
超强指南!推荐算法架构——重排

导语 | 重排技术细节非常多,一定要清楚技术架构大图,从而将细节串联起来。实际上主要是为了解决三大方面的问题:用户体验、算法效率、流量调控。
在上篇《图文解读:推荐算法架构——精排!》中我们结合算法架构精排进行解读分析,本篇将深入重排这部分进行阐述。
一、总体架构
精排打分完成后,就到了重排阶段,之后可能还会有混排。召回、精排、重排三个模块中,重排离最终的用户展现最近,所以也十分关键。重排的技术点也十分多,总结下来,个人认为重排主要是为了解决三大方面的问题:用户体验、算法效率、流量调控。下图是重排总体架构:
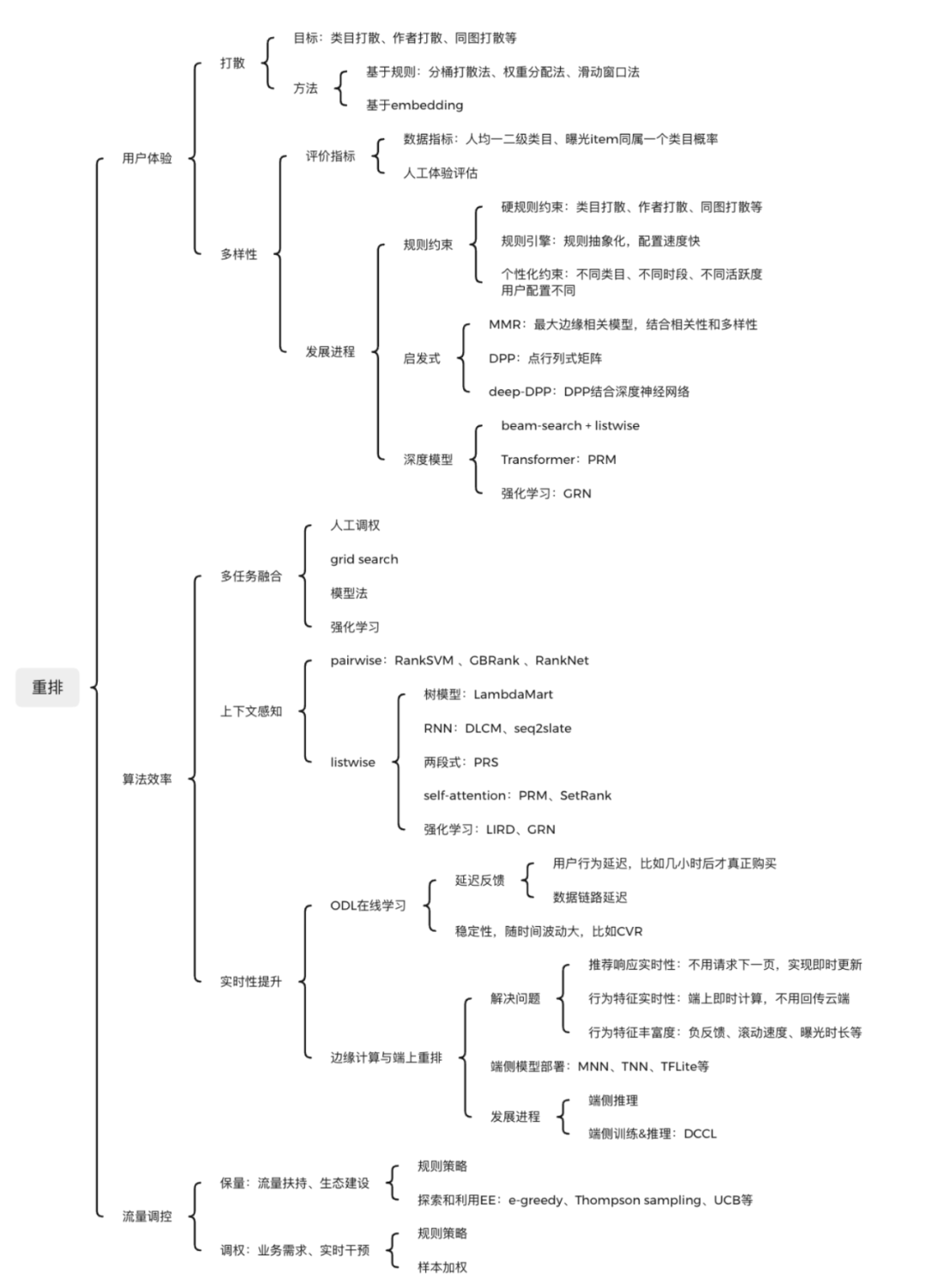
二、用户体验
重排模块是推荐系统最后一个模块(可能还会有混排),离用户最近。作为最后一层兜底,用户体验十分重要。主要包括打散、多样性等内容。曝光过滤有时候也会放在重排中,但本质上完全可以在召回链路,对已充分曝光的短视频,或者刚刚已经购买过的商品,进行过滤,从而防止用户抵触。
(一)打散
对同类目、同作者、相似封面图的item进行打散,可以有效防止用户疲劳和系统过度个性化,同时有利于探索和捕捉用户的潜在兴趣,对用户体验和长期目标都很关键。
打散问题一般可以定义为,输入一个item有序序列,每个item有几个需要隔离开的属性,输出一个相似属性分离开的item序列。打散可以基于规则,也可以基于embedding。基于规则比较简单可控,但由于item属性枚举值较多,可能需要频繁更新,扩展性不强。基于embedding的打散,泛化能力强,但容易出现bad case。目前主流方法仍然是基于规则的打散。
基于规则的打散主要有如下几种:
分桶打散法:将不同属性的item放入不同的桶中,依次从各桶中取出item即可。这种方法实现简单,打散效果好。但末尾容易扎堆。对原始序列改变较大,可能带来指标的下降。多属性叠加困难,扩展性也较差。
权重分配法:对每个item定义一个分数,计算公式如下:
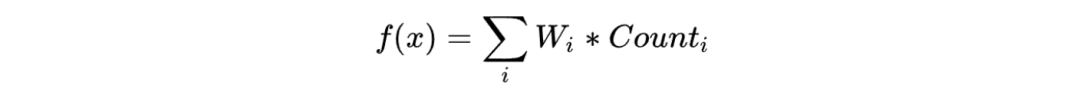
滑动窗口法:在一个长度可控的滑动窗口(session)内,同属性item超过一定次数后,就交换出session。这种方法只用考虑局部,不需要全局计算,因此计算量较低。同时对原序的破坏也比较低,最大限度保留相关性。但也会出现末尾扎堆的现象。
其中W为每个属性的权重,代表属性打散需求的优先级。Count为同属性item已经出现的次数。f(x)即为打散加权分数,按照它从低到高对item进行排序,即可完成打散。这种方法实现也比较容易,而且可以充分考虑多种属性的叠加,扩展性也很强。但仍然容易出现末尾扎堆。
(二)多样性
