
Dubbo 服务拥堵,怎么办??

Java技术栈
www.javastack.cn
关注阅读更多优质文章
作者:nxlhero
来源:https://blog.51cto.com/nxlhero/2515849
第一部分介绍生产上出现Dubbo服务拥堵的情况,以及Dubbo官方对于单个长连接的使用建议。
第二部分介绍Dubbo在特定配置下的通信过程,辅以代码。
第三部分介绍整个调用过程中与性能相关的一些参数。
第四部分通过调整连接数和TCP缓冲区观察Dubbo的性能。
一、背景
生产拥堵回顾
近期在一次生产发布过程中,因为突发的流量,出现了拥堵。系统的部署图如下,客户端通过Http协议访问到Dubbo的消费者,消费者通过Dubbo协议访问服务提供者。这是单个机房,8个消费者3个提供者,共两个机房对外服务。

在发布的过程中,摘掉一个机房,让另一个机房对外服务,然后摘掉的机房发布新版本,然后再互换,最终两个机房都以新版本对外服务。问题就出现单机房对外服务的时候,这时候单机房还是老版本应用。以前不知道晚上会有一个高峰,结果当晚的高峰和早上的高峰差不多了,单机房扛不住这么大的流量,出现了拥堵。这些流量的特点是并发比较高,个别交易返回报文较大,因为是一个产品列表页,点击后会发送多个交易到后台。
在问题发生时,因为不清楚状态,先切到另外一个机房,结果也拥堵了,最后整体回退,折腾了一段时间没有问题了。当时有一些现象:
(1)提供者的CPU内存等都不高,第一个机房的最高CPU 66%(8核虚拟机),第二个机房的最高CPU 40%(16核虚拟机)。消费者的最高CPU只有30%多(两个消费者结点位于同一台虚拟机上)
(2)在拥堵的时候,服务提供者的Dubbo业务线程池(下面会详细介绍这个线程池)并没满,最多到了300,最大值是500。但是把这个机房摘下后,也就是没有外部的流量了,线程池反而满了,而且好几分钟才把堆积的请求处理完。
(3)通过监控工具统计的每秒进入Dubbo业务线程池的请求数,在拥堵时,时而是0,时而特别大,在日间正常的时候,这个值不存在为0的时候。
事故原因猜测
当时其他指标没有检测到异常,也没有打Dump,我们通过分析这些现象以及我们的Dubbo配置,猜测是在网络上发生了拥堵,而影响拥堵的关键参数就是Dubbo协议的连接数,我们默认使用了单个连接,但是消费者数量较少,没能充分把网络资源利用起来。
默认的情况下,每个Dubbo消费者与Dubbo提供者建立一个长连接,Dubbo官方对此的建议是:
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
(http://dubbo.apache.org/zh-cn/docs/user/references/protocol/dubbo.html)
以下也是Dubbo官方提供的一些常见问题回答:
为什么要消费者比提供者个数多?
为什么不能传大包?
为什么采用异步单一长连接?
因为我们的消费者数量和提供者数量都不多,所以很可能是连接数不够,导致网络传输出现了瓶颈。以下我们通过详细分析Dubbo协议和一些实验来验证我们的猜测。
二、Dubbo通信流程详解
我们用的Dubbo版本比较老,是2.5.x的,它使用的netty版本是3.2.5,最新版的Dubbo在线程模型上有一些修改,我们以下的分析是以2.5.10为例。
以图和部分代码说明Dubbo协议的调用过程,代码只写了一些关键部分,使用的是netty3,dubbo线程池无队列,同步调用,以下代码包含了Dubbo和Netty的代码。Netty 在 Dubbo 中是如何应用的?推荐看下。
整个Dubbo一次调用过程如下:
1.请求入队
我们通过Dubbo调用一个rpc服务,调用线程其实是把这个请求封装后放入了一个队列里。这个队列是netty的一个队列,这个队列的定义如下,是一个Linked队列,不限长度。
class NioWorker implements Runnable {
...
private final Queue writeTaskQueue = new LinkedTransferQueue();
...
