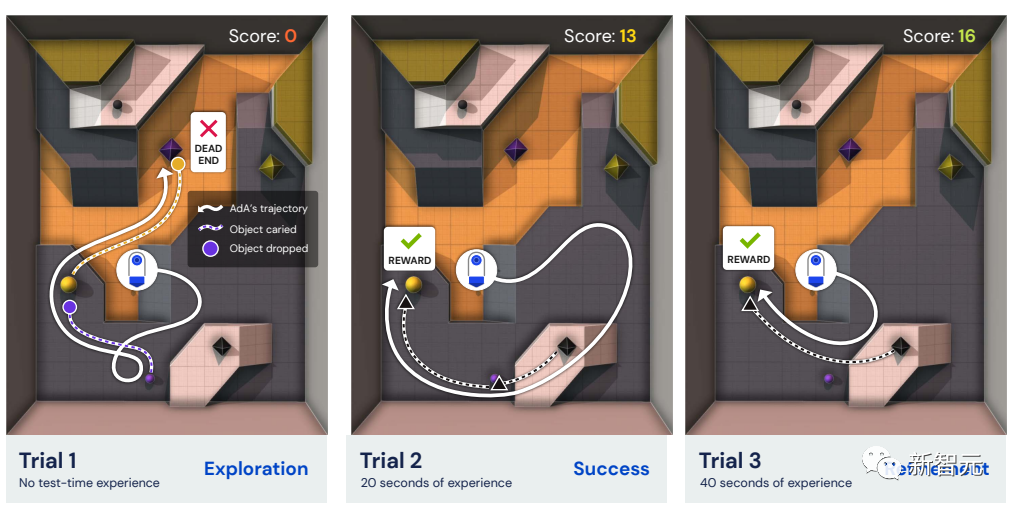
自适应智能体Ada
研究人员提出了一种基于记忆的元RL通用和可扩展的方法以生成自适应智能体(AdA)
首先在XLand 2.0中训练和测试AdA,该环境支持按程序生成不同的三维世界和多人游戏,具有丰富的动态性,需要智能体拥有足够的适应性。
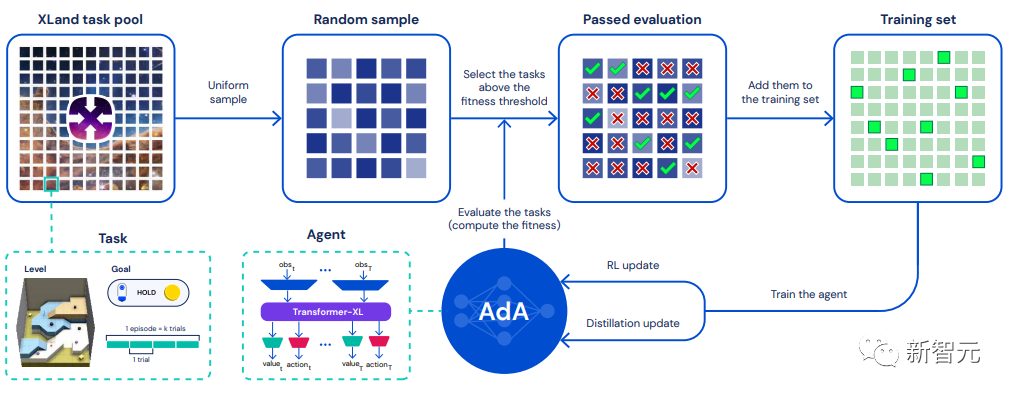
该训练方法结合了三个关键部分:1)指导智能体学习的课程(curriculum);2)基于模型的RL算法来训练具有大规模注意力记忆的代理;以及,3)蒸馏以实现扩展。
1. 开放端任务空间:XLand 2.0
XLand 2.0相比XLand 1.0扩展了生产规则的系统,其中每条规则都表达了一个额外的环境动态,从而具有更丰富、更多样化的不同过渡功能。
XLand 2.0是一个巨大的、平滑的、多样化的适应问题的任务空间,不同的任务有不同的适应性要求,如实验、工具用法或分工等。
例如,在一个需要实验的任务中,玩家可能需要识别哪些物体可以有用地结合,避免死胡同,然后优化他们结合物体的方式,就像一个玩具版的实验化学。
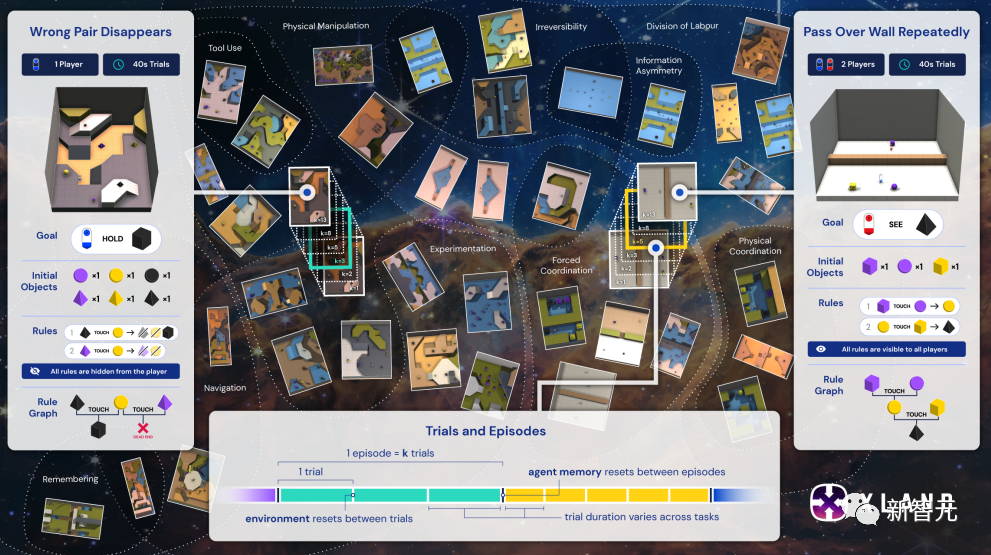
每个任务可以进行一次或多次试验,试验之间的环境会被重置,但智能体记忆不会被重置。
上图中突出显示的是两个示例任务,即「Wrong Pair Disappears」和「Pass Over Wall Repeatedly」,展示了目标、初始物体、生产规则以及智能体需要如何与它们互动以解决任务。
2. 元强化学习
根据黑箱元RL问题的设置,研究人员将任务空间定义为一组部分可观察的马尔科夫决策过程(POMDPs)。
对于一个给定的任务,试验的定义为从初始状态到终端状态的任意转换序列。
