
10 种聚类算法的完整 Python 操作示例
大家好,我是东哥。分享一篇关于聚类的文章,10种聚类介绍和Python代码。
聚类是在输入数据的特征空间中查找自然组的无监督问题。
对于所有数据集,有许多不同的聚类算法和单一的最佳方法。
在 scikit-learn 机器学习库的 Python 中如何实现、适配和使用顶级聚类算法。
聚类
聚类算法
聚类算法示例
库安装
聚类数据集
亲和力传播
聚合聚类
BIRCH
DBSCAN
K-均值
Mini-Batch K-均值
Mean Shift
OPTICS
光谱聚类
高斯混合模型
一.聚类
聚类技术适用于没有要预测的类,而是将实例划分为自然组的情况。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
这些群集可能反映出在从中绘制实例的域中工作的某种机制,这种机制使某些实例彼此具有比它们与其余实例更强的相似性。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
该进化树可以被认为是人工聚类分析的结果; 将正常数据与异常值或异常分开可能会被认为是聚类问题; 根据自然行为将集群分开是一个集群问题,称为市场细分。
聚类是一种无监督学习技术,因此很难评估任何给定方法的输出质量。
—源自:《机器学习页:概率观点》2012。
二.聚类算法
聚类分析的所有目标的核心是被群集的各个对象之间的相似程度(或不同程度)的概念。聚类方法尝试根据提供给对象的相似性定义对对象进行分组。
—源自:《统计学习的要素:数据挖掘、推理和预测》,2016年
一些聚类算法要求您指定或猜测数据中要发现的群集的数量,而另一些算法要求指定观测之间的最小距离,其中示例可以被视为“关闭”或“连接”。因此,聚类分析是一个迭代过程,在该过程中,对所识别的群集的主观评估被反馈回算法配置的改变中,直到达到期望的或适当的结果。scikit-learn 库提供了一套不同的聚类算法供选择。下面列出了10种比较流行的算法:
亲和力传播
聚合聚类
BIRCH
DBSCAN
K-均值
Mini-Batch K-均值
Mean Shift