}
主线程经过一系列调用,最终通过NioClientSocketPipelineSink类里的方法把请求放入这个队列,放入队列的请求,包含了一个请求ID,这个ID很重要。
2.调用线程等待
入队后,netty会返回给调用线程一个Future,然后调用线程等待在Future上。这个Future是Dubbo定义的,名字叫DefaultFuture,主调用线程调用DefaultFuture.get(timeout),等待通知,所以我们看与Dubbo相关的ThreadDump,经常会看到线程停在这,这就是在等后台返回。
public class DubboInvoker extends AbstractInvoker {
...
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
...
return (Result) currentClient.request(inv, timeout).get(); //currentClient.request(inv, timeout)返回了一个DefaultFuture
}
...
}
我们可以看一下这个DefaultFuture的实现,
public class DefaultFuture implements ResponseFuture {
private static final Map CHANNELS = new ConcurrentHashMap();
private static final Map FUTURES = new ConcurrentHashMap();
// invoke id.
private final long id; //Dubbo请求的id,每个消费者都是一个从0开始的long类型
private final Channel channel;
private final Request request;
private final int timeout;
private final Lock lock = new ReentrantLock();
private final Condition done = lock.newCondition();
private final long start = System.currentTimeMillis();
private volatile long sent;
private volatile Response response;
private volatile ResponseCallback callback;
public DefaultFuture(Channel channel, Request request, int timeout) {
this.channel = channel;
this.request = request;
this.id = request.getId();
this.timeout = timeout > 0 ? timeout : channel.getUrl().getPositiveParameter(Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
// put into waiting map.
FUTURES.put(id, this); //等待时以id为key把Future放入全局的Future Map中,这样回复数据回来了可以根据id找到对应的Future通知主线程
CHANNELS.put(id, channel);
}
3.IO线程读取队列里的数据
这个工作是由netty的IO线程池完成的,也就是NioWorker,对应的类叫NioWorker。它会死循环的执行select,在select中,会一次性把队列中的写请求处理完,select的逻辑如下:
public void run() {
for (;;) {
....
SelectorUtil.select(selector);
proce***egisterTaskQueue();
processWriteTaskQueue(); //先处理队列里的写请求
processSelectedKeys(selector.selectedKeys()); //再处理select事件,读写都可能有
....
}
}
private void processWriteTaskQueue() throws IOException {
for (;;) {
final Runnable task = writeTaskQueue.poll();//这个队列就是调用线程把请求放进去的队列
if (task == null) {
break;
}
task.run(); //写数据
cleanUpCancelledKeys();
}
}
4.IO线程把数据写到Socket缓冲区
这一步很重要,跟我们遇到的性能问题相关,还是NioWorker,也就是上一步的task.run(),它的实现如下:
void writeFromTaskLoop(final NioSocketChannel ch) {
if (!ch.writeSuspended) { //这个地方很重要,如果writeSuspended了,那么就直接跳过这次写
write0(ch);
}
}
private void write0(NioSocketChannel channel) {
......
final int writeSpinCount = channel.getConfig().getWriteSpinCount(); //netty可配置的一个参数,默认是16
synchronized (channel.writeLock) {
channel.inWriteNowLoop = true;
for (;;) {
for (int i = writeSpinCount; i > 0; i --) { //每次最多尝试16次
localWrittenBytes = buf.transferTo(ch);
if (localWrittenBytes != 0) {
writtenBytes += localWrittenBytes;
break;
}
if (buf.finished()) {
break;
}
}
if (buf.finished()) {
// Successful write - proceed to the next message.
buf.release();
channel.currentWriteEvent = null;
channel.currentWriteBuffer = null;
evt = null;
buf = null;
future.setSuccess();
} else {
// Not written fully - perhaps the kernel buffer is full.
//重点在这,如果写16次还没写完,可能是内核缓冲区满了,writeSuspended被设置为true
addOpWrite = true;
channel.writeSuspended = true;
......
