
看完这篇文章,你也可以手写MyBatis部分源码(JDBC)
一、持久化机制
持久化(persistence): 把数据保存到可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以”固化”,而持久化的实现过程大多通过各种关系数据库来完成。就是将内存中的数据存储在关系型数据库中,当然也可以存储在磁盘文件、XML数据文件中。而在 Java中,数据库存取技术只能通过 JDBC 来访问数据库。
JDBC 访问数据库的形式主要有两种:
直接使用 JDBC 的 API 去访问数据库服务器 (MySQL/Oracle)。
间接地使用 JDBC 的 API 去访问数据库服务器,使用第三方O/R Mapping工具,如 Hibernate, MyBatis 等。(底层依然是 JDBC ,JDBC 是 Java 访问数据库的基石,其他技术都是对 JDBC 的封装)
二、JDBC概述
JDBC (Java DataBase Connectivity)是一个独立于特定数据库管理系统、通用的SQL数据库存取和操作的公共接口(一组API),定义了用来访问数据库的标准Java类库,(java.sql,javax.sql)使用这些类库可以以一种标准的方法、方便地访问数据库资源。 JDBC为访问不同的数据库提供了一种统一的途径,为开发者屏蔽了一些细节问题。 JDBC 的目标是使 Java 程序员使用 JDBC 可以连接任何提供了 JDBC 实现 (驱动程序) 的数据库系统,这
样就使得程序员无需对特定的数据库系统的特点有过多的了解,从而大大简化和加快了开发过程。
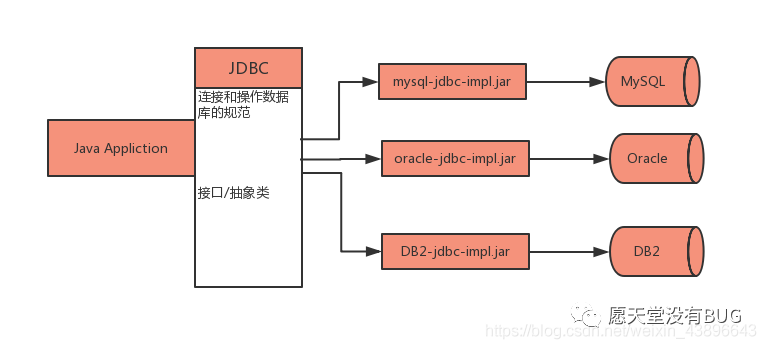
简单来说,JDBC 本身是 Java 连接数据库的一个标准,是进行数据库连接的抽象层,由 Java编写的一组类和接口组成,接口的实现由各个数据库厂商来完成。
JDBC编写的步骤如下:
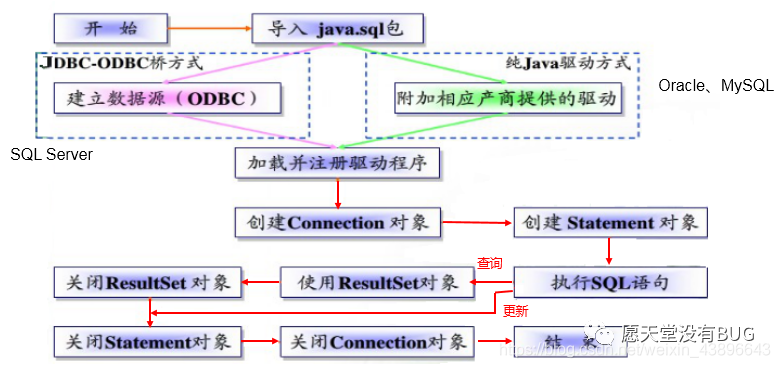
ODBC(Open Database Connectivity,开放式数据库连接),是微软在Windows平台下推出的。使用者在程序中只需要调用ODBC API,由 ODBC 驱动程序将调用转换成为对特定的数据库的调用请求。
三、获取数据库连接
3.1、加载注册驱动
java.sql.Driver 接口是所有 JDBC 驱动程序需要实现的接口。这个接口是提供给数据库厂商使用的,不同数据库厂商提供不同的实现。在程序中不需要直接去访问实现了 Driver 接口的类,而是由驱动程序管理器类(java.sql.DriverManager)去调用这些Driver实现。
Oracle的驱动:oracle.jdbc.driver.OracleDriver
mySql的驱动:com.mysql.jdbc.Driver
加载驱动:加载 JDBC 驱动需调用 Class 类的静态方法 forName(),向其传递要加载的 JDBC 驱动的类名
Class.forName(“com.mysql.jdbc.Driver”);
3.2、注册驱动的原理
注册驱动:DriverManager 类是驱动程序管理器类,负责管理驱动程序
使用DriverManager.registerDriver(com.mysql.jdbc.Driver)来注册驱动
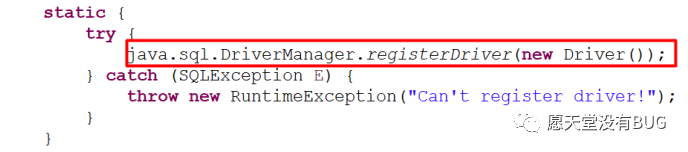
通常不用显式调用 DriverManager 类的 registerDriver() 方法来注册驱动程序类的实例,因为 Driver 接口的驱动程序类都包含了静态代码块,在这个静态代码块中,会调用 DriverManager.registerDriver() 方法来注册自身的一个实例。下图是MySQL的Driver实现类的源码:
他通常有以下两个步骤:
1. 把 com.mysql.jdbc.Driver 这一份字节码加载进 JVM。
2. 字节码被加载进JVM,就会执行其静态代码块.而其底层的静态代码块在完成注册驱动工作,将驱动注
册到DriverManger 中。
复制代码3.3、获取连接对象
我们一般使用 DriverManager 的 getConnection 方法创建 Connection 对象
Connection conn = DriverManager.getConnection(url,username,password);
// url=jdbc:mysql://localhost:3306/jdbcdemo
