Datax3.0+DataX-Web打造分布式可视化ETL系统
全网最全大数据面试提升手册!
一、DataX 简介
DataX 是阿里云 DataWorks 数据集成的开源版本,主要就是用于实现数据间的离线同步。DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源(即不同的数据库) 间稳定高效的数据同步功能。
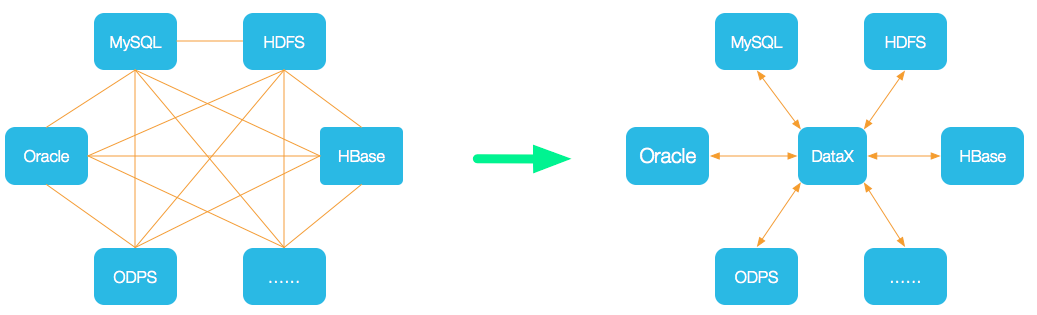
为了解决异构数据源同步问题,DataX将复杂的网状同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源;当需要接入一个新的数据源时,只需要将此数据源对接到 DataX,便能跟已有的数据源作为无缝数据同步。
1.DataX3.0框架设计
DataX 采用 Framework + Plugin 架构,将数据源读取和写入抽象称为 Reader/Writer 插件,纳入到整个同步框架中。

2.DataX3.0核心架构
DataX 完成单个数据同步的作业,我们称为 Job,DataX 接收到一个 Job 后,将启动一个进程来完成整个作业同步过程。DataX Job 模块是单个作业的中枢管理节点,承担了数据清理、子任务切分、TaskGroup 管理等功能。

DataX Job 启动后,会根据不同源端的切分策略,将 Job 切分成多个小的 Task (子任务),以便于并发执行。
接着 DataX Job 会调用 Scheduler 模块,根据配置的并发数量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组)。
每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader --> Channel --> Writer 线程来完成任务同步工作。
DataX 作业运行启动后,Job 会对 TaskGroup 进行监控操作,等待所有 TaskGroup 完成后,Job 便会成功退出(异常退出时值非0)
3.DataX调度过程
首先 DataX Job 模块会根据分库分表切分成若干个 Task,然后根据用户配置并发数,来计算需要分配多少个 TaskGroup;计算过程:Task / Channel = TaskGroup,最后由 TaskGroup 根据分配好的并发数来运行 Task(任务)。
二、使用 DataX 实现数据同步
例如生成MySQL到MySQL同步的模板:
#输出mysql配置模版
[root@192 bin]# python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter > /usr/local/datax/job/mysql2mysql.json
