
Hudi 集成 | 百信银行基于 Apache Hudi 实时数据湖演进方案
背景 百信银行基于 Flink 的实时计算平台设计与实践 百信银行实时计算平台与实时数据湖的集成实践 百信银行实时数据湖的未来 总结
 GitHub 地址
GitHub 地址 一、背景
Flink,作为大数据实时计算领域的佼佼者,1.12 版本的发布让它进一步提升了统一计算引擎的能力; 同时随着数据湖技术 Hudi 的发展,统一存储引擎也迎来了新一代技术变革。
二、百信银行基于 Flink 的
实时计算平台设计与实践
1. 实时计算平台的定位
其核心功能具备了实时采集、实时计算、实时入库、复杂时间处理、规则引擎、可视化管理、一键配置、自主上线,和实时监控预警等。 目前其支持的场景有实时数仓、断点召回、智能风控、统一资产视图、反欺诈,和实时特征变量加工等。 并且,它服务着行内小微、信贷、反欺诈、消金、财务,和风险等众多业务线。
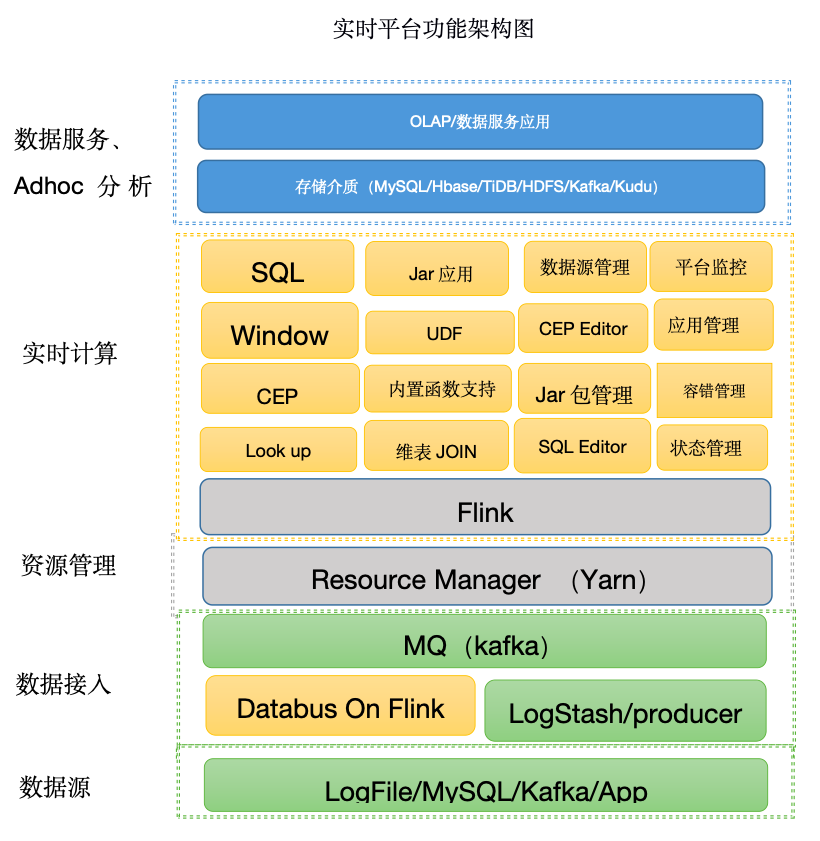
2. 实时计算平台的架构
■ 1)数据采集层
第一个场景是采集 MySQL 备库的 Binlog 日志到 Kafka 中。我行所使用的数据采集方案并没有采用业界普遍用的如 Canal,Debezium 等现有的 CDC 方案。 因为我们的 MySQL 版本为百信银行内部的版本,Binlog 协议有所不同,所以现有的技术方案不能很好的支持兼容我们获取 Binlog 日志。 