// 如果连接的是本机的 MySQL,并且端口是默认的 3306 ,则可以简写:
// url=jdbc:mysql:///jdbcdemo
// username:当前访问数据库的用户名
// password:当前访问数据库的密码
复制代码3.3.1、URL详解
JDBC URL 用于标识一个被注册的驱动程序,驱动程序管理器通过这个 URL 选择正确的驱动程序,从而建立到数据库的连接。
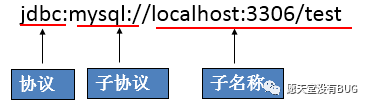
JDBC URL的标准由三部分组成(协议:子协议:子名称),各部分间用冒号分隔。
协议:JDBC URL中的协议总是jdbc(固定写法)。
子协议:子协议用于标识一个数据库驱动程序。
子名称:一种标识数据库的方法。子名称可以依不同的子协议而变化,用子名称的目的是为了定位数据库提供足够的信息。包含主机名(对应服务端的ip地址),端口号,数据库名。
url的常见写法:
jdbc:mysql://主机名称:mysql服务端口号/数据库名称?参数=值&参数=值
jdbc:mysql://localhost:3306/atguigu
jdbc:mysql://localhost:3306/atguigu**?useUnicode=true&characterEncoding=utf8**(如果JDBC程序与服务器端的字符集不一致,会导致乱码,那么可以通过参数指定服务器端的字符集)
jdbc:mysql://localhost:3306/atguigu?user=root&password=123456
3.4、数据库连接方法
3.4.1、方式一
我们可以通过直接获取注册驱动,将数据库信息写在代码中,这个的问题也是很明显的,那就是一个硬编码问题,当我们需要修改数据库的时候,需要直接修改Java源代码。
@Test
public void testConnection4() {
try {
//1.数据库连接的4个基本要素:
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "admin";
String driverName = "com.mysql.jdbc.Driver";
//2.加载驱动 (①实例化Driver ②注册驱动)
Class.forName(driverName);
//3.获取连接
Connection conn = DriverManager.getConnection(url, user, password);
System.out.println(conn);
} catch (Exception e) {
e.printStackTrace();
}
}
复制代码3.4.2、方式二
我们为了解决方式一硬编码的问题,需要将驱动信息放入配置文件,然后通过读取的方式来进行赋值。
@Test
public void testConnection5() throws Exception {
//1.加载配置文件
InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
//2.读取配置信息
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
//3.加载驱动
Class.forName(driverClass);
//4.获取连接
Connection conn = DriverManager.getConnection(url,user,password);
System.out.println(conn);
}
复制代码使用配置文件的好处:
实现了代码和数据的分离,如果需要修改配置信息,直接在配置文件中修改,不需要深入代码。
如果修改了配置信息,省去重新编译的过程。
四、DAO思想
4.1、没有DAO
在没有 DAO 的时候,我们的代码存在大量的重复。

4.2、DAO介绍
DAO(Data Access Object) 数据访问对象是一个面向对象的数据库接口. 顾名思义就是与数据库打交道,夹在业务逻辑与数据库资源中间,将所有对数据源的访问操作抽象封装在一个公共 API 中。程序书写就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。DAO 中的主要操作: 增删改查(CRUD)。
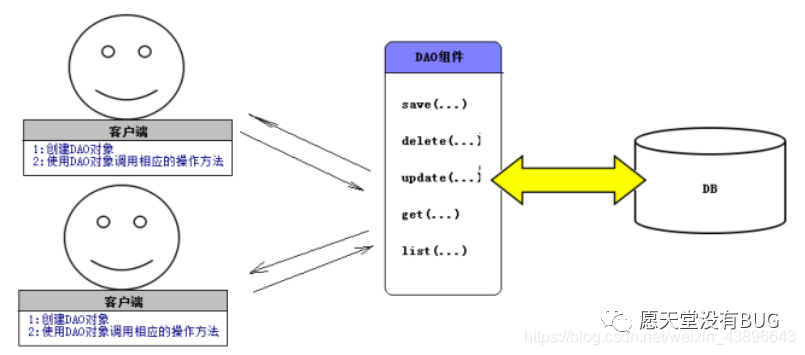
通过以上图,DAO 作为组件,那其主要的是方法的设计,方法设计需要注意什么呢?
