
想更快的写完代码?dataclass 来帮你!
Python 3.7 增加了一个标准库 dataclasses,里面有个装饰器叫 dataclass,非常实用,可以大大提升代码的可读性,最重要的是它让你少写很多代码,从而大大节省你的时间,今天就来说说为什么你需要 dataclass。
假如你正在为一个评论系统编写代码,你新建了一个类,定义了几个成员变量,并为其编写了 init、repr 等魔术方法,代码如下:
class Comment:
def __init__(self, id: int, text: str):
self.id: int = id
self.text: str = text
def __repr__(self):
return "{}(id={}, text={})".format(self.__class__.__name__, self.id, self.text)
为了不能发表重复的评论,你为此编写了 __eq__,__ne__,为了支持评论的排序,你还编写了 __lt__,__gt__,__le__,__ge__,为了让对象可以被 hash,你还增加了 __hash__,代码是越来越长,每个函数都用到了成员变量,如下:
class Comment:
def __init__(self, id: int, text: str):
self.id: int = id
self.text: str = text
def __repr__(self):
return "{}(id={}, text={})".format(self.__class__.__name__, self.id, self.text)
def __eq__(self, other):
if other.__class__ is self.__class__:
return (self.id, self.text) == (other.id, other.text)
else:
return NotImplemented
def __ne__(self, other):
result = self.__eq__(other)
if result is NotImplemented:
return NotImplemented
else:
return not result
def __hash__(self):
return hash((self.__class__, self.id, self.text))
def __lt__(self, other):
if other.__class__ is self.__class__:
return (self.id, self.text) < (other.id, other.text)
else:
return NotImplemented
def __le__(self, other):
if other.__class__ is self.__class__:
return (self.id, self.text) <= (other.id, other.text)
else:
return NotImplemented
def __gt__(self, other):
if other.__class__ is self.__class__:
return (self.id, self.text) > (other.id, other.text)
else:
return NotImplemented
def __ge__(self, other):
if other.__class__ is self.__class__:
return (self.id, self.text) >= (other.id, other.text)
else:
return NotImplemented
现在,你突然想起还要加一个字段,就是评论者的 id:author_id,然后你不得不在每个函数里面都手动添加上这个字段,很麻烦,工作量相当于重写一个类了,如果不小心哪一个忘记添加了,这就是一个有 bug 的类。
问题是,后面还有可能增加字段或删除字段,有没有办法在我定义好类的成员变量之后,这些方法去自动更新?省的我改来改去?
有,这就是今天的 dataclass,借助于 dataclass,只需要这样就可以了:
from dataclasses import dataclass
@dataclass(frozen=True, order=True)
class Comment:
id: int
text: str = ""
代码简洁了许多,且字段后面可以加上类型提示,来增加可读性。
如果要加一个字段 author_id,直接加就可以了,一点也不麻烦:
from dataclasses import dataclass
@dataclass(frozen=True, order=True)
class Comment:
id: int
author_id: int
text: str = "" # 带有默认值的字段要放在后面
来验证一下:
import inspect
from dataclasses import dataclass
from pprint import pprint
@dataclass(frozen=True, order=True)
class Comment:
id: int
author_id: int
text: str = "" # 带有默认值的字段要放在后面
def main():
comment = Comment(1,2,"I just subscribed!")