多样性是一个很大的话题,后面我们会作为专项来梳理。多样性会对用户体验、长期目标有比较关键的影响。召回、精排、重排全链路都要考虑多样性问题,但确实一般重排中考虑比较多一些,我们这儿也一起分析下。
评价指标
多样性评价可以使用两种方法:
数据指标分析:可以从user和item两个角度评估,比如平均每个用户的曝光一二级类目数,曝光item同属一个类目的概率等。可以从类目、作者、标签等多个维度进行数据分析和评价。
人工评估:抽样进行人工体验,评估多样性。
两种方法各有所长,一般还是需要结合一起使用。特别是人工体验评估,千万不可忽略。算法工程师也要经常去体验和对比自己的实际业务场景。
发展进程
个人认为多样性算法经历了三个阶段:
规则约束:基本都是基于规则,没有结合相关性来考虑多样性问题。主要有三种:
硬规则约束:比如类目打散、作者打散、同图打散等。一般业务初期都会采用这种方法,开发简单快速,没有实现配置化,所以扩展性不高。新的打散需求一般要重新开发和部署。
规则引擎:规则抽象化和配置化,上线速度快,新增需求只需要新增一个规则即可。
个性化约束:不同类目、不同时段、不同活跃度用户配置不同。比如手机和抽纸,他们的打散窗口可能会不同。不同活跃度人群,其耐受度也会不一样。
启发式方法:多样性和相关性相结合的方法,充分保留相关性。主要有:
MMR:最大边缘相关模型。1998年发表,比较老。参见The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
DPP:点行列式矩阵。NIPS2018。参见Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity
Deep-DPP:结合深度神经网络的DPP,CIKM2018,youtube。参见Practical Diversified Recommendations on YouTube with Determinantal Point Processes
深度模型:主要是加入了上下文感知,从而可以结合规则引擎实现多样性。这部分在与下一章节的上下文感知模块比较类似,放在那边统一梳理。
三、算法效率
重排对于提升算法准确率和效率,从而提升业务指标也十分关键。重排提升算法效率,主要分为三个方向:
多任务融合。精排输出的多个任务的分数,在重排阶段进行融合。可以基于人工调权、grid search、LTR或者强化学习。
上下文感知。精排由于计算性能因素,目前是基于point-wise的单点打分,没有考虑上下文因素。但其实序列中item的前后其他item,都对最终是否点击和转化有很大影响。context-aware的实现方式有pairwise、listwise、generative等多种方式。