在保存功能中,调用者需要传递多个参数进来,然后把这些数据保存到数据库中。
在查询功能中,结果集的每行数据有多个列的值,然后把这些数据返回给调用者。
在开发过程中,如果遇到需要传递的数据有多个的时候,通常需要使用 JavaBean 对其进行封装
4.3、DAO规范
DAO本质就是一个可以重复使用的组件。他包括了两个规范:
分包规范(域名倒写.项目模块名.组件)
cn.util; //存放工具类
cn.domain; //装pss模块的domain类,模型对象.(Student)
cn.dao; //装pss模块的dao接口.调用者将需要保存的数据封装到一个对象中,然后传递进来
cn.dao.impl; //装dao接口的实现类.
cn.test; //暂时存储DAO的测试类,以后的测试类不应该放这里.
复制代码命名规范
DAO 接口 : 表示对某个模型的 CRUD 操作做规范,以 I 开头,interface。例如:IStudentDAO
DAO 实现类: 表示对某个 DAO 接口的实现,例如:EmployeeDAOImpl
DAO 测试类: 测试 DAO 组件中的所有方法,例如:EmployeeDAOTest
调用建议:面向接口编程
传统的做法 : EmployeeDAOImpl dao = new EmployeeDAOImpl();
面向接口编程 : IEmployeeDAO dao = new EmployeeDAOImpl();
五、JDBC之CRUD操作
5.1、Statement对象及其弊端
5.1.1、Statement对象
Statement对象时用于执行静态 SQL 语句并返回它所生成结果的对象。

通过调用 Connection 对象的 createStatement() 方法创建该对象。该对象用于执行静态的 SQL 语句,并且返回执行结果。
Statement 接口中定义了下列方法用于执行 SQL 语句:
int excuteUpdate(String sql):执行更新操作INSERT、UPDATE、DELETE
ResultSet executeQuery(String sql):执行查询操作SELECT
复制代码5.1.2、使用Statement对象的弊端
用Statement操作数据表存在弊端:
存在拼串操作,繁琐
存在SQL注入问题
SQL 注入是利用某些系统没有对用户输入的数据进行充分的检查,而在用户输入数据中注入非法的 SQL 语句段或命令(如:SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1') ,从而利用系统的 SQL 引擎完成恶意行为的做法。
public class StatementTest {
// 使用Statement的弊端:需要拼写sql语句,并且存在SQL注入的问题
@Test
public void testLogin() {
Scanner scan = new Scanner(System.in);
System.out.print("用户名:");
String userName = scan.nextLine();
System.out.print("密 码:");
String password = scan.nextLine();
// SELECT user,password FROM user_table WHERE USER = '1' or ' AND PASSWORD = '='1' or '1' = '1';
String sql = "SELECT user,password FROM user_table WHERE USER = '" + userName + "' AND PASSWORD = '" + password
+ "'";//字符串拼接过于繁杂
User user = get(sql, User.class);
if (user != null) {
System.out.println("登陆成功!");
} else {
System.out.println("用户名或密码错误!");
}
}
// 使用Statement实现对数据表的查询操作
public <T> T get(String sql, Class<T> clazz) {
T t = null;
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
// 1.加载配置文件
InputStream is = StatementTest.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(is);
// 2.读取配置信息
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
// 3.加载驱动
Class.forName(driverClass);
// 4.获取连接
conn = DriverManager.getConnection(url, user, password);
st = conn.createStatement();
rs = st.executeQuery(sql);
// 获取结果集的元数据
ResultSetMetaData rsmd = rs.getMetaData();
// 获取结果集的列数
int columnCount = rsmd.getColumnCount();
if (rs.next()) {
t = clazz.newInstance();
for (int i = 0; i < columnCount; i++) {
// //1. 获取列的名称
// String columnName = rsmd.getColumnName(i+1);
// 1. 获取列的别名
String columnName = rsmd.getColumnLabel(i + 1);
// 2. 根据列名获取对应数据表中的数据
Object columnVal = rs.getObject(columnName);
// 3. 将数据表中得到的数据,封装进对象
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);
field.set(t, columnVal);
}
return t;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (st != null) {
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return null;
}
}
复制代码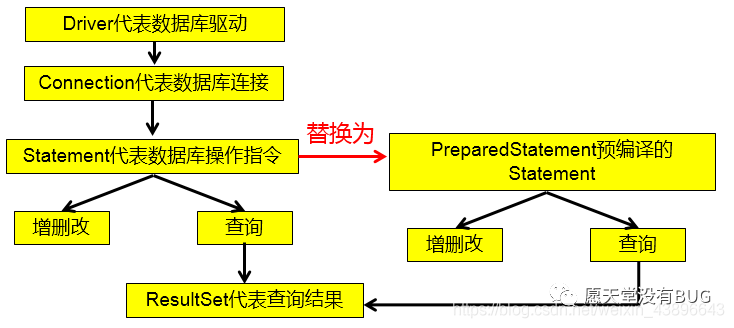
5.2、PreparedStatement
我们可以通过调用 Connection 对象的 preparedStatement(String sql) 方法获取PreparedStatement对象,PreparedStatement 接口是 Statement 的子接口,它表示一条预编译过的 SQL 语句。
PreparedStatement 对象所代表的 SQL 语句中的参数用问号(?)来表示,调用PreparedStatement对象的 setXxx() 方法来设置这些参数. setXxx() 方法有两个参数,第一个参数是要设置的 SQL 语句中的参数的索引(从 1 开始),第二个是设置的 SQL 语句中的参数的值。
// 常用方法:
void setXxx(int parameterIndex,Xxx value); //设置第几个占位符的真正参数值.
