
携手未来,星辰大海~StarRocks让数据分析更简单

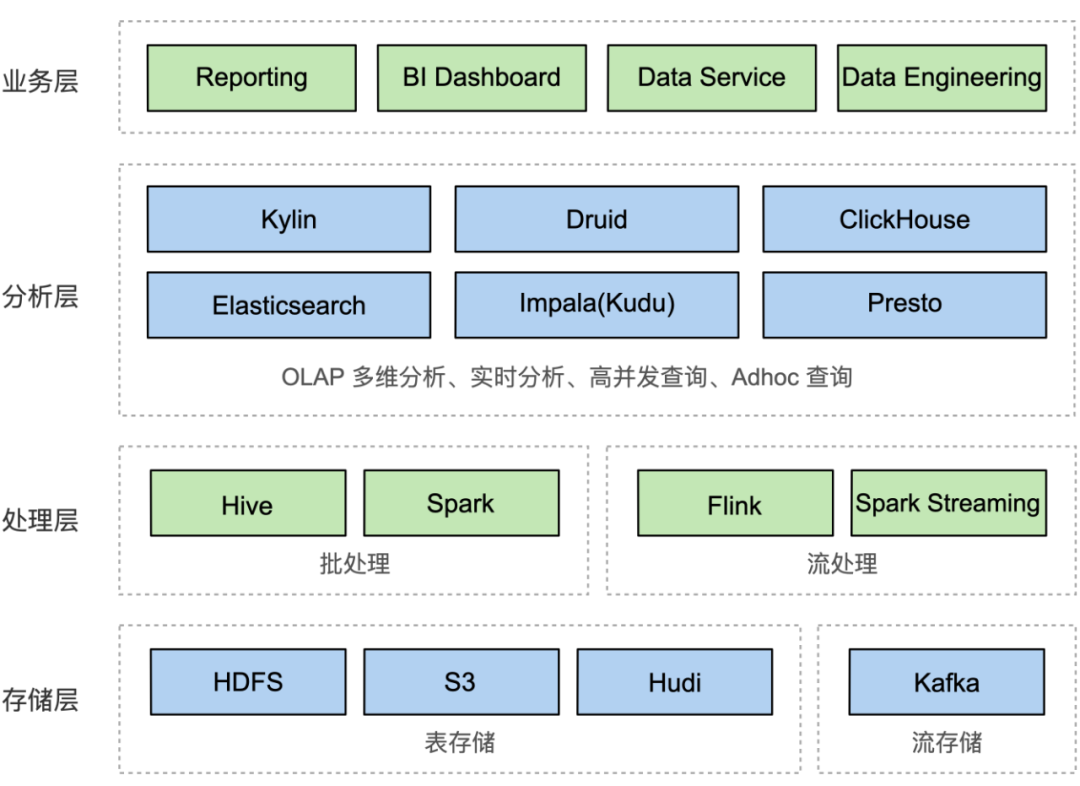
(复杂的企业数据分析架构)
第一,数据分析性能不达标。
随着数据驱动的深入,业务提出了更多的分析需求,比如多维分析,实时分析,高并发查询和 Adhoc 查询。在很多分析需求场景下,当前系统性能表现不佳,无法提供极速分析体验。
第二,数据分析的灵活性不足。
很多时候,为了能够提供极速分析体验,你需要针对各类场景构建大宽表,或者做复杂的预处理,而这损失了分析灵活性。特别是在自助化BI这样灵活的场景下,星型模型和雪花模型的价值不可替代。现有的系统难以同时高性能支持这些建模手段。
第三,数据架构复杂度太高。
为了满足业务的多种分析需求,你必须搭建多套系统来组合使用。这让分析层架构变得非常复杂,导致开发维护成本以及业务使用成本都很高。另外,随着各类实时分析场景的兴起,你需要同时构建离线数据链路和实时数据链路。但数据同步、数据一致性、计算逻辑同步、异常数据处理、多系统运维等问题马上就接踵而至。你只能疲于应付。
第四,数据分析能力弹性不足。
你的数据规模越来越大,对应的数据分析系统需要不断地扩容;不同的业务线有不同的数据分析访问量,需要保证每个业务线的SLA;有的业务还有大促,周年庆等流量高峰,如何保证既能支持好业务,又能节省成本?相信这些问题没少让你头疼。
产生这些问题的根本原因,是旧的大数据技术架构已经不能满足当前业务高速发展的需求。在旧的底层架构上进行修修补补只能解决部分问题。要想从根本上破局,就需要一套全新的“极速统一”的数据架构。“极速”,意味着全面提升数据处理和分析的性能;“统一”意味着将复杂分散的数据架构融合为简单统一的架构。
为此我们决定把我们的核心产品DorisDB升级为StarRocks,并全面开源(Github搜索“StarRocks”),和全球大数据从业者一起构建新一代极速统一的数据分析架构!