在XLand中,当且仅当某个时间段𝑇∈[10s, 40s]已经过去时,任务才会终止,每个任务都有具体规定。环境以每秒30帧的速度变化,智能体每4帧观察一次,因此任务长度以时间为单位,范围为[75, 300]。
一个episode由一个给定任务的试验序列组成。在试验边界,任务被重置到一个初始状态。
在领域内,初始状态是确定的,除了智能体的旋转,它是统一随机抽样的。
在黑箱元RL训练中,智能体利用与广泛分布的任务互动的经验来更新其神经网络的参数,该网络在给定的状态观察中智能体的行动政策分布提供参数。
如果一个智能体拥有动态的内部状态(记忆),那么元RL训练通过利用重复试验的结构,赋予该记忆以隐性的在线学习算法。
在测试时,这种在线学习算法使智能体能够适应其策略,而无需进一步更新神经网络权重,也就是说,智能体的记忆不是在试验边界被重置,而是在episode边界被重置。
3. 自动课程学习(Auto-curriculum learning)
鉴于预采样任务池的广度和多样性,智能体很难用均匀采样进行有效地学习:大多数随机采样的任务可能会太难(或太容易),无法对智能体的学习进度有所帮助。
相反,研究人员使用自动化的方法在智能体能力的前沿选择相对「有趣 」(interesting)的任务,类似于人类认知发展中的「近侧发展区间」(zone of proximal development)。
具体方法为对现有技术中的no-op filtering和prioritised level replay(PLR)进行扩展,能够极大提升智能体的性能和采样效率,最终成为了一个新兴的课程,能够随着时间的推移选择越来越复杂的任务。
4. RL智能体
学习算法
RL算法选择Mueslie,输入为一个历史相关的编码(history-dependent encoding),输出为RNN或Transformer,AdA学习一个序列模型(LSTM)对后续多步预测价值、行动分布和奖励。
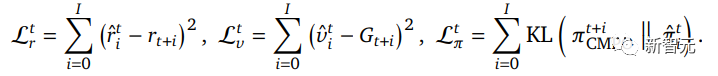
