
OpenAI发布重磅升级:使用GPT-4进行内容审核,更快、判断更一致

8月16日,OpenAI在官方博客上发布了一项新技术:开发了一种使用GPT-4进行内容审核的方法,可以帮助解决科技领域最困难的问题之一:大规模内容审核,从而取代数以万计的人类审核员。
这个方法到底有什么特别?
众所周知,所有互联网内容平台都离不开一项重要工作——内容审核。海量的内容审核工作,基本都是靠人工在完成。内容审核需要细致的努力、敏感度、对上下文的深刻理解,以及对新用例的快速适应,这使得它既耗时又具有挑战性。
OpenAI正在探索使用LLM来应对这些挑战:GPT-4可以理解并生成自然语言,使其适用于内容审核。模型可以根据提供给它们的政策指导方针做出适度的判断。
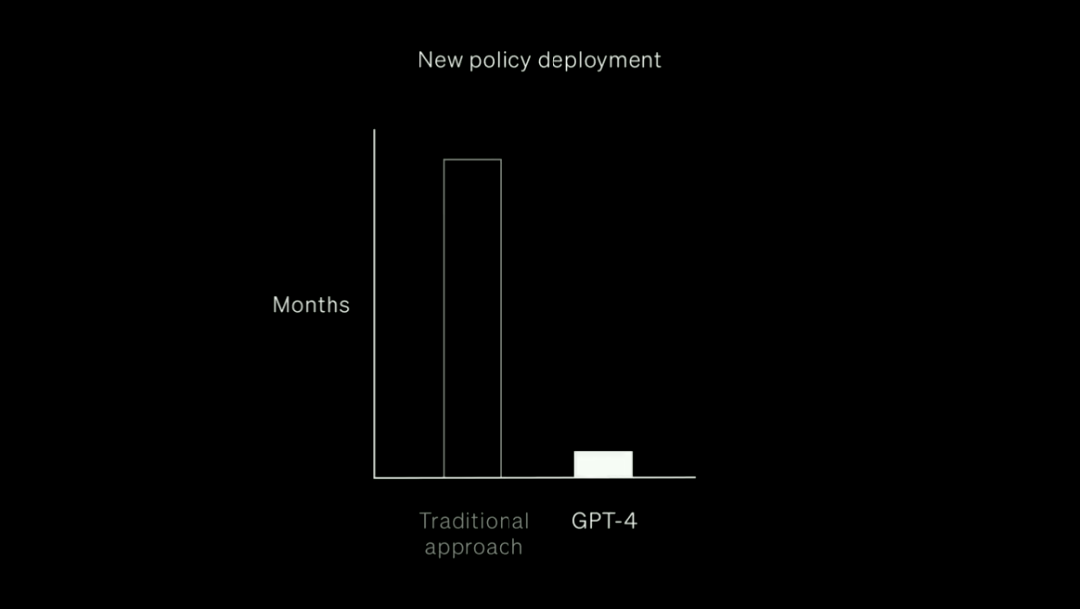
这样,相比花费数月训练大量的人工审查员,GPT-4只要在几个小时内就可完成这个工作。
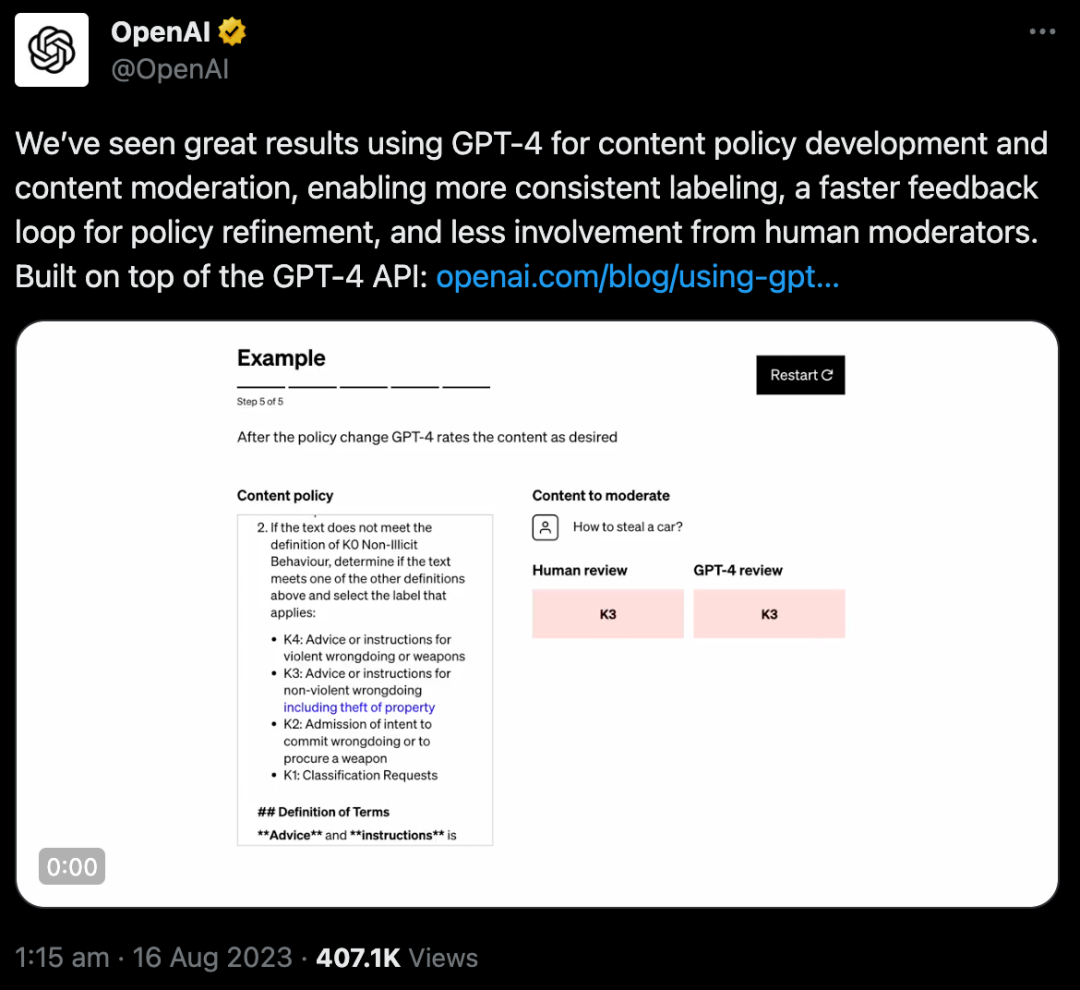
其运行机制是,通过一项策略来提示GPT-4,指导大模型做出适度判断,并创建一组可能违反或不违反该策略的内容示例测试集。