StarRocks 开创全新的极速统一分析
2020年初,当时还没有人相信一个企业的数据分析架构可以统一,但我们相信“极速统一分析”一定可以实现。经过团队近20个月夜以继日的努力,我们攻克了诸多“不可能”的技术难题,通过自主研发新一代的技术,我们将StarRocks打造成了具有划时代意义的产品:“新一代极速全场景MPP数据库”
全新设计的全面向量化 MPP 查询引擎,同时支持极速的单表和多表查询性能 。
StarRocks自主打造的新一代全面向量化的MPP引擎使查询性能大幅提高,是非原生向量化系统(Kylin / Druid / Elasticsearch / Impala-Kudu / Presto / Greenplum)的3~5倍以上。ClickHouse向量化引擎并不支持全面的MPP,多表查询能力差,StarRocks的多表查询性能是其3~5倍以上。
全新设计的实时列式存储引擎,具备极致的实时更新和查询性能。
在实时更新下,StarRocks查询性能是其他产品的3~5倍以上。
全新设计的数据分布模式,具备高并发查询能力。
其他系统都无法较好支持高并发查询,StarRocks可以支持每秒上万次的并发查询能力。
全新设计的 CBO 优化器,支持极速的秒级 AdHoc 查询。
StarRocks性能可以做到主流AdHoc查询系统Presto的5倍以上,可以做到秒级延迟。
全新设计的现代化物化视图,具备灵活透明的预计算加速能力。
其他产品无法做到非常好的透明化加速,具有较高的开发和管理成本,StarRocks在可以灵活透明加速的现代化物化视图方面进行了大量创新。
通过这些独特的技术能力,StarRocks真正实现了极速统一分析:
StarRocks可以同时高效支持OLAP多维分析、实时数据分析、高并发查询、AdHoc查询等多场景,并且比上一代同类型产品的分析能力快3~5倍以上。
全新的OLAP多维分析体验,打破“只能做大宽表”的局限性,让多种数据建模模式:预计算、大宽表、星型模型和雪花模型等都具备极速分析体验。
全新的实时数据分析体验,真正支持实时更新和删除,并能保证极速查询性能。
全新的高并发查询体验,突破传统OLAP无法高并发的限制,支持数千人同时访问。
全新极简统一的OLAP架构,大大降低了使用和运维管理复杂度,提升了开发和使用效率。
