Koan: 一段来自彭博社的公案

大数据文摘出品
来源:安迪的写作间
Ozan 面菜鸡:「CBOW 何不如 SG?」
曰:「实验云不如也」
Ozan 曰:「滚去吃茶去」
又曰:「实乃未标准化也」
gojomo 曰:「呵呵」
好摘的果实都已被摘走,只剩高高树顶上的,还有那零零散落在地上的果实渣。
最近已经看好几篇只是之前代码实现有 bug,然后 debug 一下就发论文的文章了。
这篇 koan: A Corrected CBOW Implementation,别看名字装逼无比,还用上了禅宗名词公案(Koan,当然如很多词一样是从日语过去的),但内容其实超简单。
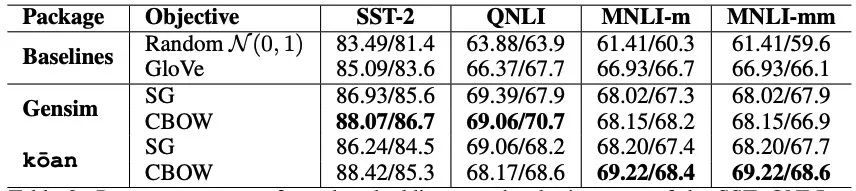
就是发现 Word2Vec 训练中 CBOW(Continuous Bag of Words) 之所以不如 SG(Skip-Gram),可能只是因为原始的 CBOW 实现有问题,因此作者 Debug 了一下,让 CBOW 效果媲美 SG,而且还保留了训练速度快的优点。
至于改了什么先按下,先介绍 CBOW 和 Skip-Gram。
CBOW 与 SG
相信准备过 NLP 面试的童鞋对这俩清楚得不能再清楚了,基本上是老师敲黑板的必考题。