}
......
if (open) {
if (addOpWrite) {
setOpWrite(channel);
} else if (removeOpWrite) {
clearOpWrite(channel);
}
}
......
}
fireWriteComplete(channel, writtenBytes);
}
正常情况下,队列中的写请求要通过processWriteTaskQueue处理掉,但是这些写请求也同时注册到了selector上,如果processWriteTaskQueue写成功,就会删掉selector上的写请求。如果Socket的写缓冲区满了,对于NIO,会立刻返回,对于BIO,会一直等待。Netty使用的是NIO,它尝试16次后,还是不能写成功,它就把writeSuspended设置为true,这样接下来的所有写请求都会被跳过。那什么时候会再写呢?这时候就得靠selector了,它如果发现socket可写,就把这些数据写进去。
下面是processSelectedKeys里写的过程,因为它是发现socket可写才会写,所以直接把writeSuspended设为false。
void writeFromSelectorLoop(final SelectionKey k) {
NioSocketChannel ch = (NioSocketChannel) k.attachment();
ch.writeSuspended = false;
write0(ch);
}
5.数据从消费者的socket发送缓冲区传输到提供者的接收缓冲区
这个是操作系统和网卡实现的,应用层的write写成功了,并不代表对面能收到,当然tcp会通过重传能机制尽量保证对端收到。
6.服务端IO线程从缓冲区读取请求数据
这个是服务端的NIO线程实现的,在processSelectedKeys中。
public void run() {
for (;;) {
....
SelectorUtil.select(selector);
proce***egisterTaskQueue();
processWriteTaskQueue();
processSelectedKeys(selector.selectedKeys()); //再处理select事件,读写都可能有
....
}
}
private void processSelectedKeys(Set selectedKeys) throws IOException {
for (Iterator i = selectedKeys.iterator(); i.hasNext();) {
SelectionKey k = i.next();
i.remove();
try {
int readyOps = k.readyOps();
if ((readyOps & SelectionKey.OP_READ) != 0 || readyOps == 0) {
if (!read(k)) {
// Connection already closed - no need to handle write.
continue;
}
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
writeFromSelectorLoop(k);
}
} catch (CancelledKeyException e) {
close(k);
}
if (cleanUpCancelledKeys()) {
break; // break the loop to avoid ConcurrentModificationException
}
}
}
private boolean read(SelectionKey k) {
......
// Fire the event.
fireMessageReceived(channel, buffer); //读取完后,最终会调用这个函数,发送一个收到信息的事件
......
}
7.IO线程把请求交给Dubbo线程池
按配置不同,走的Handler不同,配置dispatch为all,走的handler如下。下面IO线程直接交给一个ExecutorService来处理这个请求,出现了熟悉的报错“Threadpool is exhausted",业务线程池满时,如果没有队列,就会报这个错。
public class AllChannelHandler extends WrappedChannelHandler {
......
public void received(Channel channel, Object message) throws RemotingException {
ExecutorService cexecutor = getExecutorService();
try {
cexecutor.execute(new ChannelEventRunnable(channel, handler, ChannelState.RECEIVED, message));
} catch (Throwable t) {
//TODO A temporary solution to the problem that the exception information can not be sent to the opposite end after the thread pool is full. Need a refactoring
//fix The thread pool is full, refuses to call, does not return, and causes the consumer to wait for time out
if(message instanceof Request && t instanceof RejectedExecutionException){
Request request = (Request)message;
if(request.isTwoWay()){
String msg = "Server side(" + url.getIp() + "," + url.getPort() + ") threadpool is exhausted ,detail msg:" + t.getMessage();
Response response = new Response(request.getId(), request.getVersion());
response.setStatus(Response.SERVER_THREADPOOL_EXHAUSTED_ERROR);
response.setErrorMessage(msg);
channel.send(response);
return;
}
}
throw new ExecutionException(message, channel, getClass() + " error when process received event .", t);
}
}
......
}
8.服务端Dubbo线程池处理完请求后,把返回报文放入队列
线程池会调起下面的函数
public class HeaderExchangeHandler implements ChannelHandlerDelegate {
......