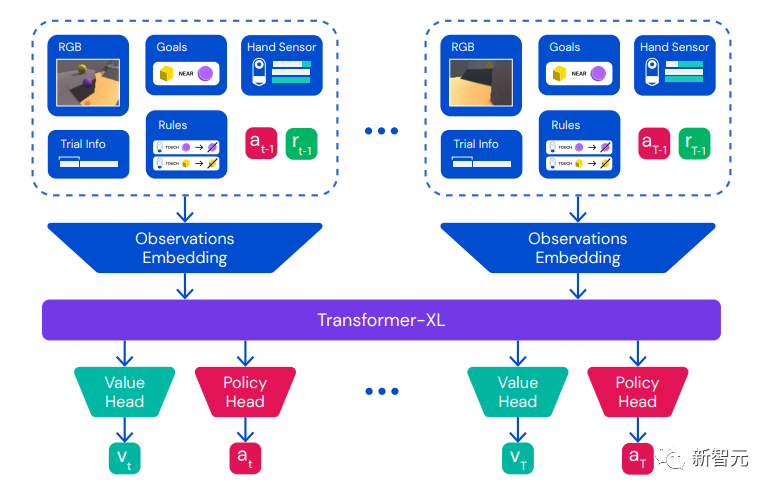
记忆架构
在每个时间步,将像素观察、目标、手、试验和时间信息、生成规则、之前的行动和奖励嵌入化并合并为一个向量。
这些观察嵌入顺序输入到Transformer-XL中,其输出嵌入输入到MLP价值头、MLP策略头和Muesli LSTM模型步、
不止few-shot
通过对Transformer-XL架构做了一个简单的修改,就可以在不增加计算成本的情况下增加有效的记忆长度。
由于在视觉RL环境中的观察往往与时间高度相关,所以研究人员提出对序列进行子采样。为了确保在子采样点之间的观察仍然可以被关注到,使用一个RNN对整个轨迹进行编码,可以总结每一步的最近历史。
结果表明,额外的RNN编码并不影响模型中Transformer-XL变体的性能,但能够保持更远的记忆。
5. 蒸馏
对于训练的前40亿步,研究人员使用一个额外的蒸馏损失用预训练教师模型的策略来指导AdA的学习,整个过程也称之为kickstarting
教师模型通过强化学习从头开始进行预训练,使用与AdA相同的训练程序和超参数,但教师模型没有初始蒸馏,并且具有较小的模型规模:教师模型只有2300万Transformer参数,而多智能体AdA拥有2.65亿参数。
在蒸馏过程中,AdA根据自己的策略行动,教师模型根据AdA观察到的轨迹提供目标Logits;使用蒸馏可以摊销昂贵的初始训练期,并使智能体能够消除在训练的初始阶段学到的有害表征。
然后将蒸馏损失与Muesli结合起来,最小化模型预测的所有行动概率与教师策略在相应时间段预测的行动概率之间的KL-散度。
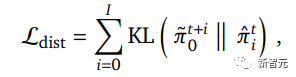
研究人员还发现了一个有用的小操作,可以在蒸馏期间添加一个额外的L2正则化项。
参考资料:
https://arxiv.org/abs/2301.07608


评论