实时性提升。重排比精排模型轻量化很多,也可以只对精排的topK重排,因此较容易实现在线学习(目前有一些团队甚至实现了精排在线学习)。实时性提升对于快速捕捉用户实时兴趣十分重要,能大大提升模型准确率和用户体验。通过ODL在线学习,实现重排模型实时更新,可以提升整体链路实时性。另外在端上部署模型,实现端上重排,也可以实现推荐的实时响应和特征的实时捕获。
(一)多任务融合
当前大多数业务场景需要优化多个任务,算法模型也已经实现了多任务学习,比如MMOE和PLE等。那模型输出的多个任务分数怎么融合呢?我们可以在精排阶段融合,也可以在重排阶段融合。由于重排模型相对精排要轻量级一些,容易实现在线学习,所以有不少场景放在重排阶段进行多任务融合。
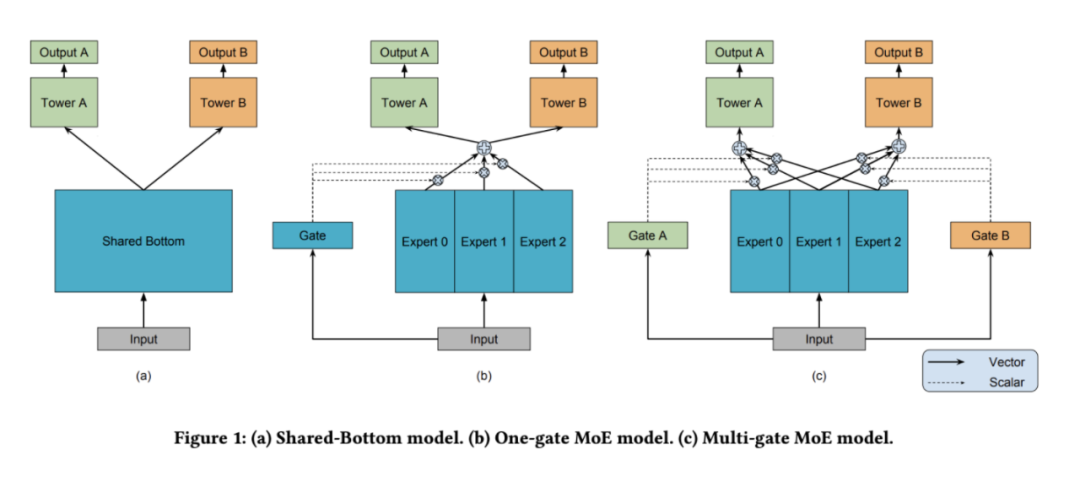
目前多任务融合主要有以下几种方式:
人工调权:通过专家先验知识,设置多任务融合的超参数。这种方式比较简单,业务发展初期通常采用。缺点也比较明显:
超参组合的选择依赖专家经验,准确率有限,有一定的效率浪费。
固定的超参不能快速自动适应业务和模型迭代,对整体链路算法效率有比较大的影响,甚至负向。
Grid search:将各参数可能的取值进行排列组合,穷举搜索所有的可能,再逐步输入系统中进行评估,选择效果最好的参数组合。相比人工调权,grid search显然更有可能找到最优的参数组合。但它缺点同样明显:
超参排列组合多,搜索空间大,十分耗时。超过4个超参后,计算量就要爆炸了。
难以进行在线AB,不能准确拿到用户反馈。这也是超参搜索空间大导致的。
同样不能自动适应业务和模型迭代,会成为整个链路的优化瓶颈。
模型法:将精排各任务的打分结果,采用线性模型或者比较轻量级的深度模型,构建监督学习。一般也可以将其他比较重要的特征,比如商品价格、销量、近期CTR、近期CVR,一起融合在重排模型中。由于精排的打分结果已经相当置信了,重排模型可以尽量轻量级一些,所以比较容易实现在线学习,实时更新特征和模型,提高重排模型的实时能力。模型法优点很多,在目前各业务场景中广泛使用。其缺点主要有:
仍然是基于point-wise的,没有上下文感知能力。
业务场景最终指标必须单一。重排模型做多任务融合,其监督目标必须是一个单一的任务,否则谁来融合重排呢?比如电商场景下订单量指标,一般会在精排构建CTR(曝光到点击)和CVR(点击到转化)两个任务,重排则统一成CTCVR(曝光到转化)即可。但如果还想把用户互动指标(比如收藏、分享、评论)也加入进来,则较难建模了。
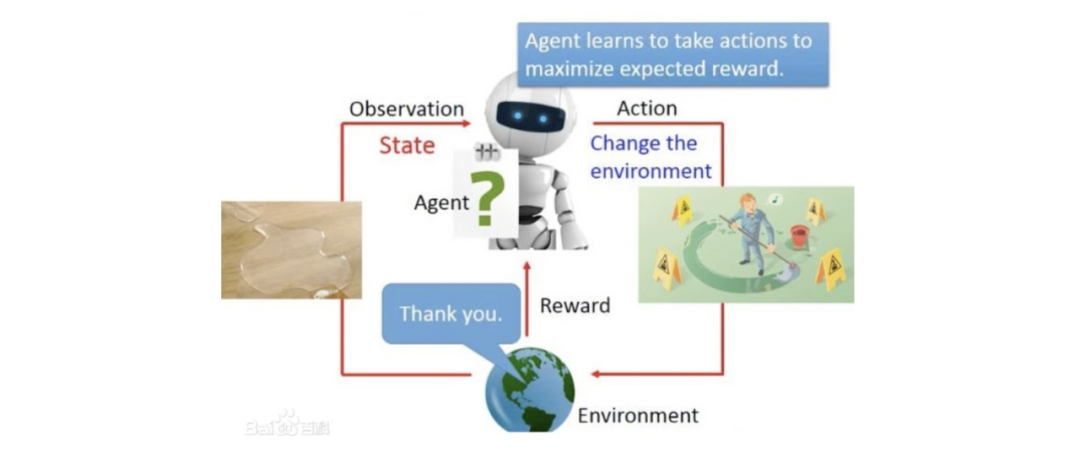