// Xxx 表示数据类型,比如 String,int,long,Date等.
void setObject(int parameterIndex, Object x); //设置第几个占位符的真正参数值.
int executeUpdate(); //执行DDL/DML语句. 注意:没有参数
// 若当前 SQL是 DDL语句,则返回 0.
// 若当前 SQL是 DML语句,则返回受影响的行数.
ResultSet executeQuery(); //执行DQL语句,返回结果集.
close(); //释放资源
复制代码5.3、PreparedStatement vs Statement
PreparedStatement对象比Statement对象的代码的可读性和可维护性。PreparedStatement能最大可能提高性能。DBServer会对预编译语句提供性能优化。因为预编译语句有可能被重复调用,所以语句在被DBServer的编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中就会得到执行。
在statement语句中,即使是相同操作但因为数据内容不一样,所以整个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存。这样每执行一次都要对传入的语句编译一次。
PreparedStatement 可以防止 SQL 注入 。
5.4、 ResultSet
查询需要调用PreparedStatement 的 executeQuery() 方法,查询结果是一个ResultSet 对象,ResultSet 对象以逻辑表格的形式封装了执行数据库操作的结果集,ResultSet 接口由数据库厂商提供实现。
ResultSet 返回的实际上就是一张数据表。有一个指针指向数据表的第一条记录的前面。
ResultSet 对象维护了一个指向当前数据行的游标,初始的时候,游标在第一行之前,可以通过 ResultSet 对象的 next() 方法移动到下一行。调用 next()方法检测下一行是否有效。若有效,该方法返回 true,且指针下移。相当于Iterator对象的hasNext()和next()方法的结合体。
当指针指向一行时, 可以通过调用 getXxx(int index) 或 getXxx(int columnName) 获取每一列的值。*Java与数据库交互涉及到的相关Java API中的索引都从1开始。*例如:
getInt(1), getString("name")
复制代码
5.5、CRUD操作
5.5.1、User类
package domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author Xiao_Lin
* @date 2021/1/2 19:44
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
//id
private Integer id;
//用户名
private String username;
//密码
private String pwd;
//构造方法的重载
public User(String username, String pwd) {
this.username = username;
this.pwd = pwd;
}
}
复制代码5.5.2、IUserDAO
package dao;
import domain.User;
import java.util.List;
/**
* @author Xiao_Lin
* @date 2021/1/2 19:46
*/
public interface IUserDAO {
public void insert(User user);
public void delete(Integer id);
public void update(User user);
public List<User> selectAll();
public User selectUserById(Integer id);
}
复制代码5.5.3、UserDAOImpl
package dao.impl;
import dao.IUserDAO;
import dao.utils.DaoUtils;
import domain.User;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
/**
* @author Xiao_Lin
* @date 2021/1/2 19:49
*/
public class UserDAOImpl implements IUserDAO {
Connection connection = null;
PreparedStatement ps = null;
ResultSet rs = null;
@Override
public void insert(User user) {
try {
connection = DaoUtils.getConnection();
String sql = "insert into user (username,pwd) values (?,?)";
ps = connection.prepareStatement(sql);
ps.setString(1,user.getUsername());
ps.setString(2,user.getPwd());
ps.executeUpdate();
System.out.println("添加成功!!");
} catch (SQLException e) {
e.printStackTrace();
}finally {
DaoUtils.close(connection,ps,null);
}
}
@Override
public void delete(Integer id) {
try {
connection = DaoUtils.getConnection();
ps = connection.prepareStatement("delete from user where id = ?");
ps.setInt(1,id);
ps.executeUpdate();
System.out.println("删除成功!!");
} catch (Exception e) {
e.printStackTrace();
}finally {
DaoUtils.close(connection,ps,null);
}
}
@Override
public void update(User user) {
try {
connection = DaoUtils.getConnection();
ps = connection.prepareStatement("update user set username = ? , pwd = ? where id = ?");
ps.setString(1,user.getUsername());
ps.setString(2,user.getPwd());
ps.setInt(3,user.getId());
ps.executeUpdate();
System.out.println("修改成功");
} catch (Exception e) {
e.printStackTrace();
}finally {
DaoUtils.close(connection,ps,null);
}
}
@Override
public List<User> selectAll() {
List<User> users = new ArrayList<>();
try {
connection = DaoUtils.getConnection();
ps = connection.prepareStatement("select * from user");
rs = ps.executeQuery();
while (rs.next()){
users.add(new User(rs.getInt("id"),rs.getString("username"),rs.getString("pwd")));
}
} catch (Exception e) {
e.printStackTrace();