Response handleRequest(ExchangeChannel channel, Request req) throws RemotingException {
Response res = new Response(req.getId(), req.getVersion());
......
// find handler by message class.
Object msg = req.getData();
try {
// handle data.
Object result = handler.reply(channel, msg); //真正的业务逻辑类
res.setStatus(Response.OK);
res.setResult(result);
} catch (Throwable e) {
res.setStatus(Response.SERVICE_ERROR);
res.setErrorMessage(StringUtils.toString(e));
}
return res;
}
public void received(Channel channel, Object message) throws RemotingException {
......
if (message instanceof Request) {
// handle request.
Request request = (Request) message;
if (request.isTwoWay()) {
Response response = handleRequest(exchangeChannel, request); //处理业务逻辑,得到一个Response
channel.send(response); //回写response
}
}
......
}
channel.send(response)最终调用了NioServerSocketPipelineSink里的方法把返回报文放入队列。
9.服务端IO线程从队列中取出数据
与流程3一样
10.服务端IO线程把回复数据写入Socket发送缓冲区
IO线程写数据的时候,写入到TCP缓冲区就算成功了。但是如果缓冲区满了,会写不进去。对于阻塞和非阻塞IO,返回结果不一样,阻塞IO会一直等,而非阻塞IO会立刻失败,让调用者选择策略。
Netty的策略是尝试最多写16次,如果不成功,则暂时停掉IO线程的写操作,等待连接可写时再写,writeSpinCount默认是16,可以通过参数调整。
for (int i = writeSpinCount; i > 0; i --) {
localWrittenBytes = buf.transferTo(ch);
if (localWrittenBytes != 0) {
writtenBytes += localWrittenBytes;
break;
}
if (buf.finished()) {
break;
}
}
if (buf.finished()) {
// Successful write - proceed to the next message.
buf.release();
channel.currentWriteEvent = null;
channel.currentWriteBuffer = null;
evt = null;
buf = null;
future.setSuccess();
} else {
// Not written fully - perhaps the kernel buffer is full.
addOpWrite = true;
channel.writeSuspended = true;
11.数据传输
数据在网络上传输主要取决于带宽和网络环境。
12.客户端IO线程把数据从缓冲区读出
这个过程跟流程6是一样的
13.IO线程把数据交给Dubbo业务线程池
这一步与流程7是一样的,这个线程池名字为DubboClientHandler。
14.业务线程池根据消息ID通知主线程
先通过HeaderExchangeHandler的received函数得知是Response,然后调用handleResponse,
public class HeaderExchangeHandler implements ChannelHandlerDelegate {
static void handleResponse(Channel channel, Response response) throws RemotingException {
if (response != null && !response.isHeartbeat()) {
DefaultFuture.received(channel, response);
}
}
public void received(Channel channel, Object message) throws RemotingException {
......
if (message instanceof Response) {
handleResponse(channel, (Response) message);
}
......
}
DefaultFuture根据ID获取Future,通知调用线程
public static void received(Channel channel, Response response) {
......
DefaultFuture future = FUTURES.remove(response.getId());
if (future != null) {
future.doReceived(response);
}
......