OPTICS
光谱聚类
高斯混合
三.聚类算法示例
首先,让我们安装库。不要跳过此步骤,因为你需要确保安装了最新版本。你可以使用 pip Python 安装程序安装 scikit-learn 存储库,如下所示:
sudo pip install scikit-learn
# 检查 scikit-learn 版本
import sklearn
print(sklearn.__version__)
0.22.1
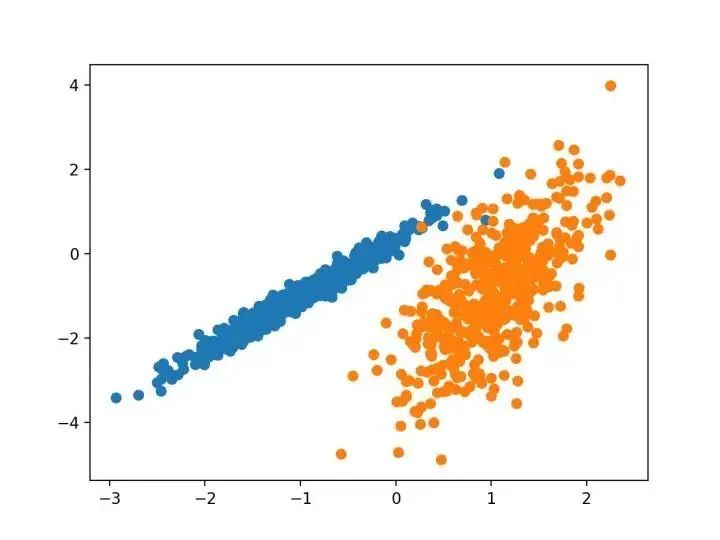
我们将使用 make _ classification ()函数创建一个测试二分类数据集。数据集将有1000个示例,每个类有两个输入要素和一个群集。这些群集在两个维度上是可见的,因此我们可以用散点图绘制数据,并通过指定的群集对图中的点进行颜色绘制。
这将有助于了解,至少在测试问题上,群集的识别能力如何。该测试问题中的群集基于多变量高斯,并非所有聚类算法都能有效地识别这些类型的群集。因此,本教程中的结果不应用作比较一般方法的基础。下面列出了创建和汇总合成聚类数据集的示例。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
# 定义数据集
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):
# 获取此类的示例的行索引
row_ix = where(y == class_value)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
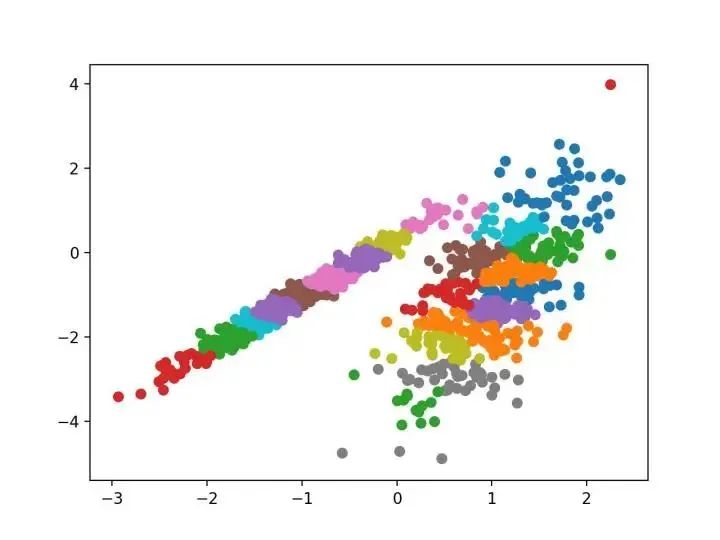
我们设计了一种名为“亲和传播”的方法,它作为两对数据点之间相似度的输入度量。在数据点之间交换实值消息,直到一组高质量的范例和相应的群集逐渐出现
—源自:《通过在数据点之间传递消息》2007。
它是通过 AffinityPropagation 类实现的,要调整的主要配置是将“ 阻尼 ”设置为0.5到1,甚至可能是“首选项”。
下面列出了完整的示例。