}finally {
DaoUtils.close(connection,ps,rs);
}
return users;
}
@Override
public User selectUserById(Integer id) {
User user = null;
try {
connection = DaoUtils.getConnection();
ps = connection.prepareStatement("select * from user where id = ?");
ps.setInt(1,id);
rs = ps.executeQuery();
while (rs.next()){
user = new User(rs.getInt("id"),rs.getString("username"),rs.getString("pwd"));
}
} catch (Exception e) {
e.printStackTrace();
}finally {
DaoUtils.close(connection,ps,rs);
}
return user;
}
}
复制代码5.5.4、DaoUtils
package dao.utils;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.Driver;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
/**
* @author Xiao_Lin
* @date 2021/1/2 19:56
*/
public class DaoUtils {
static Connection connection = null;
static Properties properties = null;
static {
InputStream resourceAsStream = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("db.properties");
properties = new Properties();
try {
properties.load(resourceAsStream);
Class.forName(properties.getProperty("DriverClassName"));
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection() throws SQLException {
connection= DriverManager.getConnection(properties.getProperty("url"),properties.getProperty("username"),properties.getProperty("password"));
return connection;
}
public static void close(Connection conn , PreparedStatement ps , ResultSet rs){
try {
if(rs!=null){
rs.close();
}
} catch (SQLException e) {
e.printStackTrace();
}finally{
try {
if(ps!=null){
ps.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
if(conn!=null){
conn.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
复制代码5.5.5、测试类
package dao.impl;
import dao.IUserDAO;
import dao.utils.DaoUtils;
import domain.User;
import java.sql.SQLException;
import java.util.List;
import org.junit.Test;
/**
* @author Xiao_Lin
* @date 2021/1/2 20:11
*/
public class UserDAOImplTest {
IUserDAO userDAO = new UserDAOImpl();
@Test
public void insert() {
userDAO.insert(new User("ghy","123"));
}
@Test
public void delete() {
userDAO.delete(14);
}
@Test
public void update() {
userDAO.update(new User(1,"张三","666"));
}
@Test
public void selectAll() {
List<User> users = userDAO.selectAll();
users.forEach(System.out::print);
}
@Test
public void selectUserById() {
User user = userDAO.selectUserById(1);
System.out.println(user);
}
}
复制代码六、操作BLOB类型字段
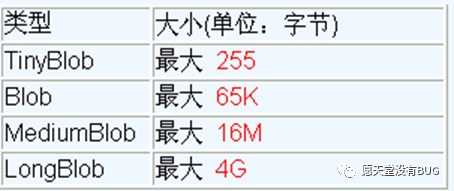
6.1、BLOB类型简介
MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。**插入BLOB类型的数据必须使用PreparedStatement,因为BLOB类型的数据无法使用字符串拼接写的。**MySQL有四种BLOB类型,他们除了在存储的最大信息量上不同外,除此之外他们是等同的。
如果在指定了相关的Blob类型以后,还报错:xxx too large,那么在mysql的安装目录下,找my.ini文件加上如下的配置参数:max_allowed_packet=16M。同时注意:修改了my.ini文件之后,需要重新启动mysql服务。
6.2、插入BLOB类型
//获取连接
Connection conn = JDBCUtils.getConnection();
String sql = "insert into customers(name,email,birth,photo)values(?,?,?,?)";
PreparedStatement ps = conn.prepareStatement(sql);
// 填充占位符
ps.setString(1, "张三");
ps.setString(2, "zs@126.com");
ps.setDate(3, new Date(new java.util.Date().getTime()));
// 操作Blob类型的变量
FileInputStream fis = new FileInputStream("zs.png");
ps.setBlob(4, fis);
//执行
ps.execute();
fis.close();
JDBCUtils.closeResource(conn, ps);
复制代码6.3、修改BLOB类型
Connection conn = JDBCUtils.getConnection();
String sql = "update customers set photo = ? where id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
// 填充占位符
// 操作Blob类型的变量
FileInputStream fis = new FileInputStream("coffee.png");
ps.setBlob(1, fis);
ps.setInt(2, 25);
ps.execute();
fis.close();
JDBCUtils.closeResource(conn, ps);
复制代码6.4、从数据库表中读取BLOG类型
String sql = "SELECT id, name, email, birth, photo FROM customer WHERE id = ?";
conn = getConnection();