}
至此,主线程获取了返回数据,调用结束。关注公众号Java技术栈回复面试可以获取 Dubbo 系列面试题。
三、影响上述流程的关键参数
协议参数
我们在使用Dubbo时,需要在服务端配置协议,例如
"dubbo" port="20880" dispatcher="all" threadpool="fixed" threads="2000" />
下面是协议中与性能相关的一些参数,在我们的使用场景中,线程池选用了fixed,大小是500,队列为0,其他都是默认值。
| 属性 | 对应URL参数 | 类型 | 是否必填 | 缺省值 | 作用 | 描述 |
|---|---|---|---|---|---|---|
| name | string | 必填 | dubbo | 性能调优 | 协议名称 | |
| threadpool | threadpool | string | 可选 | fixed | 性能调优 | 线程池类型,可选:fixed/cached。 |
| threads | threads | int | 可选 | 200 | 性能调优 | 服务线程池大小(固定大小) |
| queues | queues | int | 可选 | 0 | 性能调优 | 线程池队列大小,当线程池满时,排队等待执行的队列大小,建议不要设置,当线程池满时应立即失败,重试其它服务提供机器,而不是排队,除非有特殊需求。 |
| iothreads | iothreads | int | 可选 | cpu个数+1 | 性能调优 | io线程池大小(固定大小) |
| accepts | accepts | int | 可选 | 0 | 性能调优 | 服务提供方最大可接受连接数,这个是整个服务端可以建的最大连接数,比如设置成2000,如果已经建立了2000个连接,新来的会被拒绝,是为了保护服务提供方。 |
| dispatcher | dispatcher | string | 可选 | dubbo协议缺省为all | 性能调优 | 协议的消息派发方式,用于指定线程模型,比如:dubbo协议的all, direct, message, execution, connection等。这个主要牵涉到IO线程池和业务线程池的分工问题,一般情况下,让业务线程池处理建立连接、心跳等,不会有太大影响。 |
| payload | payload | int | 可选 | 8388608(=8M) | 性能调优 | 请求及响应数据包大小限制,单位:字节。这个是单个报文允许的最大长度,Dubbo不适合报文很长的请求,所以加了限制。 |
| buffer | buffer | int | 可选 | 8192 | 性能调优 | 网络读写缓冲区大小。注意这个不是TCP缓冲区,这个是在读写网络报文时,应用层的Buffer。 |
| codec | codec | string | 可选 | dubbo | 性能调优 | 协议编码方式 |
| serialization | serialization | string | 可选 | dubbo协议缺省为hessian2,rmi协议缺省为java,http协议缺省为json | 性能调优 | 协议序列化方式,当协议支持多种序列化方式时使用,比如:dubbo协议的dubbo,hessian2,java,compactedjava,以及http协议的json等 |
| transporter | transporter | string | 可选 | dubbo协议缺省为netty | 性能调优 | 协议的服务端和客户端实现类型,比如:dubbo协议的mina,netty等,可以分拆为server和client配置 |
| server | server | string | 可选 | dubbo协议缺省为netty,http协议缺省为servlet | 性能调优 | 协议的服务器端实现类型,比如:dubbo协议的mina,netty等,http协议的jetty,servlet等 |
| client | client | string | 可选 | dubbo协议缺省为netty | 性能调优 | 协议的客户端实现类型,比如:dubbo协议的mina,netty等 |
| charset | charset | string | 可选 | UTF-8 | 性能调优 | 序列化编码 |
| heartbeat | heartbeat | int | 可选 | 0 | 性能调优 | 心跳间隔,对于长连接,当物理层断开时,比如拔网线,TCP的FIN消息来不及发送,对方收不到断开事件,此时需要心跳来帮助检查连接是否已断开 |
服务参数
针对每个Dubbo服务,都会有一个配置,全部的参数配置在这:http://dubbo.apache.org/zh-cn/docs/user/references/xml/dubbo-service.html。
我们关注几个与性能相关的。在我们的使用场景中,重试次数设置成了0,集群方式用的failfast,其他是默认值。
| 属性 | 对应URL参数 | 类型 | 是否必填 | 缺省值 | 作用 | 描述 | 兼容性 |
|---|---|---|---|---|---|---|---|
| delay | delay | int | 可选 | 0 | 性能调优 | 延迟注册服务时间(毫秒) ,设为-1时,表示延迟到Spring容器初始化完成时暴露服务 | 1.0.14以上版本 |
| timeout | timeout | int | 可选 | 1000 | 性能调优 | 远程服务调用超时时间(毫秒) | 2.0.0以上版本 |
| retries | retries | int | 可选 | 2 | 性能调优 | 远程服务调用重试次数,不包括第一次调用,不需要重试请设为0 | 2.0.0以上版本 |
