
声音,无限可能

by design-ai-lab


eva
(O_O)?
提供某人的一段讲话音频,你可以从两张人脸图像中判断出哪个是说话人吗?
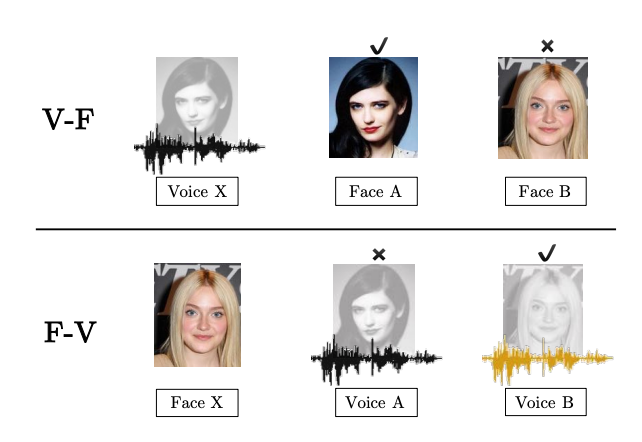
来自论文:
Seeing Voices and Hearing Faces: Cross-modal biometric matching
类似于“相由心生”,声音也是和面相有相关性的。
声音和其他模态信息的关联度,或者互动,真的非常有意思~~
@知识库

shadow

知识库
来啦~~
我们先从声音与健康说起~~

国际期刊《柳叶刀》有一篇《通过你的声音能诊断疾病吗?》
利用AI技术,可以通过个人设备,如手机、平板电脑等快速诊断疾病。关键技术是AI识别和处理人类的各种声音模式,包括音高、音调、节奏,呼吸轻缓、咳嗽等。这将极大改善医疗健康的服务模式,但在实践中仍需大量的数据验证。
VoiceWise
准确率高达95%
第一性原理:如果器官生病了,人的声音就会发生改变。
罗马Tor Vergata大学教授Giovanni Saggio开发了VoiceWise,该系统分析用户的声音,通过AI将6300个声音值与某些病理状态的声音值进行比较,从而诊断所患的病理。
 听声把脉!
听声把脉!
shadow

无界
 引用我超喜欢程序猿的一句diss用语:
引用我超喜欢程序猿的一句diss用语:
Talk is cheap ,
show me the code
知识库
还有音乐、互动体验方面的应用。@无界 这两个都是开源的。
有代码……
🔥 DeepSlayerXL
这是一个音乐专辑,基于Transformer-XL语言模型,学习了3604首俄罗斯MIDI歌曲的特征,自动生成金属音乐,除了音乐本身,作者还使用了GPT-3来生成各种各样的点评。
“DeepSlayerXL创作的曲目,听来还真有点意思,非常符合外行人对摇滚乐的印象”

🌍 谷歌Body Synth
Make music just by moving your body
用摄像头和AI识别人体姿态,然后通过肢体运动产生不同音色的音调,从而生成音乐。

音乐的创作过程其实也有组合:
将一小段音乐想法拼接和混搭起来创造出有趣的结合,并随着时间的进行变化多样。
shadow

opus
感谢今天的Mix分享~~
🤖✖️❤️
如果对以上话题感兴趣
👨🏼🎤👩🏻👨🏻💼👤🦸🏻🧑🏻🎤
欢迎加入社群,
关注后回复:群聊 ⤵️