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
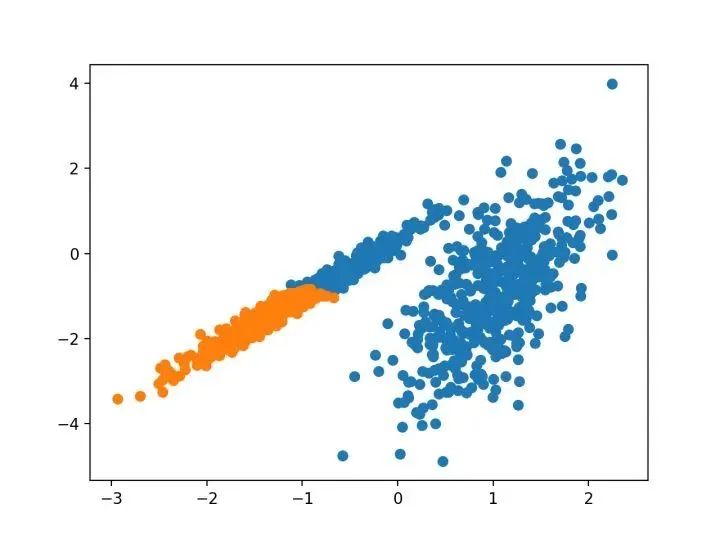
# 聚合聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
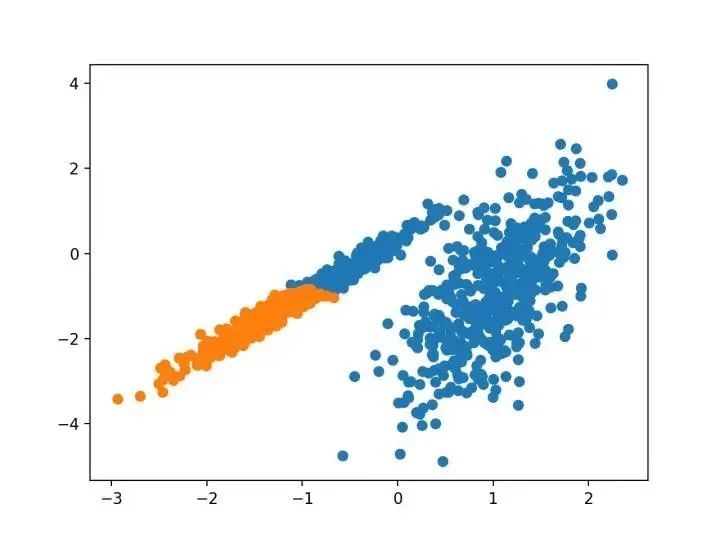
BIRCH 递增地和动态地群集传入的多维度量数据点,以尝试利用可用资源(即可用内存和时间约束)产生最佳质量的聚类。
—源自:《 BIRCH :1996年大型数据库的高效数据聚类方法》
# birch聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 适配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
…我们提出了新的聚类算法 DBSCAN 依赖于基于密度的概念的集群设计,以发现任意形状的集群。DBSCAN 只需要一个输入参数,并支持用户为其确定适当的值
-源自:《基于密度的噪声大空间数据库聚类发现算法》,1996
它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例。
# dbscan 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
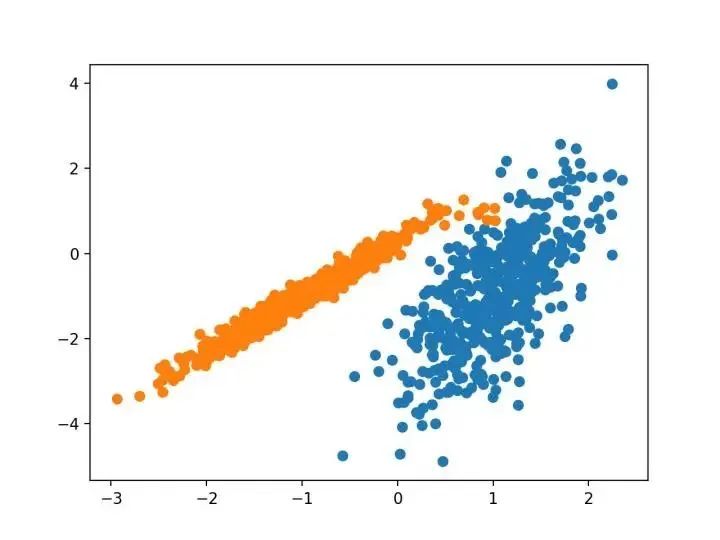
本文的主要目的是描述一种基于样本将 N 维种群划分为 k 个集合的过程。这个叫做“ K-均值”的过程似乎给出了在类内方差意义上相当有效的分区。
-源自:《关于多元观测的分类和分析的一些方法》1967年
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
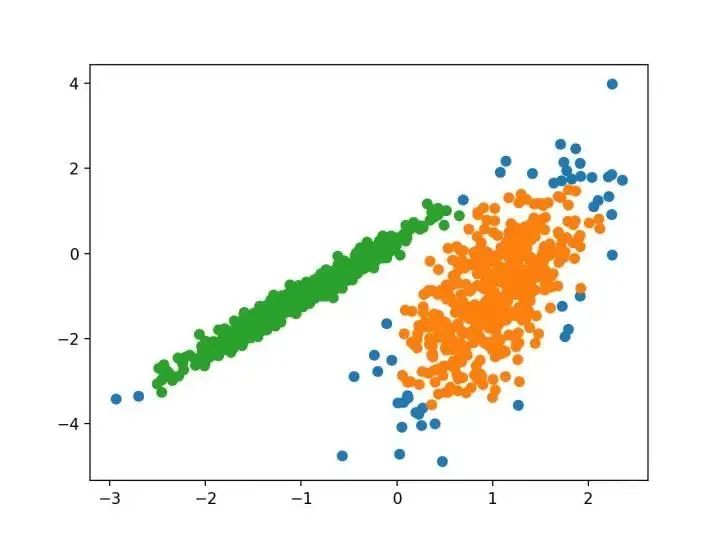
...我们建议使用 k-均值聚类的迷你批量优化。与经典批处理算法相比,这降低了计算成本的数量级,同时提供了比在线随机梯度下降更好的解决方案。