同时,为了解决我们数据源 MySQL 的备库随时可能因为多机房切换,而造成采集数据丢失的情况。我们自研了读取 MySQL Binlog 的 Databus 项目,我们也将 Databus 逻辑转化成了 Flink 应用程序,并将其部署到了 Yarn 资源框架中,使 Databus 数据抽取可以做到高可用,且资源可控。 第二个场景是,我们对接了第三方的应用,这个第三方应用会将数据写入 Kafka,而写入 Kafka 有两种方式: 一种方式是依据我们定义的 Json shcema 协议。 (UMF协议:{col_name:””,umf_id":"","umf_ts":,"umf_op_":"i/u/d"}) 协议定义了 ”唯一 id”,”时间戳“ 和 ”操作类型“。根据此协议,用户可以指定对该消息的操作类型,分别是 "insert","update" 和 "delete",以便下游对消息进行针对性处理。 另外一种方式,用户直接把 JSON 类型的数据写到 kafka 中,不区分操作类型。
■ 2)数据计算转换层
■ 3)数据存储层
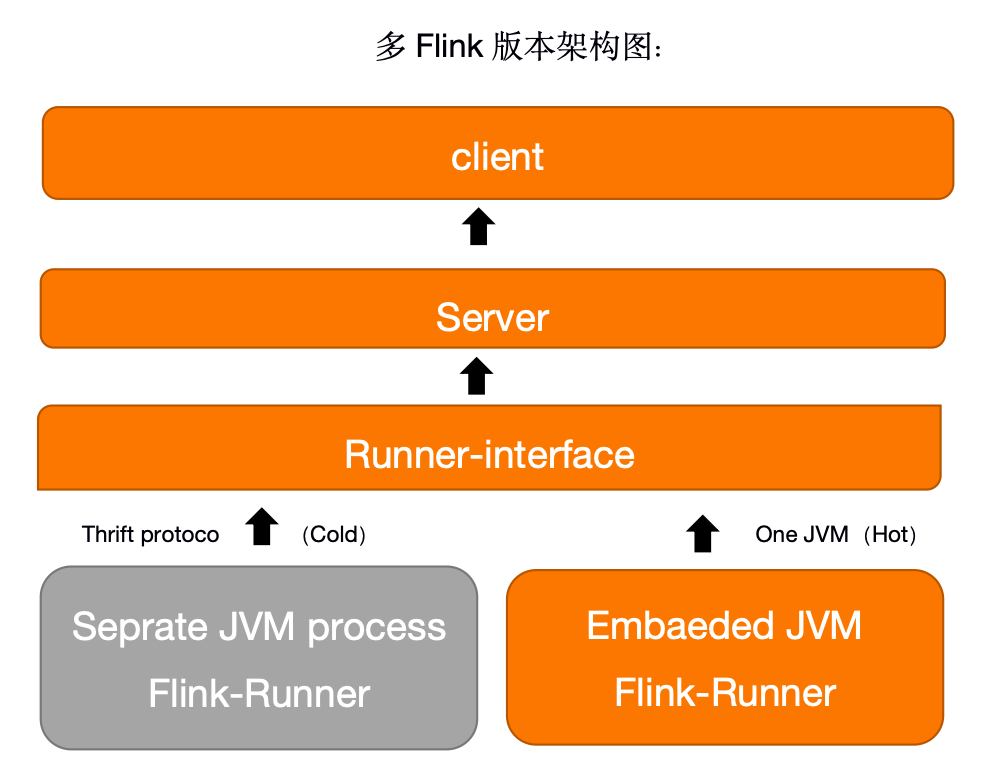
开发层面:
支持标准化的 DataBus 采集功能,该功能对于支持 MySQL Binglog 同步到 Kafka 做了同步适配,不需要用户干预配置过多。用户只需要指定数据源 MySQL 的实例就可以完成到 Kafka 的标准化同步。 支持用户可视化编辑 FlinkSQL。 支持用户自定义 Flink UDF 函数。 支持复杂事件处理(CEP)。 支持用户上传打包编译好 Flink 应用程序。 运维层面:
支持不同类型任务的状态管理,支持savepoint。 支持端到端的延迟监控,告警。
三、百信银行实时计算平台
与实时数据湖集成实践
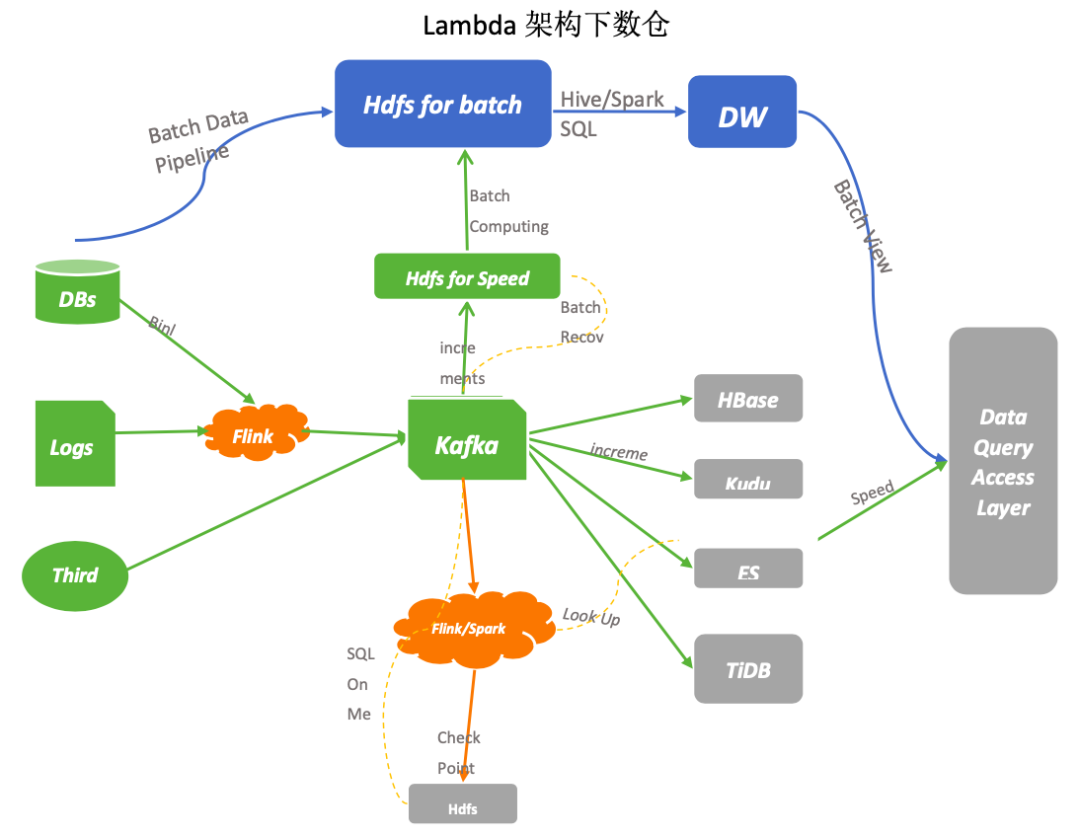
1. Lambda
同样的需求,开发和维护两套代码逻辑:批和流两套逻辑代码都需要开发和维护,并且需要维护合并的逻辑,且需同时上线; 计算和存储资源占用多:同样的计算逻辑计算两次,整体资源占用会增多; 数据具有二义性:两套计算逻辑,实时数据和批量数据经常对不上,准确性难以分辨; 重用 Kafka 消息队列:Kafka 保留往往按照天或者月保留,不能全量保留数据,无法使用现有的 adhoc 查询引擎分析。
2. Hudi
Update / Delete 记录:Hudi 使用细粒度的文件/记录级别索引,来支持 Update / Delete 记录,同时还提供写操作的事务保证,支持 ACID 语义。查询会处理最后一个提交的快照,并基于此输出结果; 变更流:Hudi 对获取数据变更提供了流的支持,可以从给定的时间点获取给定表中已 updated / inserted / deleted 的所有记录的增量流,可以查询不同时间的状态数据; 技术栈统一:可以兼容我们现有的 adhoc 查询引擎 presto,spark。 