#根据模板编写 mysql2mysql.json文件
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"], #"*"表示所有字段
"connection": [
{
"jdbcUrl": ["jdbc:mysql://x.x.x.210:3306/mytest"],
"table": ["user"]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.88.192:3306/mytest",
"table": ["user"]
}
],
"password": "root",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "6"
}
}
}
}
验证:
[root@192 job]# python /usr/local/datax/bin/datax.py mysql2mysql.json
2022-04-24 17:39:03.445 [job-0] INFO JobContainer -
任务启动时刻 : 2022-04-24 17:38:49
任务结束时刻 : 2022-04-24 17:39:03
任务总计耗时 : 14s
任务平均流量 : 0B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
三、DataX-WEB 安装部署
1.DataX-WEB
https://github.com/WeiYe-Jing/datax-web
2.解压安装包
在选定的安装目录,解压安装包
[root@192 ~]# tar -zxvf datax-web-2.1.2.tar.gz -C /usr/local/dataxweb
3.登录msyql建库
为接下来一键安装部署准备,这里我建的库是dataxweb(自己定义就好,前后保持一致)
mysql> create database dataxweb;
4.执行一键安装脚本
进入解压后的目录,找到bin目录下面的install.sh文件,如果选择交互式的安装,则直接执行
[root@192 dataxweb]# cd bin/
[root@192 bin]# pwd
/usr/local/dataxweb/bin
[root@192 bin]# ./install.sh
然后按照提示操作即可。包含了数据库初始化,如果你的服务上安装有mysql命令,在执行安装脚本的过程中则会出现以下提醒:
Scan out mysql command, so begin to initalize the database
Do you want to initalize database with sql: [{INSTALL_PATH}/bin/db/datax-web.sql]? (Y/N)y