ps = conn.prepareStatement(sql);
ps.setInt(1, 8);
rs = ps.executeQuery();
if(rs.next()){
Integer id = rs.getInt(1);
String name = rs.getString(2);
String email = rs.getString(3);
Date birth = rs.getDate(4);
Customer cust = new Customer(id, name, email, birth);
System.out.println(cust);
//读取Blob类型的字段
Blob photo = rs.getBlob(5);//这里也可以通过列的索引来读取
InputStream is = photo.getBinaryStream();
OutputStream os = new FileOutputStream("c.jpg");
byte [] buffer = new byte[1024];
int len = 0;
while((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
JDBCUtils.closeResource(conn, ps, rs);
if(is != null){
is.close();
}
if(os != null){
os.close();
}
}
复制代码七、批量处理
八、数据库事务
8.1、问题引出
案例: 银行转账, 从张无忌账户上给赵敏转 1000 块钱。
我们有一张account(账户表)。然后我们开始转账。
| id | name | balance |
|---|---|---|
| 1 | 张无忌 | 20000 |
| 2 | 赵敏 | 0 |
转账的步骤大概细分为以下几个步骤:
查询张无忌的账户余额是否大于等于1000。余额小于1000就提示温馨提示:亲,你的余额不足。如果余额大于等于1000转账。
SELECT * FROM account WHERE name = '张无忌' AND balance >= 1000;
复制代码从张无忌的账户余额中减少1000。
UPDATE account SET balance = balance - 1000 WHERE name = '张无忌';
复制代码在赵敏的账户余额中增加1000。
UPDATE account SET balance = balance + 1000 WHERE name = '赵敏';
复制代码这个时候问题来了,当程序执行到第②步和第③步之间,突然出现一个异常,此时会造成转账前后数据不一致的问题,会造成转账了,但是对方的账户上没有多钱。 造成这个问题的根本原因是因为转入转出是两个单独的操作,其中一个失败后,不会影响到另一个的执行。但是在转账这个业务中,我们需要保证进出两个操作要么都成功,要么都失败。
这个时候就需要引出事务的概念。
import org.junit.Test;
@Test
public void testTx() throws Exception {
// 贾琏欲执事
// 1 查询张无忌的账户余额是否大于等于1000
Connection conn = JDBCUtil.getConnection();
String sql = "SELECT * FROM account WHERE balance>=? AND name=?";
PreparedStatement pst = conn.prepareStatement(sql);
// 给 ? 设置数据
pst.setBigDecimal(1,new BigDecimal("1000"));
pst.setString(2,"张无忌");
ResultSet rs = pst.executeQuery();
if(!rs.next()){
System.out.println("余额不足");
return;
}
// 2 从张无忌的账户余额中减少1000.
sql = "UPDATE account SET balance = balance-? WHERE name=?";
pst = conn.prepareStatement(sql);
//设置? 的数据
pst.setBigDecimal(1,new BigDecimal("1000"));
pst.setString(2,"张无忌");
pst.executeUpdate();
// 模拟出异常
int a = 10/0;
// 3 在赵敏的账户余额中增加1000.
sql = "UPDATE account SET balance = balance+? WHERE name=?";
pst = conn.prepareStatement(sql);
//设置? 的数据
pst.setBigDecimal(1,new BigDecimal("1000"));
pst.setString(2,"赵敏");
pst.executeUpdate();
// 释放资源
JDBCUtil.close(conn,pst,rs);
}
复制代码8.2、事务
事务(Transaction,简写为tx):一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务处理(事务操作):保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务**回滚(rollback)**到最初状态。回滚可以看成是撤销操作。
为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
8.3、事务的ACID属性
原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
隔离性(Isolation)事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。
8.4、数据库的并发问题
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段。之后, 若 T2 回滚, T1读取的内容就是临时且无效的。
不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段。之后, T1再次读取同一个字段, 值就不同了。
幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行。之后, 如果 T1 再次读取同一个表, 就会多出几行。
8.4.1、事务的隔离性
数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题。
一个事务与其他事务隔离的程度称为隔离级别。数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱。
8.4.2、数据库的隔离级别
MySQL数据库支持4种事务隔离级别。Mysql 默认的事务隔离级别为: REPEATABLE READ。

8.4.3、设置隔离级别
每启动一个 mysql 程序, 就会获得一个单独的数据库连接. 每个数据库连接都有一个全局变量 @@tx_isolation, 表示当前的事务隔离级别。
8.4.3.1、查看当前的隔离级别
SELECT @@tx_isolation;
复制代码8.4.3.2、设置当前mysql隔离级别
set transaction isolation level read committed;
复制代码8.4.3.3、设置mysql的全局隔离级别
set global transaction isolation level read committed;
复制代码8.5、事务的操作步骤
先定义开始一个事务,然后对数据作修改操作。
执行过程中,如果没有问题就
提交(commit)事务,此时的修改将永久地保存下来。如果执行过程中有问题(异常),回滚事务(rollback),数据库管理系统将放弃所作的所有修改而回到
开始事务时的状态。
try{
//取消事务的自动提交机制,设置为手动提交.
connection对象.setAutoCommit(false);
//操作1
//操作2
//异常
//操作3
//....