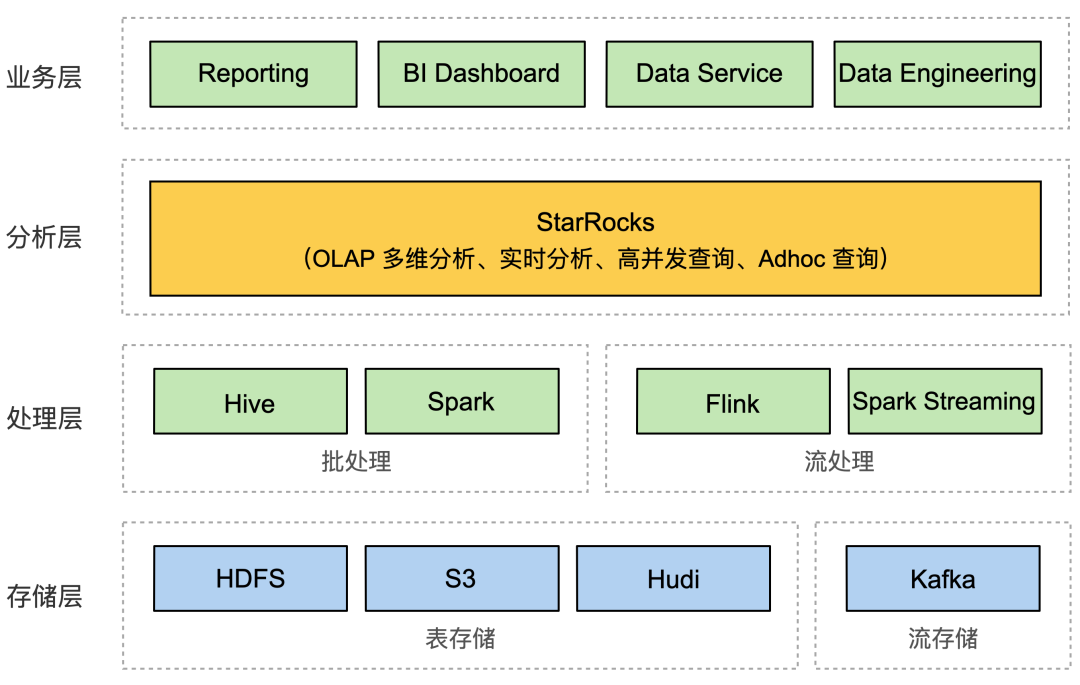
“极速统一分析”并不是终局,而是新的起点
在当前极速统一的数据分析架构的基础上,我们的下一个目标是要打造“新一代流批融合的极速湖仓(Lakehouse)”。众所周知,在当前主流的数据处理链路中,实时数据处理和离线数据处理是割裂的。企业要管理好这两种数据处理场景,往往系统架构复杂、难于维护。而我们要在StarRocks里实现这两种数据处理方式的融合。
我们将设计全新实时和离线融合的云原生架构,可以同时高效管理实时数据和离线数据。
虽然云原生标杆Snowflake在离线数据场景下打造了先进的存储计算分离架构,但是这个架构在实时数据分析支持上存在很大不足。我们将设计新一代云原生架构,同时高性能支持实时数据和离线数据的写入和读取。
我们还将设计全新流批融合的向量化计算引擎,可以同时进行极速的批处理和流处理。
通过打造全新的向量化批处理引擎,可以实现比Apache Spark快5~10倍以上的批处理速度。同时完美融合流式语义,利用向量化技术提升流处理性能。用户无需再忍受使用Spark和Flink分散进行批处理和流处理带来的复杂性!
“坚持大胆尝试,实现不可能”是我们一直践行的价值观。在未来一年半左右的时间内,我们将和社区一起打造全新的StarRocks。让企业的离线数据和实时数据可以采用同一套架构、同一种语义、同一个引擎来处理,让数据架构实现全面的“极速统一”,“让原本简单的事情回归简单”!
一个人走得快,一群人走得远
为了实现这些伟大梦想,我们将在全球范围内构建StarRocks开源生态,吸引优秀的有志之士一起来参与社区建设。我们将不遗余力地推动更多的全球用户加入社区,了解和评测StarRocks,使用和改进StarRocks。我们还将推动全球的数据工程师/数据分析师与社区一起,基于StarRocks构建各类数据分析场景的新一代解决方案。
如果你也和我们一样,心怀梦想,请现在就关注我们,参与社区建设,在Github上给StarRocks加一个星吧。让我们一起来创造“极速统一”的大数据新时代,向不可能说不!
StarRocks——携手未来,星辰大海!
扫码加入StarRocks社区交流群,或关注微信公众号回复“加群”
如希望了解更多详情请关注我们!