Please input the db host(default: 127.0.0.1):
Please input the db port(default: 3306):
Please input the db username(default: root):
Please input the db password(default: ): root
Please input the db name(default: dataxweb)
按照提示输入数据库地址,端口号,用户名,密码以及数据库名称,大部分情况下即可快速完成初始化。
如果服务上并没有安装mysql命令,则可以取用目录下/bin/db/datax-web.sql脚本去手动执行,完成后修改相关配置文件
vi modules/datax-admin/conf/bootstrap.properties
#Database
DB_HOST=127.0.0.1
DB_PORT=3306
DB_USERNAME=root
DB_PASSWORD=root
DB_DATABASE=dataxweb
按照具体情况配置对应的值即可。
在交互模式下,对各个模块的package压缩包的解压以及configure配置脚本的调用,都会请求用户确认,可根据提示查看是否安装成功,如果没有安装成功,可以重复尝试;如果不想使用交互模式,跳过确认过程,则执行以下命令安装
./bin/install.sh --force
5.其他配置
邮件服务
在项目目录:modules/datax-admin/bin/env.properties 配置邮件服务(可跳过)MAIL_USERNAME="" MAIL_PASSWORD=""
此文件中包括一些默认配置参数,例如:server.port,具体请查看文件。
指定PYTHON_PATH的路径
vim modules/datax-executor/bin/env.properties
### 执行datax的python脚本地址
PYTHON_PATH=/usr/local/datax/bin/datax.py
### 保持和datax-admin服务的端口一致;默认是9527,如果没改datax-admin的端口,可以忽略
DATAX_ADMIN_PORT=
此文件中包括一些默认配置参数,例如:executor.port,json.path,data.path等,具体请查看文件。
6.启动服务
6.1一键启动所有服务
[root@192 dataxweb]# cd /usr/local/dataxweb/
[root@192 dataxweb]# ./bin/start-all.sh
中途可能发生部分模块启动失败或者卡住,可以退出重复执行,如果需要改变某一模块服务端口号,则:
vi ./modules/{module_name}/bin/env.properties