两者是 Mikolov 在那篇超经典 Word2Vec 论文里提出的两种训练 Word2Wec 的方法,两者的不同其实只是视角的不同,利用的都是词意依赖于其所处上下文的思想。
SG 视角是从当前词来预测周围上下文词的角度。
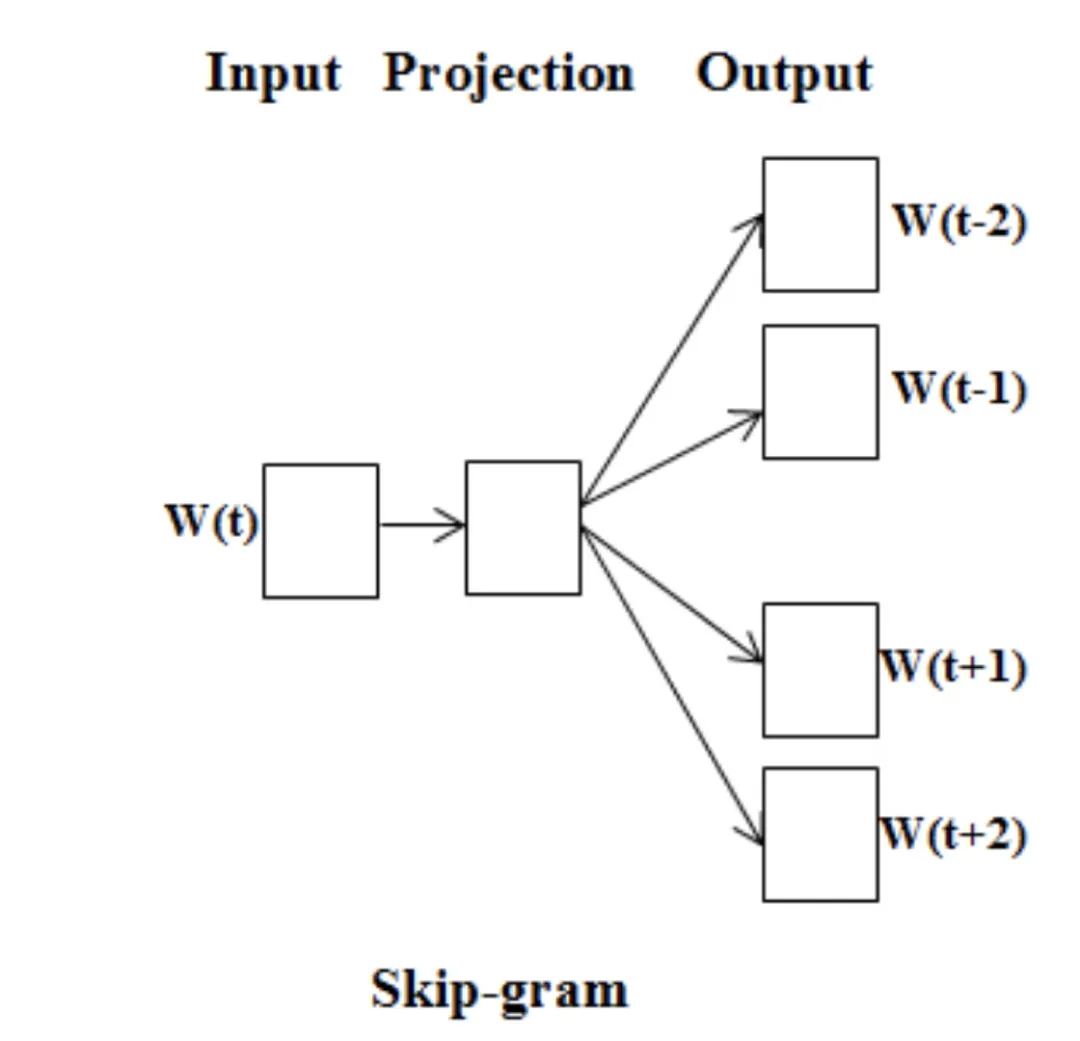
而 CBOW 的视角正好是反过来的,用上下文词来预测当前词。
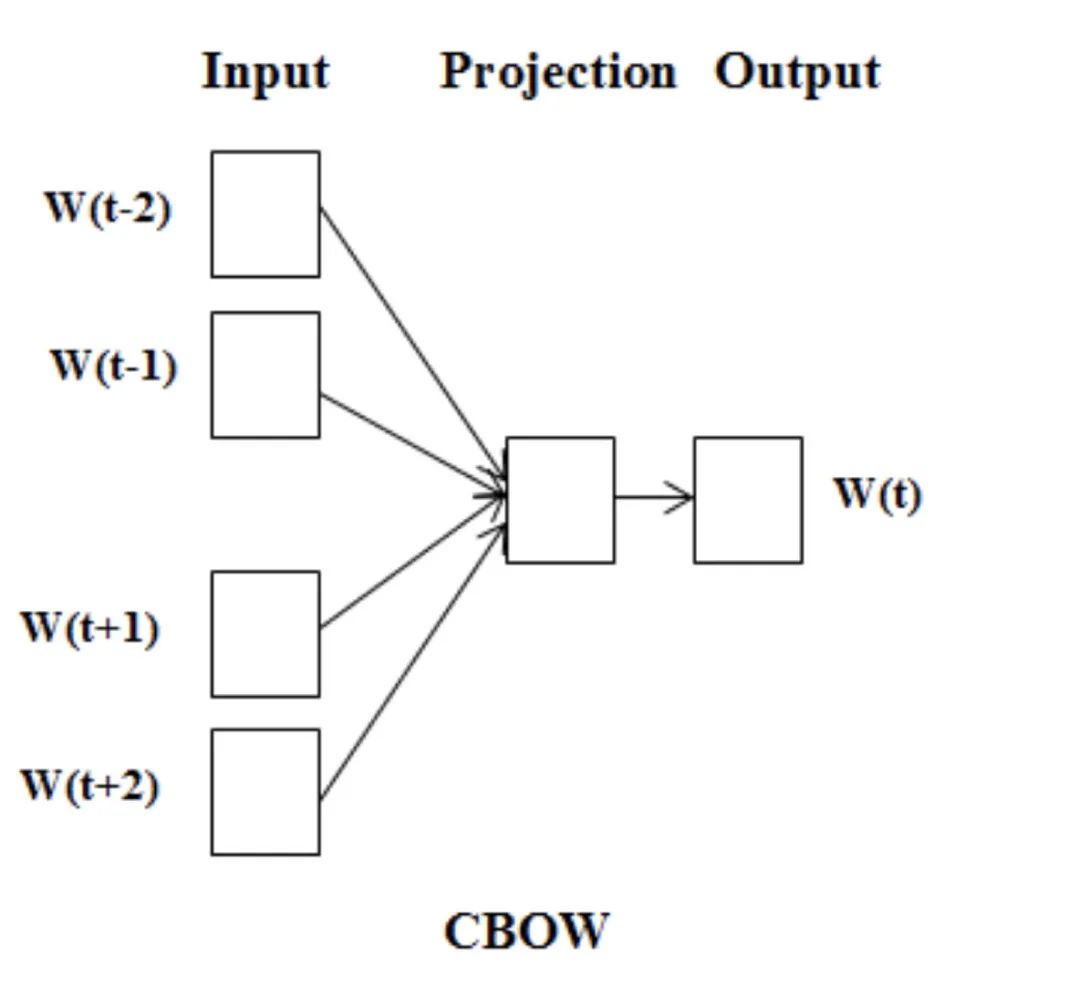
虽然两者本质思想一样,然而比什么都大的实验表示 SG 要比 CBOW 效果好,所以到现在基本上大家记 Word2Vec 好像都已经就默认 SG + Negative Sampling. 一定要说 CBOW 有啥好,那就是训练速度快些。
但 CBOW 形式却没有因为这次实验就被大家舍弃了,相反很多地方都有用到 CBOW 形式。最有名的,没错,聪明的童鞋已经想到了,那就是 BERT 的 MLM 目标,其实本质上和 CBOW 很类似,也是用上下文来预测当前词,只是 MLM 还有个注意力机制来分配权重。
此外,fastText 和 Sent2Vec 也都有用 CBOW。
那么,为什么 CBOW 就不如 Skip-gram 呢?
没有标准化(Normalization)!
