
FileBeat + Kafka Logstash+ ElasticSearch+Kibana 搭建日志管理平台
管理平台流程
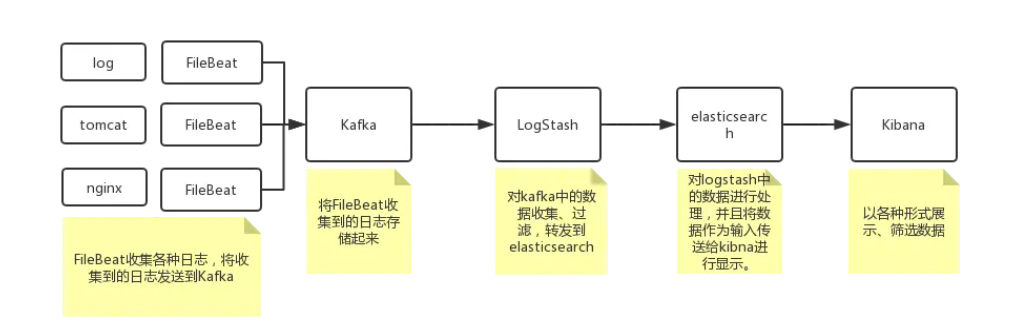
环境准备
elasticsearch-6.0.0.tar.gz
filebeat-7.0.1-linux-x86_64.tar.gz
kibana-6.0.0-linux-x86_64.tar.gz
logstash-6.0.0.tar.gz
kafka_2.11-2.1.1.tgz
除了kafka以外,其它四个均可以在elastic官网中下载,具体的可以在下载地址选择软件和版本进行下载,本文档都是基于6.0.0的版本操作的
Kafka可以在Apache中下载
本文档均是基于CentOS Linux release 7.2.1511 (Core) 64位系统安装部署的,查看版本和位数可以使用如下命令
cat /etc/centos-release:查看版本号
getconf LONG_BIT:查看位数
安装及部署
因为是基于Java的,所以在部署之前,要先确保系统上安装了Jdk,本系统安装的Jdk版本为1.8
所有的文件都放在/usr/elk/下
Kibana部署
解压文件
[root@localhost elk]# tar -zxvf kibana-6.0.0-linux-x86_64.tar.gz修改配置,修改/conf/kibana.yml文件
# 设置elasticsearch地址elasticsearch.url: "http://localhost:9200"server.host: 0.0.0.0
elasticsearch部署
解压文件
[root@localhost elk]# tar -zxvf elasticsearch-6.0.0.tar.gz启动该项目的时候,不能使用root权限,所以要新建一个用户来启动
# 新建一个组[root@localhost elk]# groupadd elkgroup# 在该组下新增用户 useradd 用户名 -g 组名 -p 密码[root@localhost elk]# useradd elkuser -g elkgroup -p 123456# 赋权限 chown -R 用户名:组名 文件[root@localhost elk]# chown -R elsearch:elsearch elasticsearch-6.0.0# 切换用户并且启动elasticsearch[root@localhost elk]# su elkuser[elkuser@localhost elasticsearch-6.0.0]$ ./bin/elasticsearch
logstash部署
解压文件
[root@localhost elk]# tar -zxvf logstash-6.0.0.tar.gz在conf目录下新建一个配置文件logstash.conf
input{file{type=>"log"path=>"/usr/logs/*.log"start_position=>"beginning"}}output{stdout{codec=>rubydebug{}}elasticsearch{hosts=>"127.0.0.1"index=>"log-%{+YYYY.MM.dd}"}}
根据配置文件启动
[root@localhost elk]# ./logstash -f ../config/logstash.conf复制代码
Kafka部署
安装glibc
[root@localhost elk]# yum -y install glibc.i686配置zookeeper
[root@localhost elk]# vi config/zookeeper.properties# 配置内容dataDir=/data/programs/kafka_2.11-0.10.0.0/datadataLogDir=/data/programs/kafka_2.11-0.10.0.0/logsclientPort=2181maxClientCnxns=100tickTime=2000initLimit=10# 配置完成保存退出,然后根据配置启动zookeeper[root@localhost kafka_2.11-2.1.1]# ./bin/zookeeper-server-start.sh config/zookeeper.properties
配置kafka文件
[root@localhost kafka_2.11-2.1.1]# vi config/server.properties# 配置内容broker.id=0port=9092host.name=127.0.0.1num.network.threads=3num.io.threads=8socket.send.buffer.bytes=102400socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600log.dirs=/data/logs/kafkanum.partitions=2num.recovery.threads.per.data.dir=1log.retention.check.interval.ms=300000zookeeper.connect=localhost:2181zookeeper.connection.timeout.ms=6000# 配置完成保存退出,然后根据配置启动kafka[root@localhost kafka_2.11-2.1.1]# ./bin/kafka-server-start.sh config/server.properties
在启动过程中,可能会提示内存不足,
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12)## There is insufficient memory for the Java Runtime Environment to continue.# Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory.# An error report file with more information is saved as:
因为默认kafka配置的为1G,所以修改启动配置
将 /bin/kafka-server-start.sh的export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"修改为export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
然后重新启动就可以了
fileBeat部署
修改filebeat.yml配置
[root@localhost filebeat-7.0.1-linux-x86_64]# vi filebeat.yml# 新增输出到kafka配置,该配置是yml格式,所以配置的时候要符合yml规范#--------------------------- kafka output ----------------------------------output.kafka:enabled: truehosts: ["127.0.0.1:9092"]topic: test# 并且修改相关配置enabled: true# 获取日志的路径paths:- /home/elk/log/access.log# 日志标签,在kibana中查看数据可以找到该标签,并且可以根据该tag标签过滤查找数据tags: ["nginx-accesslog"]# 启动服务[root@localhost filebeat-7.0.1-linux-x86_64]# ./filebeat -e
问题及注意点
在启动logstash的时候报了一个小问题,提示
Connection to node -1 could not be established. Broker may not be available.
该问题是由于开始我启动kafka的时候配置的host.name=10.12.1.52,这个地址是服务器的地址,但是在logstash中配置的kafka地址为127.0.0.1导致的
注意点:
logstash的配置
kafka的队列名要对应
清风许许https://juejin.cn/post/6844903845970051080

分享&在看