找到SERVER_PORT配置项,改变它的值即可。当然也可以单一地启动某一模块服务:
./bin/start.sh -m {module_name}
module_name可以为datax-admin或datax-executor
6.2一键停止所有服务
[root@192 dataxweb]# cd /usr/local/dataxweb/
[root@192 dataxweb]# ./bin/stop-all.sh
当然也可以单一地停止某一模块服务:
./bin/stop.sh -m {module_name}
6.3查看服务
在Linux环境下使用JPS命令,查看是否出现DataXAdminApplication和DataXExecutorApplication进程,如果存在这表示项目运行成功
如果项目启动失败,请检查启动日志:
modules/datax-admin/bin/console.out
或者
modules/datax-executor/bin/console.out
四、DataX-WEB 运行
1.前端界面
部署完成后,在浏览器中输入 http://ip:port/index.html 就可以访问对应的主界面(ip为datax-admin部署所在服务器ip,port为为datax-admin 指定的运行端口9527)
输入用户名 admin 密码 123456 就可以直接访问系统
2.datax-web API
datax-web部署成功后,可以了解datax-web API相关内容,网址: http://ip:port/doc.html
DataX-WEB 运行日志
部署完成之后,在modules/对应的项目/data/applogs下(用户也可以自己指定日志,修改application.yml 中的logpath地址即可),用户可以根据此日志跟踪项目实际启动情况
如果执行器启动比admin快,执行器会连接失败,日志报"拒绝连接"的错误,一般是先启动admin,再启动executor,30秒之后会重连,如果成功请忽略这个异常。
六、DataX-WEB 实操
1.查看执行器
查看web界面是否有注册成功的执行器,另外执行器可以根据需要改名称。

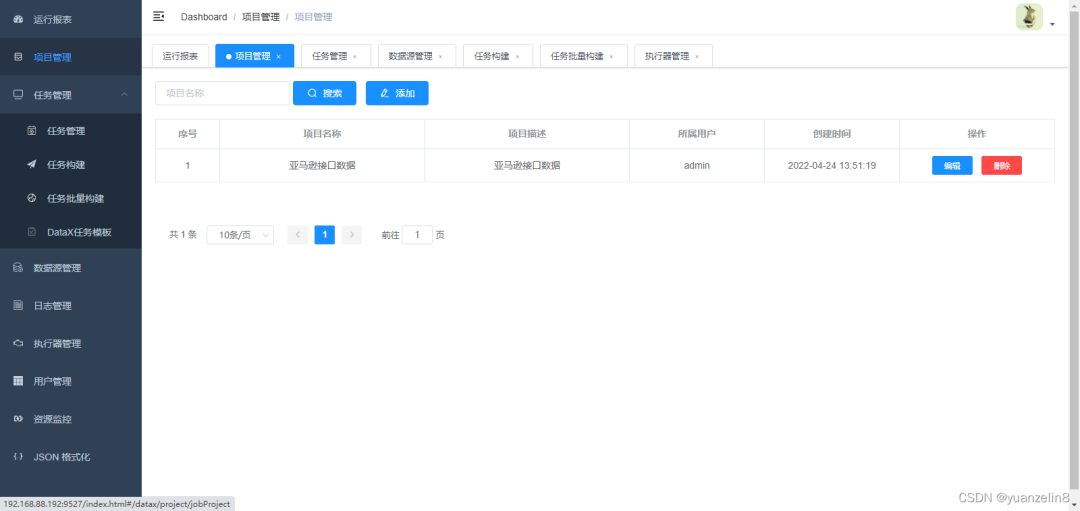
2.创建项目
3.路由策略
当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):依次分配任务;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略
单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行; 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败; 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
