
盘点一个pyquery库选择器提取案例
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
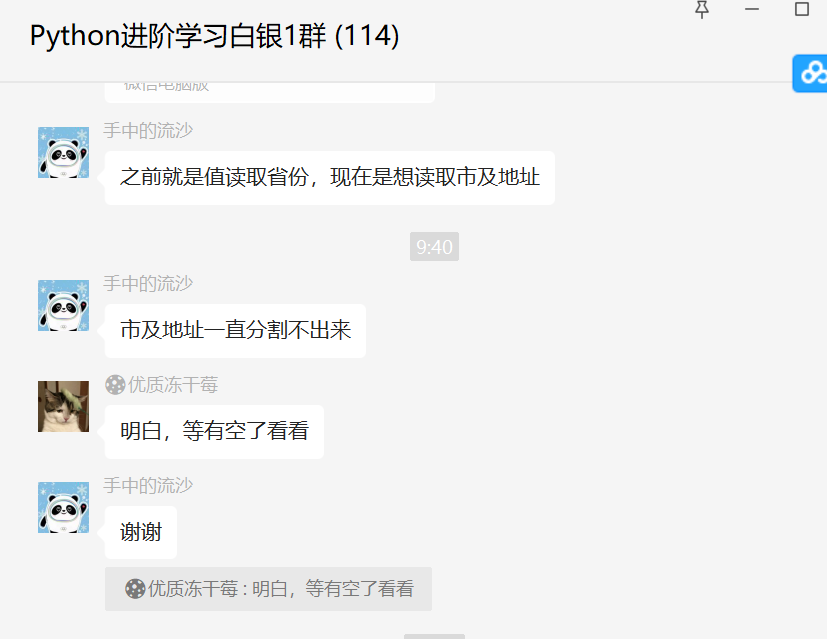
前几天在Python白银群有个叫【手中的流沙】的粉丝问了一道关于pyquery选择器提取的问题,如下图所示。

就像这样:
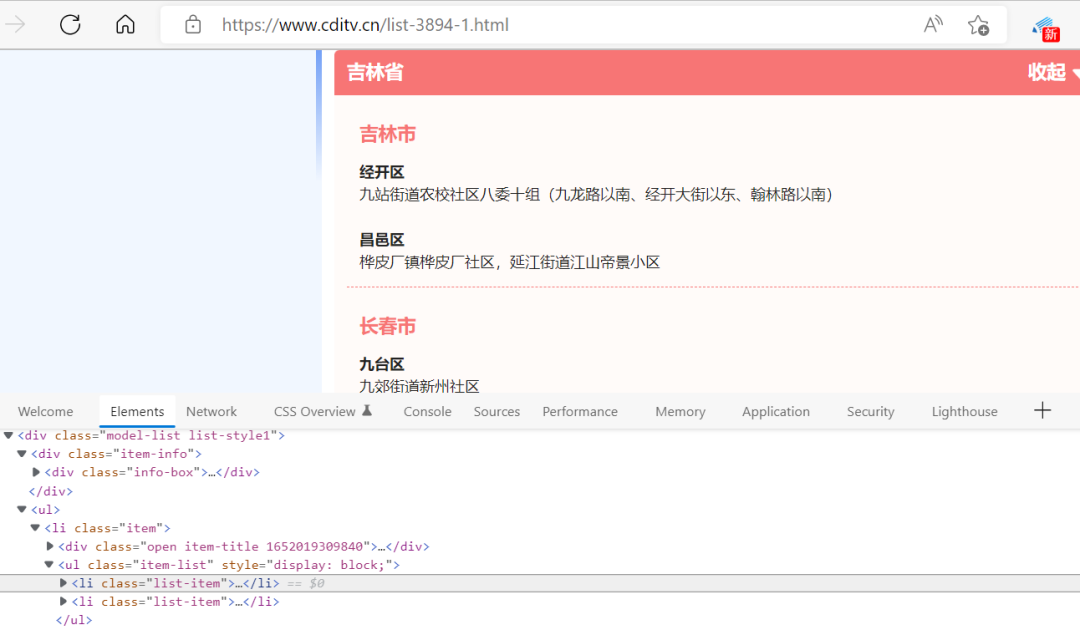
原网页的信息如下图所示:
实现过程
这里【甯同学】给了一份代码,如下所示:
from pyquery import PyQuery as pq
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
html = pq(url='https://www.cditv.cn/list-3894-1.html', headers=headers)
doc = pq(html)
li = doc('div.style-type3 > div:gt(0) > ul > li.item > ul > li.list-item').items()
for i in li:
info = {
'city': i.text().split('\n\n\n')
}
print(info)
代码运行之后,结果如下图所示:
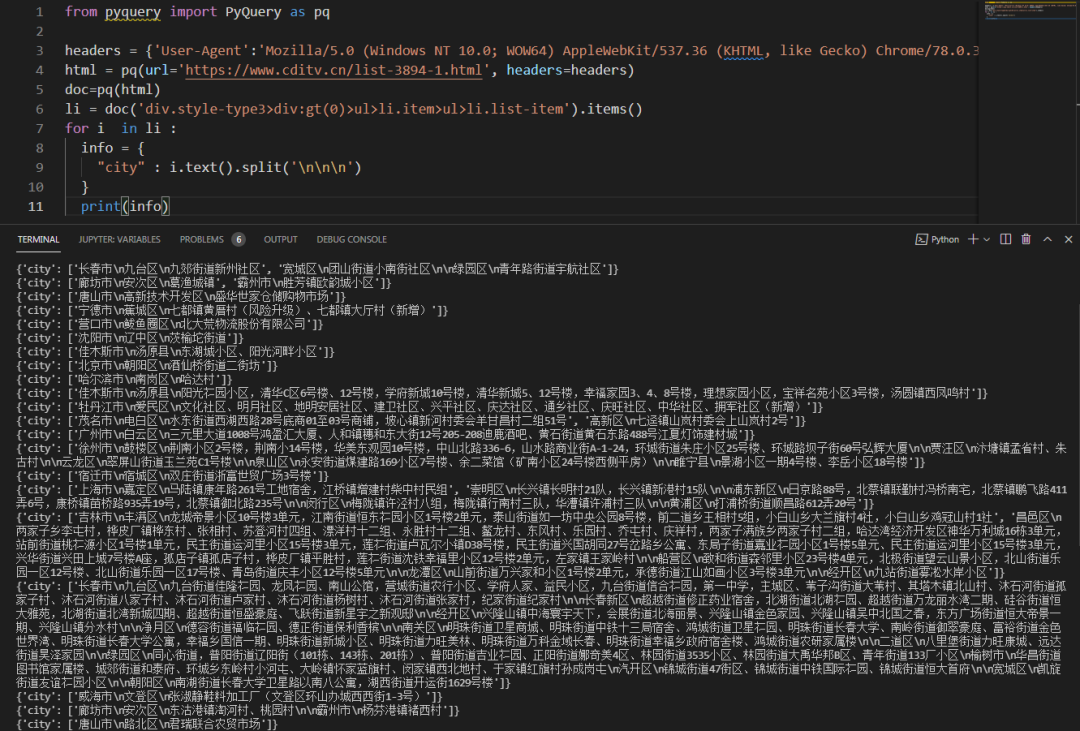
确实一步到位了,很强!原来pq可以直接请求网页,确实也省事了。主要是那个css构造还是需要点时间和精力的。
这个地方也还可以使用xpath提取来实现,代码如下:
import requests