社区更新迭代速度快:已经支持 Flink 两种不同方式的的读写操作,如 COW 和 MOR。
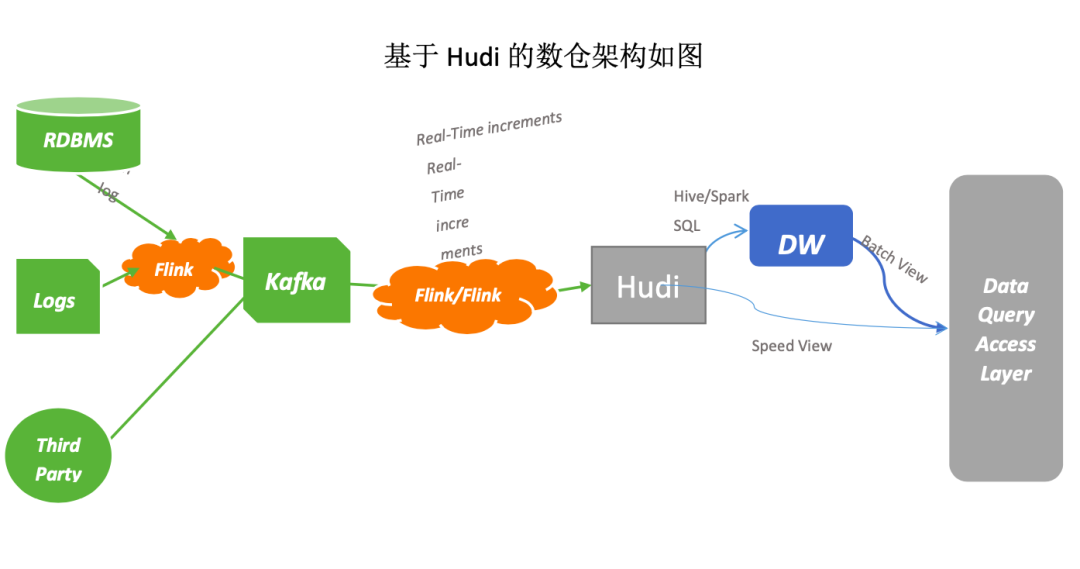
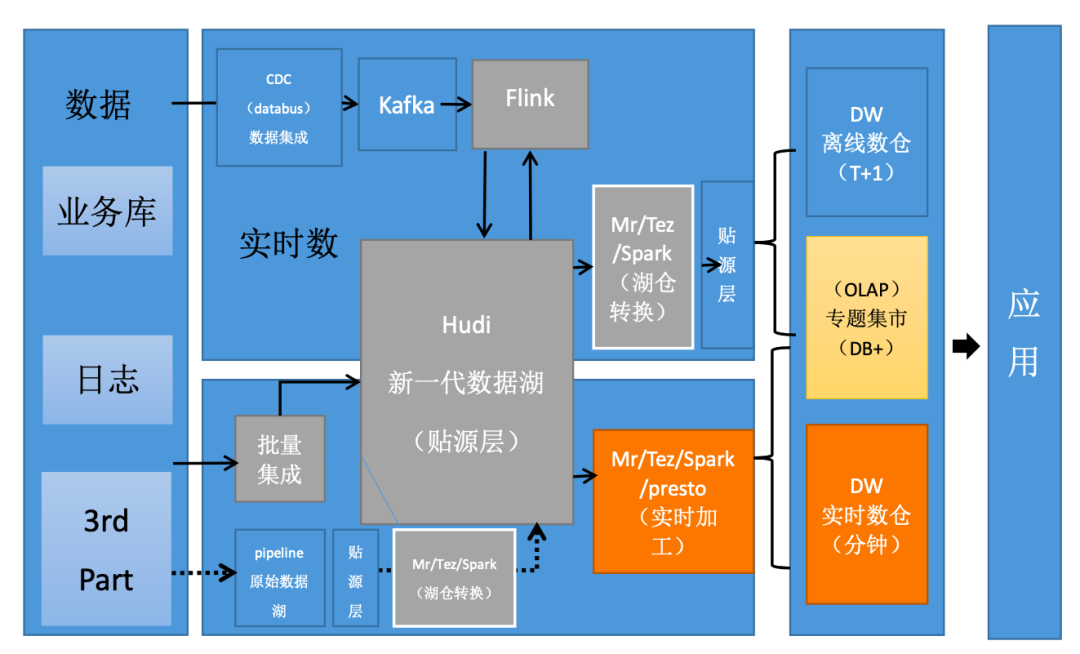
首先,我们可以看到,对于新的表的入仓逻辑,我们通过实时计算平台使用 Flink 写入到 datalake 中(新的贴源层,Hudi 格式存储),数据分析师和数据科学家,可以直接使用 datalake 层的数据进行数据分析和机器学习建模。如果数据仓库的模型需要使用 datalake 的数据源,需要一层转换 ODS 的逻辑,这里的转换逻辑分为两种情况:
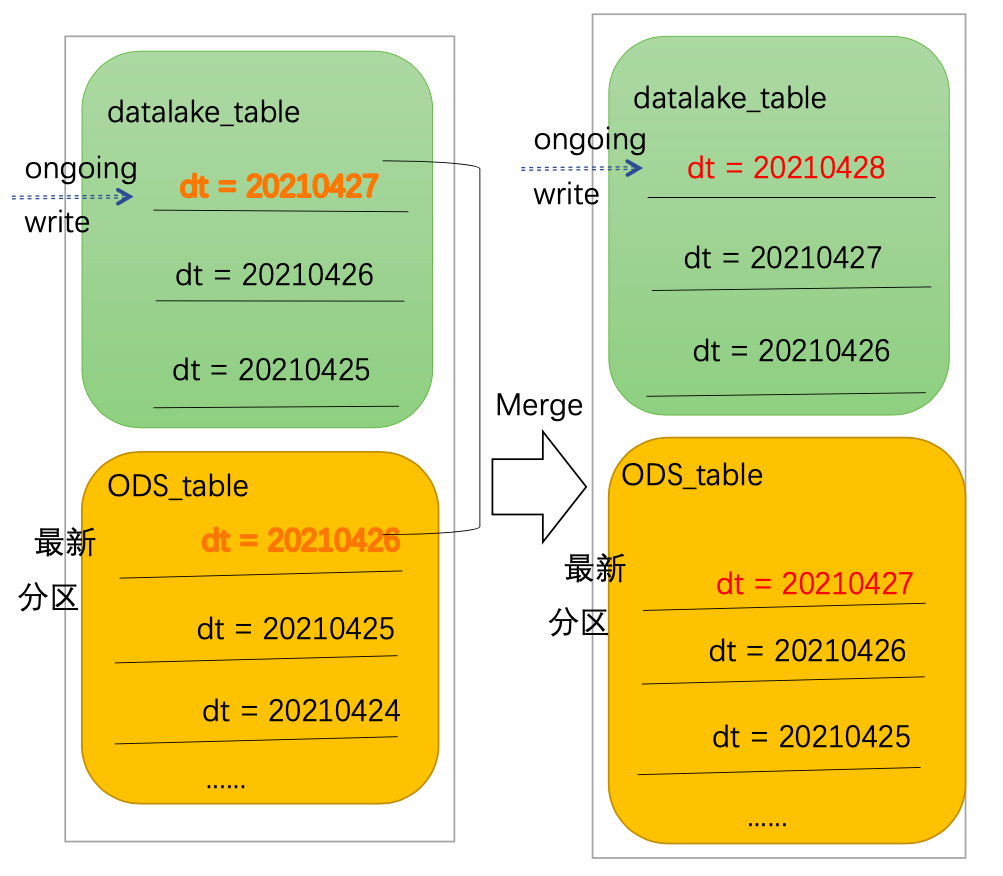
第一种,对于增量模型,用户只需要将最新 datalake 的分区使用快照查询放到 ODS 中即可。
第二种,对于全量模型,用户需要把 ODS 前一天的快照和 datalake 最新的快照查询的结果进行一次合并,形成最新的快照再放到 ODS 当前的分区中,以此类推。