强化学习:根据用户在不同状态下的行为,利用强化学习建模状态转移过程,从而提升业务核心目标。state为用户特征,比如用户静态特征、统计特征等。Action为当前各任务的融合参数。reward可以根据业务场景定义,比如内容推荐场景中,一般为用户打开APP到退出的总时长。可以采用DQN、DDPG、A3C等方法。
(二)上下文感知
由于精排模型一般比较复杂,基于系统时延考虑,一般采用point-wise方式,并行对每个item进行打分。这就使得打分时缺少了上下文感知能力。用户最终是否会点击购买一个商品,除了和它自身有关外,和它周围其他的item也息息相关。重排一般比较轻量,可以加入上下文感知能力,提升推荐整体算法效率。
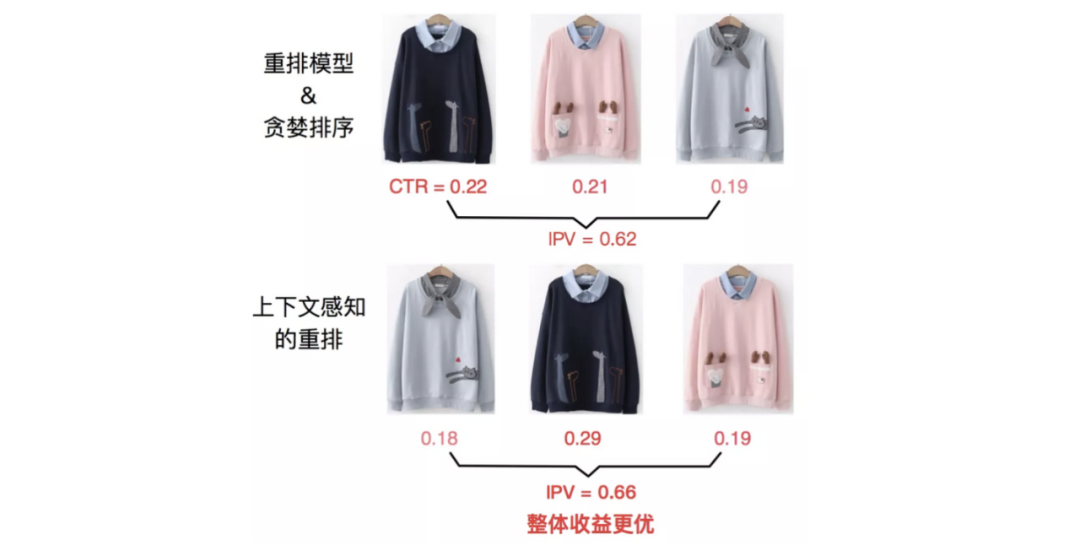
context-wise建模的方法主要有:pairwise和listwise两大类。
Pairwise
通过对比两个商品之间相对关系来构建,有一定的上下文感知能力,但仍然忽略了全局信息,而且造成了极大的计算和性能开销。这种方法有RankSVM、GBRank、RankNet、LambdaRank等经典的pairwise LTR方法。
Listwise
建模item序列整体信息,通过listwise损失函数来对比商品之间序列关系。可以通过DNN、RNN、self-attention等多种方式建模和提取item序列信息,再通过beam-search等贪婪搜索方法得到最终的序列。主要有五种建模方法:
树模型:LambdaMart等。
RNN:DLCM、seq2slate等,分别利用RNN+attention,和pointer-network来构建seq2seq模型。
两段式:PRS等,构建PMatch和PRank两个链路,通过两段式结构得到最终输出。
self-attention:PRM、SetRank等,和RNN模型比较像,将RNN替换成了self-attention,客服长程建模梯度弥散问题,以及串行计算耗时过大等。
强化学习:LIRD、GRN等。
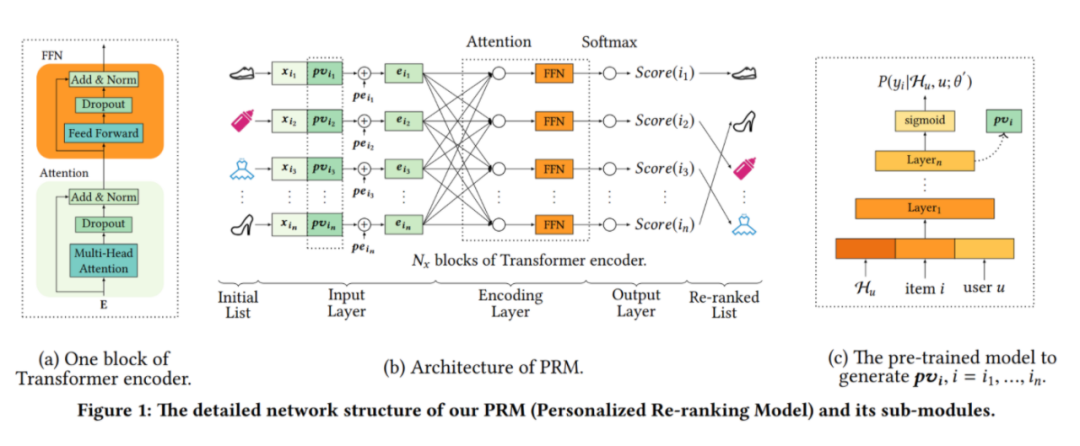
这儿简单介绍下PRM,它构建了input layer、encoding layer、output layer三层,通过self-attention使得序列内item充分交互,提取序列信息,通过贪婪搜索得到最终序列:
input layer输入层:得到排序阶段输出的有序序列,输入包括三部分:
每个item对应一个特征向量E。
user和item之间计算一个个性化向量PV,通过预训练模型得到。
item的位置编码PE。
encoding layer编码层:通过self-attention建模,每个位置输出一个编码后的向量