//手动提交事务
connection对象.commit();
}catch(Exception e){
//处理异常
//回滚事务
connection对象.rollback();
}
复制代码8.6、事务的注意事项
在默认情况下,事务会在执行完DML操作后会自动提交。
在进行查询操作的时候一般是不需要事务的,但是我们一般也会在查询中写事务
在写代码的时候,如果代码完全正常没有异常,但是数据库中的数据没有任何改变的话,说明是没有提交事务。
在MySQL中,只有InnoDB存储引擎支持事务,支持外键,MyISAM是不支持事务的。
以后处理事务的时候,必须在service层中进行控制。
九、连接池
9.1、JDBC数据库连接池的必要性
在使用开发基于数据库的web程序时,传统的模式基本是按以下步骤:
在主程序中建立数据库连接。
进行sql操作。
断开数据库连接。
这种模式会存在几个很显著的问题:
普通的JDBC数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。**数据库的连接资源并没有得到很好的重复利用。**若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
**对于每一次数据库连接,使用完后都得断开,**否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。
这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。

9.2、数据库连接池
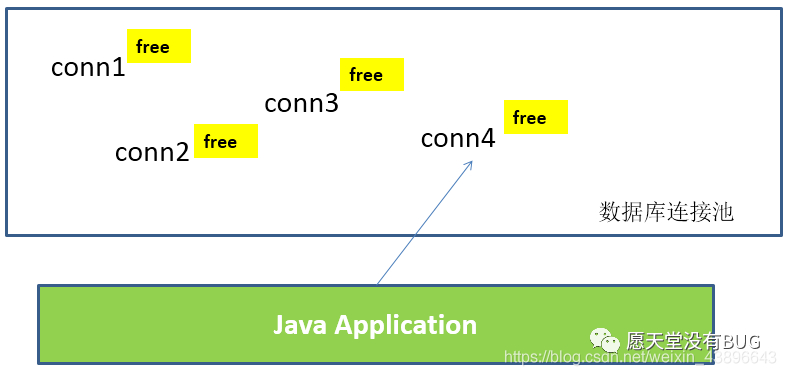
为解决传统开发中的数据库连接问题,我们可以采用数据库连接池技术。
数据库连接池的基本思想:就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
9.2.1、数据库连接池的原理以及优势
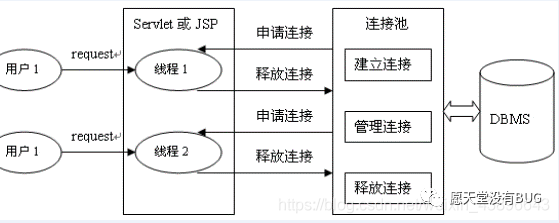
使用数据库连接池的优点也是很明显的:
资源重复使用
由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
更快的系统反应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间。
新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源。
统一的连接管理,避免数据库连接泄漏
在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
9.2.2、数据库连接池的属性
基本属性:连接池存了连接对象,而连接对象依赖四要素,所以四要素(driverClassName,url,username,password)是基本要求。
其他属性:对连接对象做限制的配置
1. 初始化连接数:在连接池中事先准备好初始化Connection对象。
2. 最多连接数:在连接池中最多有一定数量的Connection对象,其他客户端进入等待状态。
3. 最少连接数:在连接池中最少一定数量的Connection对象。
4. 最长等待时间:使用一定时间来申请获取Connection对象,如果时间到还没有申请到,则提示,自
动放弃。
5. 最长超时时间:如果你在一定时间之内没有任何动作,则认为是自动放弃Connection对象。
9.3、数据库连接池的分类
JDBC 的数据库连接池使用javax.sql.DataSource来表示,DataSource 只是一个接口,该接口通常由服务器(Weblogic, WebSphere, Tomcat)提供实现,也有一些开源组织提供实现:
DBCP 是Apache提供的数据库连接池。tomcat 服务器自带dbcp数据库连接池。速度相对c3p0较快,但因自身存在BUG,Hibernate3已不再提供支持。
C3P0 是一个开源组织提供的一个数据库连接池,**速度相对较慢,稳定性还可以。**hibernate官方推荐使用。
Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能,稳定性较c3p0差一点。
BoneCP 是一个开源组织提供的数据库连接池,速度快。
Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0 、Proxool 优点于一身的数据库连接池,但是速度不确定是否有BoneCP快。
DataSource 通常被称为数据源,它包含连接池和连接池管理两个部分,习惯上也经常把 DataSource 称为连接池,DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度。
注意:
数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。
当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close(); 但conn.close()并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
9.4、DBCP连接池
DBCP 是 Apache 软件基金组织下的开源连接池实现,该连接池依赖该组织下的另一个开源系统:Common-pool。如需使用该连接池实现,应在系统中增加如下两个 jar 文件:
Commons-dbcp.jar:连接池的实现
Commons-pool.jar:连接池实现的依赖库
**Tomcat 的连接池正是采用该连接池来实现的。**该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。
当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close(); 但上面的代码并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
9.4.1、DBCP属性说明
| 属性 | 默认值 | 说明 |
|---|---|---|
| initialSize | 0 | 连接池启动时创建的初始化连接数量 |
| maxActive | 8 | 连接池中可同时连接的最大的连接数 |
| maxIdle | 8 | 连接池中最大的空闲的连接数,超过的空闲连接将被释放,如果设置为负数表示不限制 |
| minIdle | 0 | 连接池中最小的空闲的连接数,低于这个数量会被创建新的连接。该参数越接近maxIdle,性能越好,因为连接的创建和销毁,都是需要消耗资源的;但是不能太大。 |
| maxWait | 无限制 | 最大等待时间,当没有可用连接时,连接池等待连接释放的最大时间,超过该时间限制会抛出异常,如果设置-1表示无限等待 |
| poolPreparedStatements | false | 开启池的Statement是否prepared |
| maxOpenPreparedStatements | 无限制 | 开启池的prepared 后的同时最大连接数 |
| minEvictableIdleTimeMillis | 连接池中连接,在时间段内一直空闲, 被逐出连接池的时间 | |
| removeAbandonedTimeout | 300 | 超过时间限制,回收没有用(废弃)的连接 |
| removeAbandoned | false | 超过removeAbandonedTimeout时间后,是否进 行没用连接(废弃)的回收 |