另外,对于原始的 ODS 存在的数据,我们开发了将 ODS 层的数据进行了一次初始化入 datalake 的脚本。 如果 ODS 层数据每天是全量的快照,我们只将最新的一次快照数据初始化到 datalake 的相同分区,然后实时入 datalake 的链路接入; 如果 ODS 层的数据是增量的,我们暂时不做初始化,只在 datalake 中重新建一个实时入湖的链路,然后每天做一次增量日切到 ODS 中。 最后,如果是一次性入湖的数据,我们使用批量入湖的工具导入到 datalake 中即可。
3. 技术挑战
在我们调研的初期,Hudi 对 Flink 的支持不是很成熟,我们对 Spark - StrunctStreaming 做了大量的开发和测试。从我们 PoC 测试结果上看,
如果使用无分区的 COW 写入的方式,在千万级写入量的时候会发现写入越来越慢;
后来我们将无分区的改为增量分区的方式写入,速度提升了很多。
同时,随着 Flink 对 hudi 支持越来越好,我们的目标是打算将 Hudi 入湖的功能集成到实时计算平台。因此,我们把实时计算平台对 Hudi 做了集成和测试,期间也遇到一些问题,典型的问题有: 类冲突
不能找到 class 文件
rocksdb 冲突
当有依赖冲突时,我们会把 Flink 模块相关或者 Hudi 模块相关的冲突依赖 exclude 掉。
而如果有其他依赖包找不到的情况,我们会把相关的依赖通过 pom 文件引入进来。