output layer输出层:编码层输出的每个位置的向量,通过一层线性层和softmax后,得到每个item的概率。通过beam-search等贪婪搜索方法,得到最终的序列。
整个过程和机器翻译等NLP场景任务很像,同样可以结合pointer-network来优化。paper地址:(https://arxiv.org/pdf/1904.06813.pdf)
(三)实时性提升
推荐系统的实时性也是一个比较大的话题。实时性对于提升用户体验,优化算法效率,都十分重要。实时性主要包括3方面:
系统响应实时性:考虑到推荐系统QPS压力,用户一次请求会下发多个item,浏览完后重新请求才会触发系统新的响应。系统响应实时性,对于用户实时行为捕捉十分关键。基于端上重排的系统,可以实现响应的实时性。
特征实时性:用户行为特征实时性、item统计特征实时性等。相对来说特征实时性是最容易做到的,也是对推荐效果影响最大的。特征实时性要考虑系统链路数据回收延迟,和用户本身行为延迟反馈问题。
模型实时性:在线学习,实时更新模型等。重排模型比较轻量,容易做到实时更新。精排相对来说困难一些,但也有一些团队实现了精排的在线深度学习ODL。
重排阶段提升实时性主要方法有,在线学习ODL和端上重排,下面详细讲解。
在线学习ODL
深度模型由于需要的训练数据和时间都比较大,资源消耗也比较多,故一般以离线训练为主。小时级或者天级更新。对于用户的实时行为pattern,或者冷启item都不是特别友好。特别在大促期间和秒杀场景,用户兴趣和需求转瞬即逝,商品也随时可能会被售空。我们这儿就不谈数据链路和推荐工程方面的工作了,算法方面主要的问题有:
延迟反馈:用户点击完商品后,可能大数据系统中需要几分钟甚至数小时后才收集到他的购买行为。延迟反馈显然对于label置信度是个很大的挑战。主要原因有数据链路延迟和用户行为延迟。flink收集数据有一定的链路delay,用户也可能犹豫几小时后才真正购买。延迟反馈需要平衡样本置信度和模型新鲜度。优化方法有:
负例校正法:先标记为负样本,等真正转化后再重新插入正样本。这种方法可以保证模型新鲜度,但假负例会对模型有一定的副作用。(https://dl.acm.org/doi/abs/10.1145/3298689.3347002)
等待法:一定时间内等待真实的成交转化,如果没等到,不管后续有没有,都不校正了。这种方法label置信度有一定提升,但模型新鲜度会有折损。
(https://arxiv.org/pdf/2002.02068.pdf)
纠偏法,例如ES-DFM,对观测转化分布和真实转化分布之间的关系建模,降低假负例的权重和增加真正例的权重,来纠正样本不置信问题。