设置单机串行时应该注意合理设置重试次数(失败重试的次数* 每次执行时间< 任务的调度周期),重试的次数如果设置的过多会导致数据重复,例如任务30秒执行一次,每次执行时间需要20秒,设置重试三次,如果任务失败了,第一个重试的时间段为1577755680-1577756680,重试任务没结束,新任务又开启,那新任务的时间段会是1577755680-1577758680
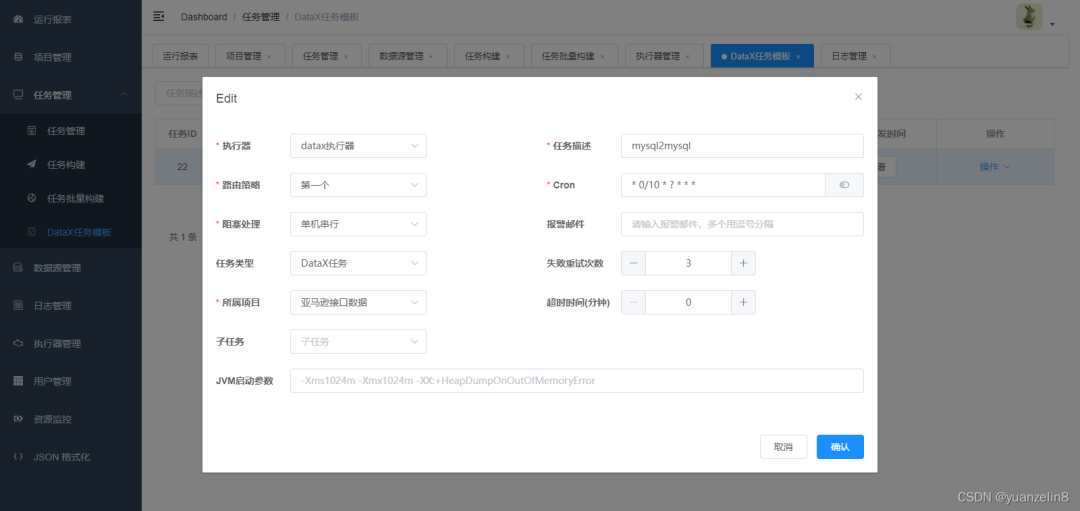
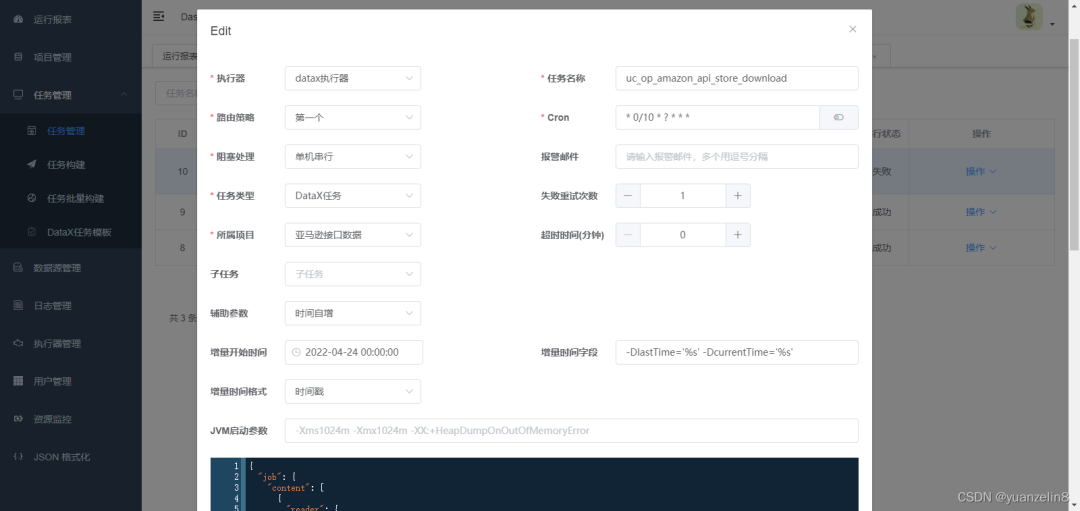
4.任务类型
先选择DataX任务,后续配置完详细任务后可以按照下图修改,其它可以根据需求填写。
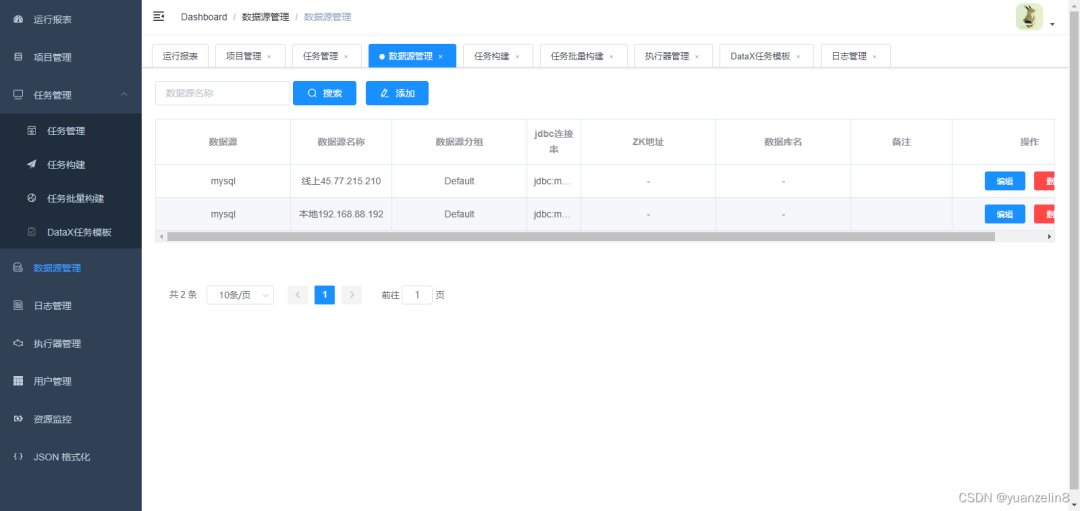
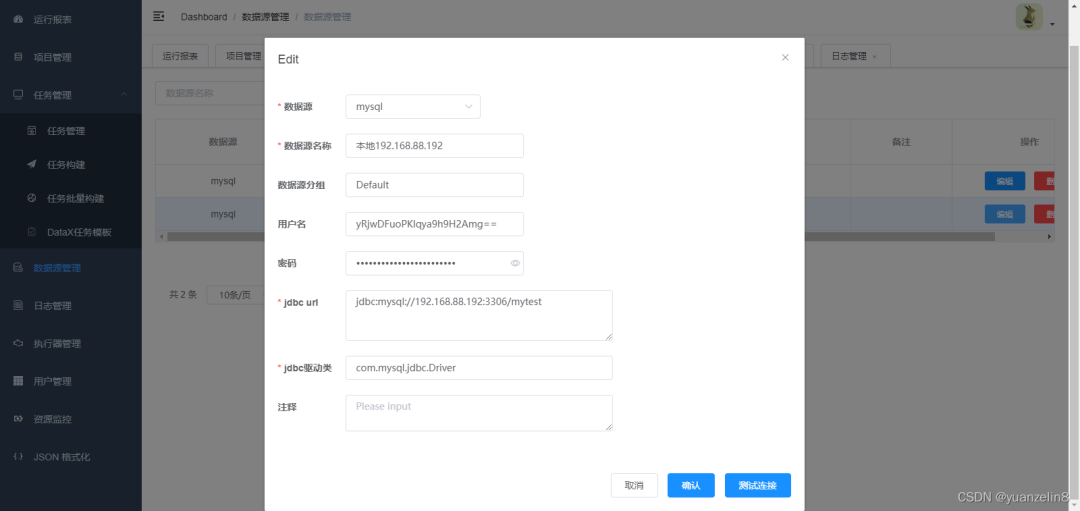
5. 数据源配置
根据不同数据源,配置参数。
6.任务构建
构建reader
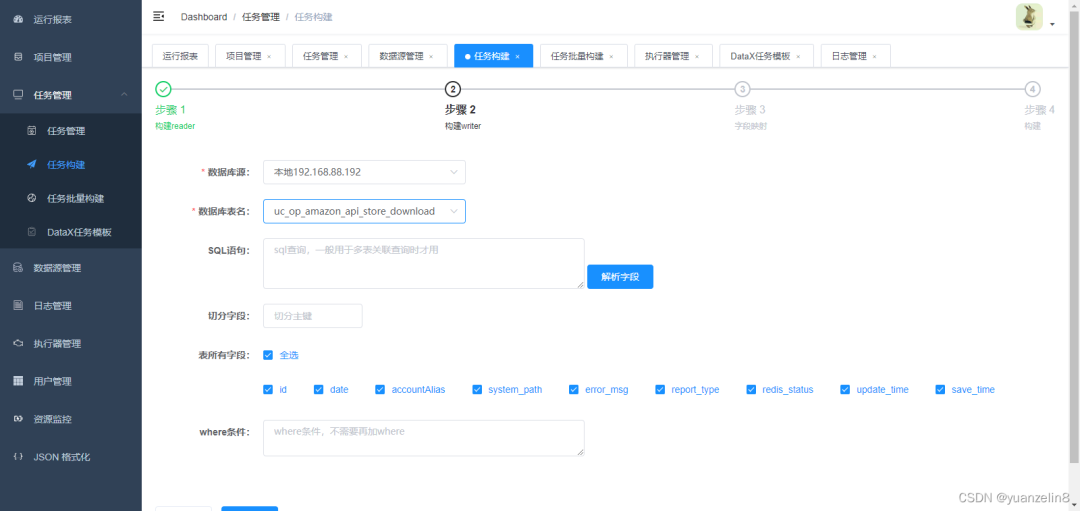
这里没按上面操作生成映射,直接使用任务管理->添加手动配置
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"*"
],
"where": " save_time >= FROM_UNIXTIME(${lastTime}) and save_time < FROM_UNIXTIME(${currentTime})",
"splitPk": "id",
"connection": [
{
"table": [
"uc_op_amazon_api_store_download"
],
"jdbcUrl": [
"jdbc:mysql://x.x.x.210:3306/test_system"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"*"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.88.192:3306/mytest?useUnicode=true&characterEncoding=utf8",
"table": [
"uc_op_amazon_api_store_download"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 6
}
}
}
}
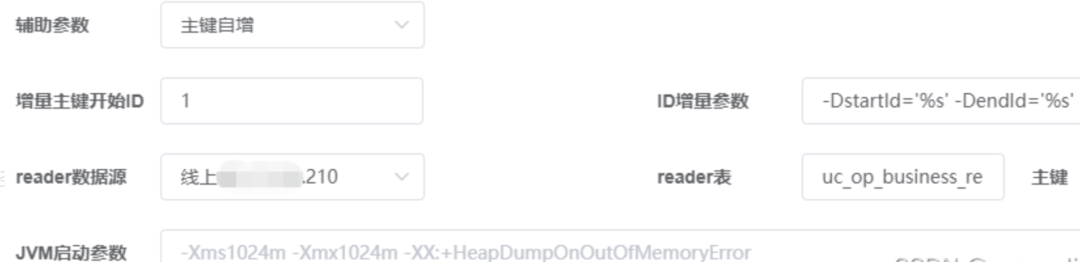
-DstartId='%s' -DendId='%s'
# 表名
uc_op_business_reports
#主键
id
#id自增配置条件