在使用 Hudi on Flink 的方案中,也遇到了相关的问题,比如,checkpoint 太大导致 checkpoint 时间过长而引起的失败。这个问题,我们设置状态的 TTL 时间,把全量 checkpoint 改为增量 checkpoint,且提高并行度来解决。
COW 和 MOR 的选择。目前我们使用的 Hudi 表以 COW 居多,之所以选择 COW,
第一是因为我们目前历史存量 ODS 的数据都是一次性导入到 datalake 数据表中,不存在写放大的情况。
另外一个原因是,COW 的工作流比较简单,不会涉及到 compaction 这样的额外操作。
四、百信银行实时数据湖的未来
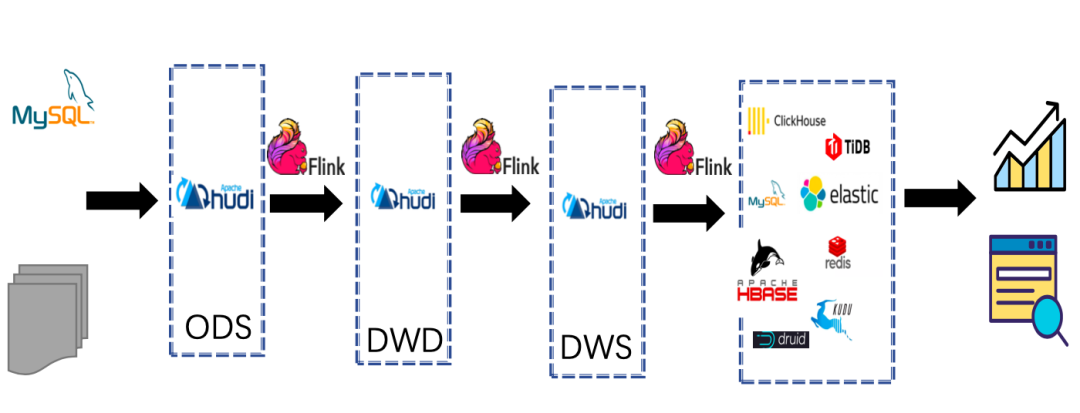
MQ 不再担任实时数据仓库存储的中间存储介质,而 Hudi 存储在 HDFS 上,可以存储海量数据集;
实时数据仓库中间层可以使用 OLAP 分析引擎查询中间结果数据; 真正意义上的批流一体,数据 T+1 延迟的问题得到解决; 读时 Schema 不再需要严格定义 Schema 类型,支持 schema evolution; 支持主键索引,数据查询效率数倍增加,并且支持 ACID 语义,保证数据不重复不丢失; Hudi 具有 Timeline 的功能,可以更多存储数据中间的状态数据,数据完备性更强。
五、总结
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼
 戳我,查看更多技术干货!
戳我,查看更多技术干货!