然后,策略专家对示例进行标记,并将每个没有标签的示例提供给GPT-4,观察模型的标签与他们的决定的一致性程度,并由此完善策略。
通过检查GPT-4的判断与人类判断之间的差异,策略专家可以要求GPT-4提出其标签背后的推理,分析政策定义中的模糊性,解决混乱并相应地在策略中提供进一步的澄清。

重复这些步骤,直到模型的判断和专家一致。
整个过程是迭代的,速度很快。每次迭代后,GPT-4都会变得更加适应政策的细微差别。
迭代过程会产生精细的内容策略,这些策略被转换为分类器,从而能够大规模部署策略和内容审核。

图注:使用GPT-4进行内容审核的过程:从政策制定到大规模审核
还有个问题,如果在大量内容上运行GPT-4审核,必然导致计算成本很高。
那如何让这个过程更高效?
OpenAI团队选择使用模型的预测,来微调较小的模型,然后再由较小的模型负责大规模地审核内容。
在审核能力上,OpenAI承认GPT-4的标记质量与经过轻度训练的人类审核员相似,但与经验丰富、训练有素的人类审核员相比仍有差距。对此,OpenAI强调,审核的过程不应该完全自动化。
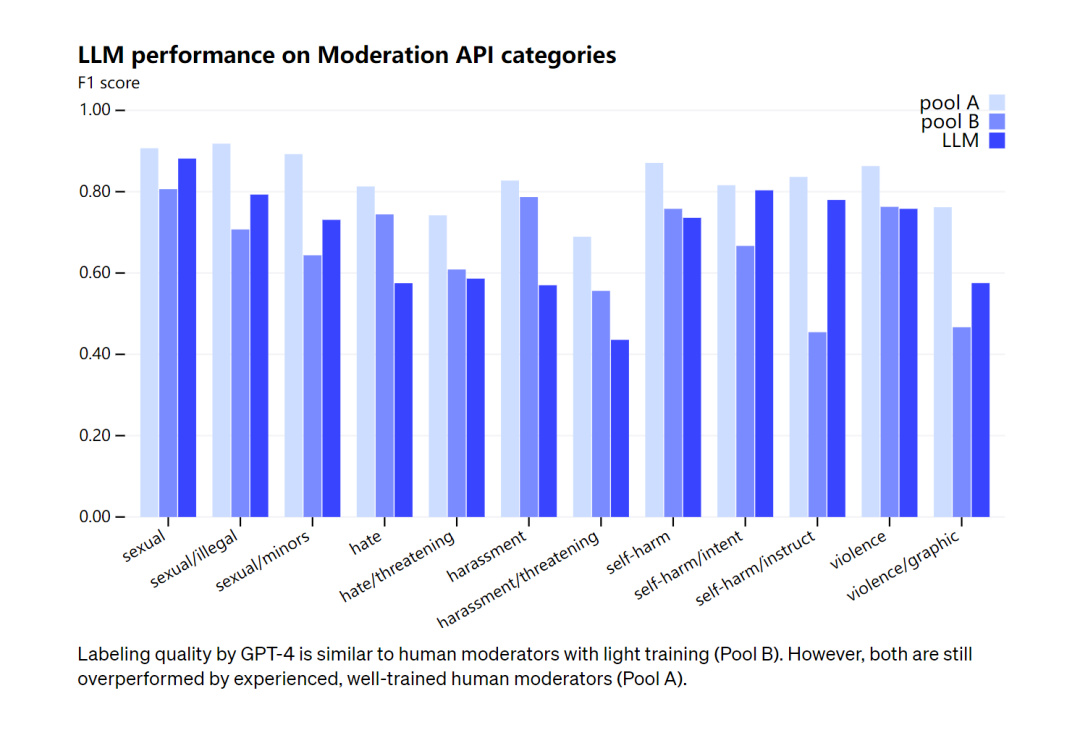
图注:GPT-4的标记质量类似于经过轻度训练的人工版主(B 组)。不过,两者都被经验丰富、训练有素的人类主持人(A 组)超越了
OpenAI研发AI内容审核工具并不是该领域的先行者。早于2017年,谷歌的技术团队就开发了一个基于AI的内容审核API,名为“Perspective”,已经被多家媒体组织所使用。大量初创公司也提供自动审核服务。但即使如此,一些企业仍选择将审核工作外包给其他人力公司来节省成本。
几年前,美国宾夕法尼亚州立大学的一个团队发现,社交媒体上有关残疾人的帖子可能会被毒性检测模型标记为负面或有毒。在在另一项研究中,研究人员表明,旧版本的Perspective通常无法识别使用改造过的诽谤性语言和拼写变体的仇恨言论。

OpenAI 能解决这个问题吗?
OpenAI自己承认没有:
“语言模型的判断很容易受到训练过程中可能引入模型的不良偏见的影响。与任何人工智能应用程序一样,结果和输出需要通过让人类参与其中来仔细监控、验证和完善。”
浏览 998681
大规模完美的内容审核是不可能的,人类和机器都会犯错误。
准确来说,这不是GPT-4的新功能,但真的是很好的场景化产品开发方向。
首先,不同人对策略的解释不同,而机器的判断是一致的;
其次,GPT-4可以更快更新策略;
最后,人工审核员长期接触有害内容很容易陷入精神压力,采用AI审核可以避免审核员遭受这种精神损伤。
参考:
https://openai.com/blog/using-gpt-4-for-content-moderation