
大数据入门:Spark+Kudu的广告业务项目实战笔记(五)
点击上方蓝色字体,选择“设为星标”




1.统计需求
本章主要实现需求四:APP统计。需求如下:
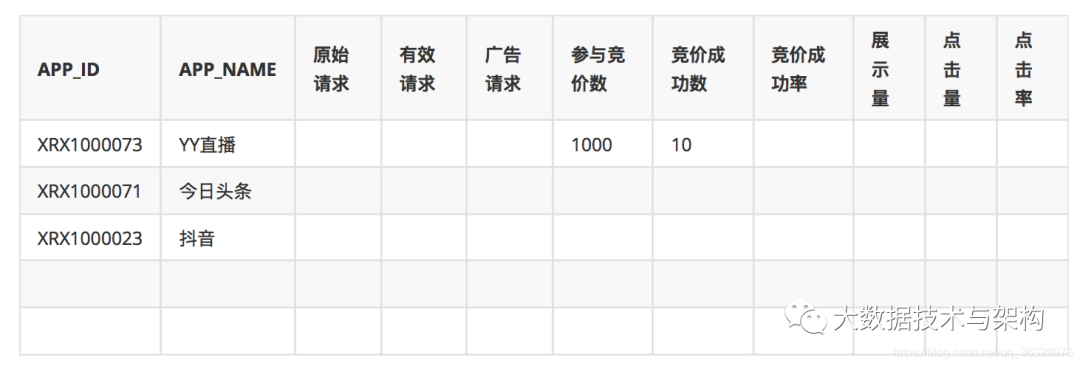
2.代码编写
入口搭好:
AppStatProcessor.process(spark)先看一下第一步的运行情况:
package com.imooc.bigdata.cp08.businessimport com.imooc.bigdata.cp08.`trait`.DataProcessimport com.imooc.bigdata.cp08.utils.SQLUtilsimport org.apache.spark.sql.SparkSessionobject AppStatProcessor extends DataProcess{override def process(spark: SparkSession): Unit = {val sourceTableName = "ods"val masterAddresses = "hadoop000"val odsDF = spark.read.format("org.apache.kudu.spark.kudu").option("kudu.table",sourceTableName).option("kudu.master",masterAddresses).load()odsDF.createOrReplaceTempView("ods")val resultTmp = spark.sql(SQLUtils.APP_SQL_STEP1)resultTmp.show()}}
其中SQL代码如下:
lazy val APP_SQL_STEP1 = "select appid,appname, " +"sum(case when requestmode=1 and processnode >=1 then 1 else 0 end) origin_request," +"sum(case when requestmode=1 and processnode >=2 then 1 else 0 end) valid_request," +"sum(case when requestmode=1 and processnode =3 then 1 else 0 end) ad_request," +"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and isbid=1 and adorderid!=0 then 1 else 0 end) bid_cnt," +"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 then 1 else 0 end) bid_success_cnt," +"sum(case when requestmode=2 and iseffective=1 then 1 else 0 end) ad_display_cnt," +"sum(case when requestmode=3 and processnode=1 then 1 else 0 end) ad_click_cnt," +"sum(case when requestmode=2 and iseffective=1 and isbilling=1 then 1 else 0 end) medium_display_cnt," +"sum(case when requestmode=3 and iseffective=1 and isbilling=1 then 1 else 0 end) medium_click_cnt," +"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 and adorderid>20000 then 1*winprice/1000 else 0 end) ad_consumption," +"sum(case when adplatformproviderid>=100000 and iseffective=1 and isbilling=1 and iswin=1 and adorderid>20000 then 1*adpayment/1000 else 0 end) ad_cost " +"from ods group by appid,appname"
结果:
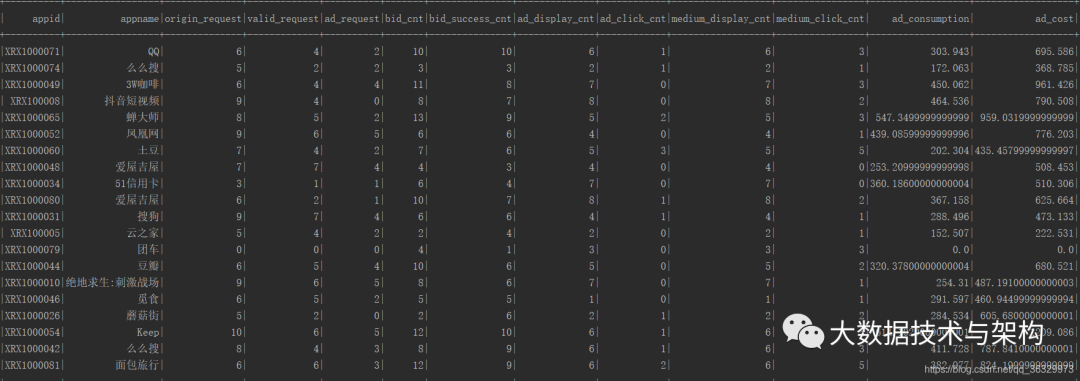
没毛病就往下跑第二个SQL,具体做法和需求三区别不大:
resultTmp.createOrReplaceTempView("app_tmp")val result = spark.sql(SQLUtils.APP_SQL_STEP2)result.show()
第二个SQL如下:
lazy val APP_SQL_STEP2 = "select appid,appname, " +"origin_request," +"valid_request," +"ad_request," +"bid_cnt," +"bid_success_cnt," +"bid_success_cnt/bid_cnt bid_success_rate," +"ad_display_cnt," +"ad_click_cnt," +"ad_click_cnt/ad_display_cnt ad_click_rate," +"ad_consumption," +"ad_cost from app_tmp " +"where bid_cnt!=0 and ad_display_cnt!=0"
然后run一下,都可以就可以写入Kudu了。
3.落地Kudu
val sinkTableName = "app_stat"val partitionId = "appid"val schema = SchemaUtils.APPSchemaKuduUtils.sink(result,sinkTableName,masterAddresses,schema,partitionId)spark.read.format("org.apache.kudu.spark.kudu").option("kudu.master",masterAddresses).option("kudu.table",sinkTableName).load().show()
schema:
lazy val APPSchema: Schema = {val columns = List(new ColumnSchemaBuilder("appid", Type.STRING).nullable(false).key(true).build(),new ColumnSchemaBuilder("appname", Type.STRING).nullable(false).key(true).build(),new ColumnSchemaBuilder("origin_request", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("valid_request", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ad_request", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("bid_cnt", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("bid_success_cnt", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("bid_success_rate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("ad_display_cnt", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ad_click_cnt", Type.INT64).nullable(false).build(),new ColumnSchemaBuilder("ad_click_rate", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("ad_consumption", Type.DOUBLE).nullable(false).build(),new ColumnSchemaBuilder("ad_cost", Type.DOUBLE).nullable(false).build()).asJavanew Schema(columns)}
看下结果:

OK收工!


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
本文编辑:冷眼丶
微信公众号|import_bigdata
文章不错?点个【在看】吧! ?
评论