print(comment)
# frozen = True 表示这是不可变对象,初始化后不能重新赋值
# comment.id = 3 # can't immutable
print(dataclasses.astuple(comment))
print(dataclasses.asdict(comment))
# 如果非要修改,可以这样
copy = dataclasses.replace(comment, id=3)
print(copy)
pprint(inspect.getmembers(Comment, inspect.isfunction))
if __name__ == '__main__':
main()
运行结果如下所示:
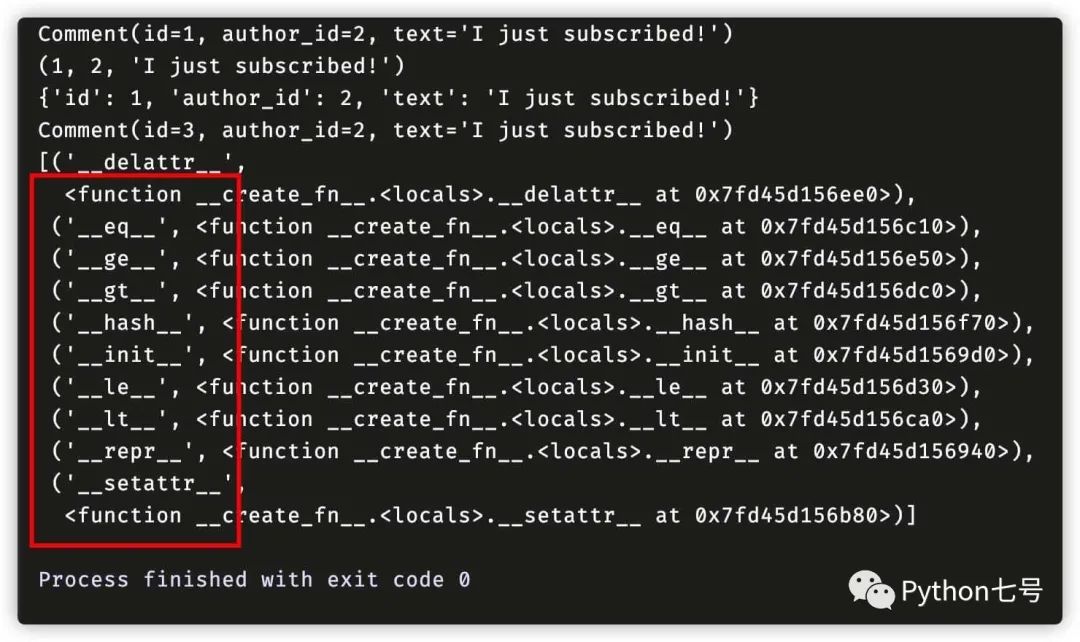
从上面最后的结果可以看出,dataclass 自动给我们编写了很多魔术方法,省去了自己手动编写的麻烦。注意上述的 frozen = True 表示对象是不可变对象,初始化完成之后,不可对成员重新赋值,这一点可以应用在固定对象,不可变的配置信息等应用场景下,非常实用。
我们来看下官方文档的函数签名:

也就是说,默认情况下会为我们生成 __init__、__repr__、__eq__ 这样的魔术方法。对应的参数传入 True 或 False 来控制那些魔术方法是否自动生成,比如说:
如果传入 order = True,则会生成 __lt__(), __le__(), __gt__(), __ge__()方法。如果 eq 和 frozen 都是 True,则会生成 __hash__方法
如果你仍然要自己动手写这些函数也是可以的,比如说:当你自定义了 __init__()时,init = x 这个参数会被忽略。
不想全部的字段都参与?
看到这里,你已经知道 dataclass 能够自动生成<,=,>,<=和>=这些比较方法。但是这些比较方法的一个缺陷是,它们使用类中的所有字段进行比较,有没有办法让某些字段不参与比较呢?当然可以,比如说我们有一个 class,包含姓名、年龄、身高,我们不希望姓名参与比较,就可以这样写:
from dataclasses import dataclass,field
@dataclass(order = True)
class User:
name: str = field(compare = False)
age: int
height: float
同样的,如果你不希望某个字段显示在 repr 中,那么可以可以指定 field(repr = False)。
最后的话
本文分享了 dataclass 的基本用法,它可以大大节省我们编写或修改代码的时间,同时给予我们最大的灵活控制,不会对类产生什么副作用,推荐 Pythoneer 们用起来。如果有帮助的话,还请三连「点赞、在看、分享」支持一下,感谢阅读!
关注我,每天学习一个 Python 小技术。