—源自:《Web-Scale K-均值聚类》2010
# mini-batch k均值聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
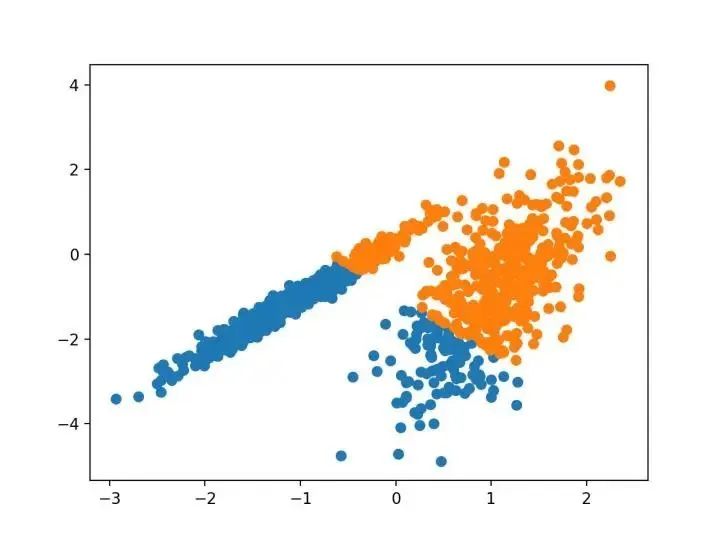
对离散数据证明了递推平均移位程序收敛到最接近驻点的基础密度函数,从而证明了它在检测密度模式中的应用。
—源自:《Mean Shift :面向特征空间分析的稳健方法》,2002
# 均值漂移聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MeanShift()
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
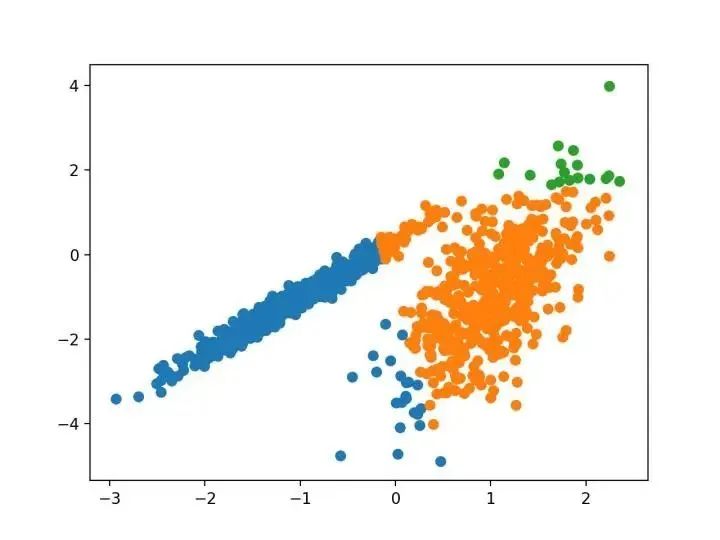
我们为聚类分析引入了一种新的算法,它不会显式地生成一个数据集的聚类;而是创建表示其基于密度的聚类结构的数据库的增强排序。此群集排序包含相当于密度聚类的信息,该信息对应于范围广泛的参数设置。
—源自:《OPTICS :排序点以标识聚类结构》,1999
# optics聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
最近在许多领域出现的一个有希望的替代方案是使用聚类的光谱方法。这里,使用从点之间的距离导出的矩阵的顶部特征向量。
—源自:《关于光谱聚类:分析和算法》,2002年
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
三.总结
聚类是在特征空间输入数据中发现自然组的无监督问题。
有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。
在 scikit-learn 机器学习库的 Python 中如何实现、适合和使用顶级聚类算法。
近期阅读学习推荐:
Python自动化处理Excel表格实战完整代码分享(课表解析)
如何找到我:
分享
收藏
点赞
在看