作者们认为很大可能是因为原版 mikolov 实现有问题。
来推导下 CBOW 的梯度更新方程。
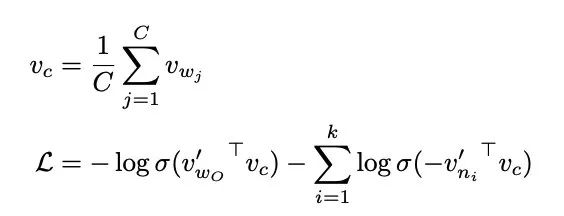
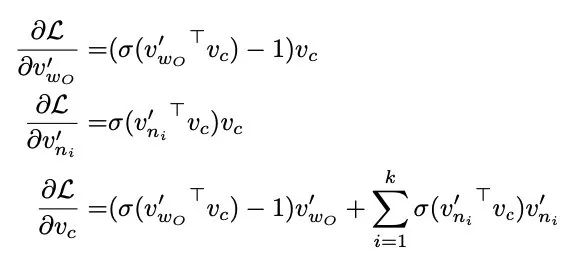
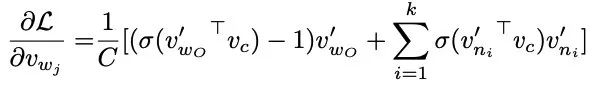
word2vec.c 以及 gensim 的实现有问题,没有除以 ,所以变成了直接用这个来更新了。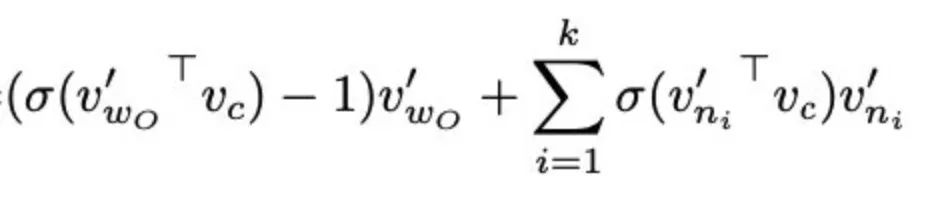
之前实现里,会有随机选择上下文窗口的过程,而这会导致如果不标准化的话,窗口大的就会获得更大的梯度,而小的梯度自然也就小。 没有标准化就相当于对 source 向量更新时加上了一个缩放,而这会导致算出来的随机梯度不在再是真正梯度的无偏估计了。

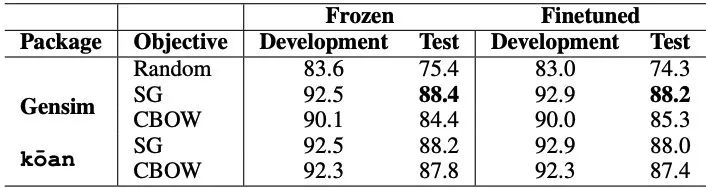
作者们声明:Gensim incorrectly update each context vector by Eq. (1), without normalizing by the number of context words.