9.4.2、获取连接的方式
//使用dbcp数据库连接池的配置文件方式,获取数据库的连接:推荐
// 创建一个DataSource对象
private static DataSource source = null;
static{
try {
//创建一个Properties,用于读取配置文件
Properties pros = new Properties();
//读取配置文件
InputStream is = DBCPTest.class.getClassLoader().getResourceAsStream("db.properties");
//加载配置文件
pros.load(is);
//根据提供的BasicDataSourceFactory创建对应的DataSource对象
source = BasicDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection4() throws Exception {
Connection conn = source.getConnection();
return conn;
}
复制代码driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&useServerPrepStmts=false
username=root
password=123456
initialSize=10
#...
复制代码9.4.3、注意事项
由于使用了DBCP,所以配置文件的key我们必须按照他官方给定的要求来书写。
9.5、Druid(德鲁伊)连接池
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池,可以说是目前最好的连接池之一。
9.5.1、Druid参数详解
| 配置 | 缺省 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:”DataSource-” + System.identityHashCode(this) | |
| url | 连接数据库的url,不同数据库不一样。例如:mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:github.com/alibaba/dru… | |
| driverClassName | 根据url自动识别 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) | |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxOpenPreparedStatements | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| timeBetweenEvictionRunsMillis | 有两个含义:1)Destroy线程会检测连接的间隔时间2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 | |
| numTestsPerEvictionRun | 不再使用,一个DruidDataSource只支持一个EvictionRun | |
| minEvictableIdleTimeMillis | ||
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 当数据库抛出一些不可恢复的异常时,抛弃连接 | |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall | |
| proxyFilters | 类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
9.5.2、获取连接方式
package com.utils;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
import javax.sql.DataSource;
/**
* @author Xiao_Lin
* @date 2021/1/3 19:47
*/
public class DruidUtils {
static DataSource ds = null;
private DruidUtils(){
}
static {
InputStream stream = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("db.properties");
Properties properties = new Properties();
try {
properties.load(stream);
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection(){
try {
return ds.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
}
复制代码DriverClassName = com.mysql.jdbc.Driver
url = jdbc:mysql:///db?characterEncoding=utf-8&useSSL=false
username = root
password = 123456
复制代码9.5.3、注意事项
properties配置文件中的 key 一定要和 DruidDataSource 中对应的属性名一致。
port java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
import javax.sql.DataSource;
/**
@author Xiao_Lin
@date 2021/1/3 19:47
*/
public class DruidUtils {
static DataSource ds = null;
private DruidUtils(){
}
static {
InputStream stream = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("db.properties");
Properties properties = new Properties();
try {
properties.load(stream);
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
public static Connection getConnection(){
try {
return ds.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
}
```properties
DriverClassName = com.mysql.jdbc.Driver
url = jdbc:mysql:///db?characterEncoding=utf-8&useSSL=false
username = root
password = 123456作者:XiaoLin_Java
链接:https://juejin.cn/post/6986807373721501726
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。