from lxml import etree
res = requests.get(url='https://www.cditv.cn/list-3894-1.html', headers=headers)
res.encoding = res.apparent_encoding
html = etree.HTML(res.text)
li_lists = html.xpath('/html/body/div[1]/div[2]/div[2]/div[2]/ul/li')
print(len(li_lists))
for li in li_lists:
info = li.xpath('./ul//li//text()')
# shi = li.xpath('./ul//li/h4/text()')
# qu = li.xpath('./ul//li/strong/text()')
# jiedao = li.xpath('./ul//li/br/text()')
print(info)
运行之后,结果如下图所示:
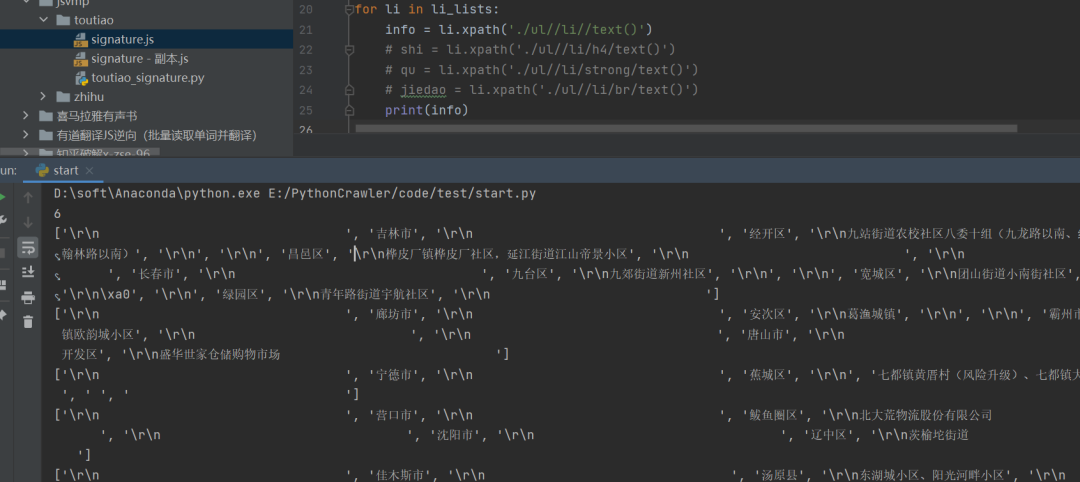
当然了,你还可以使用re正则表达式和bs4来提取,这个网页并不难,用来练手还是不错的。
三、总结
大家好,我是皮皮。这篇文章主要盘点一个pyquery库选择器提取案例!如果你还有其他方法,也欢迎大家积极尝试,一起学习,记得分享给我哦。
最后感谢粉丝【手中的流沙】提问,感谢【甯同学】、【dcpeng】在运行过程中给出的思路和代码建议,感谢粉丝【月神】、【庄大】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论