
隔壁厂员工进局子了!
有些技术,不能乱用!
大家好,我是鱼皮,今天分享点轻松的小技术知识~
提到 “程序员” 和 “局子”,你会联想到什么呢?
我首先想到的就是黑客,每年都有那么一批 “有志之士”,利用自己的技术去攻击别人的电脑、违反网络安全。
这不,最近我也被人盯上了,几个网站全部被大规模的 DDOS 攻击了。我把头发耗光了都没想明白,明明我这几个网站又不盈利,您攻击我干嘛呢?
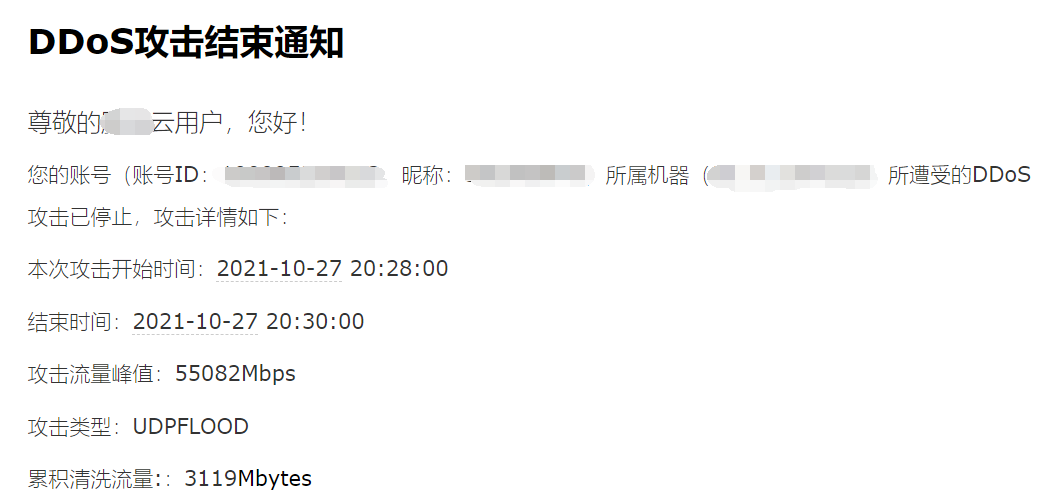
哎,不过怎么说呢,毕竟现在攻击别人网站的成本实在是太低了,网上很多现成的软件和代码,直接下载下来,输入目标,点下按钮,指哪打哪!
然后,搞不好你就进局子了。

除了黑客外,我第二个想到的就是爬虫,简单的说就是从网站上抓取数据,比如从表情包网站抓取图片。
俗话说的好,爬虫学的好,局子进的早。
爬虫虽然不像黑客攻击那样直接,但同样会对网站和企业造成威胁。比如爬虫的频率过高,可能影响网站的正常运营;爬虫的范围太大,可能会侵犯原网站的权益;非法爬取数据,可能会侵犯用户的隐私。

虽然使用爬虫可能有风险,但对于程序员来说,我们最好都去学习下爬虫。一方面是爬虫这种技术它的应用场景太多了,是获取数据必备的神技;另一方面只有你了解一项技术,才能更好地防范它。
如今实现爬虫也非常简单,基本什么编程语言都有现成的爬虫框架和类库,今天我就给大家分享一个超级无敌简单易用的 Java 爬虫库 —— jsoup 。
友情提示,适度爬虫益脑,过度爬虫伤身,请将技术用到正道!
jsoup
介绍
Java 爬虫库有很多,比如 crawler4j 等,但鱼皮独爱 jsoup,因为它用起来真的是太简单方便了!基本可以满足大部分简单的爬虫需求。
说是爬虫库,其实 jsoup 本质上是一款 Java 的 HTML 解析器,作用是从一段网页代码中提取出自己想要的片段。而这,正是爬虫中不可或缺的一步。
举个例子,假如我们要从一篇文章中得到作者的姓名,完整的网页代码可能是这样的:
<title>文章页title>
<body>
<h1>文章标题h1>
<div>作者姓名div>
<p>文章内容。。。p>
body>
那怎么从中取出作者姓名呢?
最直接的方式就是,用正则表达式匹配字符串,找到被 "
但那样太麻烦了,网页的内容灵活多变,有多少同学能写出符合要求的正则表达式呢?
因此,一般我们都会用到网页解析库,像 jsoup,支持使用类似前端 CSS 选择器的语法来解析和提取网页内容。
使用
它的用法真的很简单,直接打开 jsoup 官网,引入它。
然后只需 1 行代码,就能向网站发送请求,从而获取到页面内容:
Document doc = Jsoup
.connect("https://yupi.icu")
.get();
jsoup 会自动将网页内容封装到 Document 对象中,接下来,我们要取什么内容都很方便了:
// 取网页标题
String title = doc.title();
// 用选择器语法取多个网页链接
Elements lines = doc.select("#box a");
for (Element line : lines) {
// 获取链接标题
line.attr("title");
// 获取链接 url
line.absUrl("href");
}
此外,jsoup 还有处理网页数据的功能,也很简单,跟着官方文档提供的示例代码,很轻松就能上手~
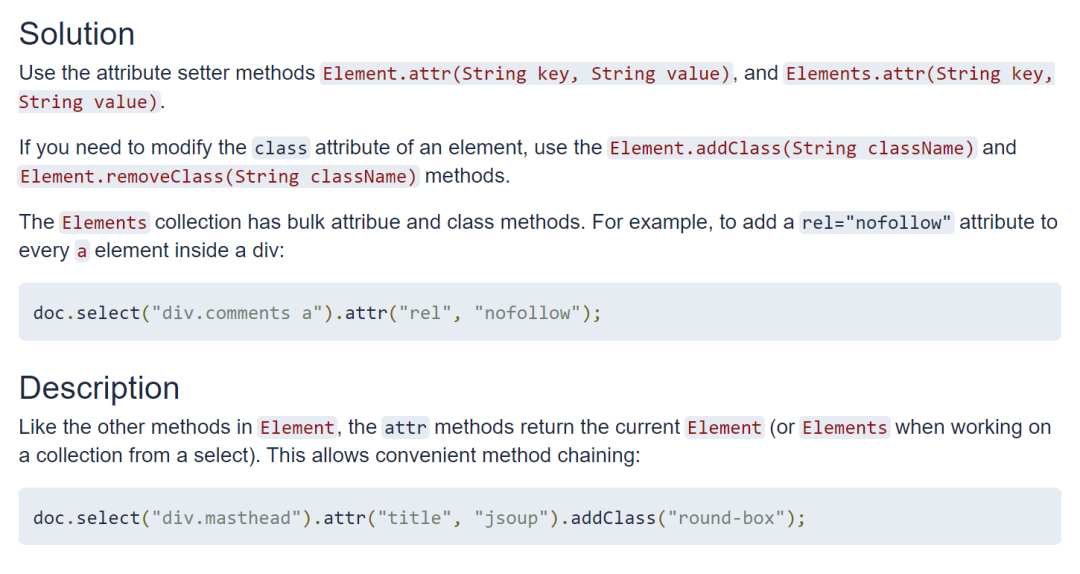
当然,jsoup 最主要的用途还是解析文档,真正的爬虫场景,往往没那么简单,感兴趣的朋友也可以去学学分布式爬虫框架、模拟登录、IP 代理池、无头浏览器、反爬、逆向等技术。
以上就是本期分享,我是鱼皮,点赞 + 在看 还是要求一下的,祝大家都能心想事成、发大财、行大运。

往期推荐