(https://arxiv.org/pdf/2012.03245.pdf)
数据稳定性:数据随时间波动大,比如电商CVR。很多用户习惯白天浏览点击,晚上真正下单。所以CVR在晚上明显比白天高。这时候需要做一定的修正。也可以在线学习和离线增量学习相结合。每天固定一个时间点,对模型做一次天级离线增量更新。从而修正在线学习中积累的误差。
边缘计算与端上重排
边缘计算和端上重排这两年一直都很火,它可以有效降低云端负载,保证数据安全隐私性。同时也可以提升算法效率,算法侧的优点主要有:
推荐响应实时性:不用请求下一页,实现即时更新。
行为特征实时性:端上即时计算,不用回传云端。
行为特征丰富度:负反馈、滚动速度、曝光时长等多种用户行为都可以在模型中使用,基于云端的方式受限于数据传输和存储,一般只会选择点击等关键的用户行为。
端上重排需要将一个轻量级的模型,部署在端侧,实现端上推理。
四、流量调控
流量调控在推荐系统中也十分重要,重排在最后一环,责无旁贷。流量调控要兼顾实时性和准确性,二者之间需要达到平衡。流量调控的作用和方式主要有:
保量类:通过流量扶持,刺激生态建设。比如对冷启item,新热item,大V的新发布item,均可以给予一定的保量流量,让他们能够顺利透出和正循环。保量的实时性也十分重要,作者能第一时间看到自己item得到的点赞、评论等,有利于刺激他们持续创作。保量常见的方法有:
规则引擎:制订一定的策略规则,实现保量。这种方法简单易行,item也肯定能获得一定流量。但准确度较低,也较难实现个性化。流量容易不够或者超发。
探索和利用:通过e-greedy、Thompson sampling、UCB等EE类的方法,可以有效探索冷启item,同时利用已有item,保障效率折损最低。
调权类:一般是业务运营需求,需要快速实时干预。比如三八妇女节需要临时对美妆类item做加权,增加其流量。过了这一天可能效果就会大打折扣了。常见方法有:
规则引擎:直接在重排结果上,对于命中属性规则的item,加入一定的分数,使得最后可以透出,增加其流量。这种方法简单易行,实时性好。但调权准确率低,也较难个性化,可能造成较大的流量浪费和效率折损。适合某些时效要求高的场景。比如大促期间加权等。
样本加权:对于命中调权规则的样本,增加其在loss中的权重,迫使模型偏向于对它们精准预估。这种方法可以实现个性化,对效率折损较低。但由于需要训练模型并重新上线,故实时性不高。适合某些长期性的调权场景。比如对大店、大V的加权等。
作者简介

谢杨易
腾讯应用算法研究员
腾讯应用算法研究员,毕业于中国科学院,目前在腾讯负责视频推荐算法工作,有丰富的自然语言处理和搜索推荐算法经验。
推荐阅读