| connections | connections | int | 可选 | 1 | 性能调优 | 对每个提供者的最大连接数,rmi、http、hessian等短连接协议表示限制连接数,dubbo等长连接协表示建立的长连接个数 | 2.0.0以上版本 |
| loadbalance | loadbalance | string | 可选 | random | 性能调优 | 负载均衡策略,可选值:random,roundrobin,leastactive,分别表示:随机,轮询,最少活跃调用 | 2.0.0以上版本 |
| async | async | boolean | 可选 | false | 性能调优 | 是否缺省异步执行,不可靠异步,只是忽略返回值,不阻塞执行线程 | 2.0.0以上版本 |
| weight | weight | int | 可选 | 性能调优 | 服务权重 | 2.0.5以上版本 | |
| executes | executes | int | 可选 | 0 | 性能调优 | 服务提供者每服务每方法最大可并行执行请求数 | 2.0.5以上版本 |
| proxy | proxy | string | 可选 | javassist | 性能调优 | 生成动态代理方式,可选:jdk/javassist | 2.0.5以上版本 |
| cluster | cluster | string | 可选 | failover | 性能调优 | 集群方式,可选:failover/failfast/failsafe/failback/forking | 2.0.5以上版本 |
这次拥堵的主要原因,应该就是服务的connections设置的太小,dubbo不提供全局的连接数配置,只能针对某一个交易做个性化的连接数配置。关注公众号Java技术栈可以获取 Dubbo 系列教程和面试题。
四、连接数与Socket缓冲区对性能影响的实验
通过简单的Dubbo服务,验证一下连接数与缓冲区大小对传输性能的影响。
我们可以通过修改系统参数,调节TCP缓冲区的大小。
在 /etc/sysctl.conf 修改如下内容, tcp_rmem是发送缓冲区,tcp_wmem是接收缓冲区,三个数值表示最小值,默认值和最大值,我们可以都设置成一样。
net.ipv4.tcp_rmem = 4096 873800 16777216
net.ipv4.tcp_wmem = 4096 873800 16777216
然后执行sysctl –p 使之生效。
服务端代码如下,接受一个报文,然后返回两倍的报文长度,随机sleep 0-300ms,所以均值应该是150ms。服务端每10s打印一次tps和响应时间,这里的tps是指完成函数调用的tps,而不涉及传输,响应时间也是这个函数的时间。
//服务端实现
public String sayHello(String name) {
counter.getAndIncrement();
long start = System.currentTimeMillis();
try {
Thread.sleep(rand.nextInt(300));
} catch (InterruptedException e) {
}
String result = "Hello " + name + name + ", response form provider: " + RpcContext.getContext().getLocalAddress();
long end = System.currentTimeMillis();
timer.getAndAdd(end-start);
return result;
}
客户端起N个线程,每个线程不停的调用Dubbo服务,每10s打印一次qps和响应时间,这个qps和响应时间是包含了网络传输时间的。
for(int i = 0; i < N; i ++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
while(true) {
Long start = System.currentTimeMillis();
String hello = service.sayHello(z);
Long end = System.currentTimeMillis();
totalTime.getAndAdd(end-start);
counter.getAndIncrement();
}
}});
threads[i].start();
}
通过ss -it命令可以看当前tcp socket的详细信息,包含待对端回复ack的数据Send-Q,最大窗口cwnd,rtt(round trip time)等。
(base) niuxinli@ubuntu:~$ ss -it
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 36 192.168.1.7:ssh 192.168.1.4:58931
cubic wscale:8,2 rto:236 rtt:33.837/8.625 ato:40 mss:1460 pmtu:1500 rcvmss:1460 advmss:1460 cwnd:10 bytes_acked:559805 bytes_received:54694 segs_out:2754 segs_in:2971 data_segs_out:2299 data_segs_in:1398 send 3.5Mbps pacing_rate 6.9Mbps delivery_rate 44.8Mbps busy:36820ms unacked:1 rcv_rtt:513649 rcv_space:16130 rcv_ssthresh:14924 minrtt:0.112
ESTAB 0 0 192.168.1.7:36666 192.168.1.7:2181
cubic wscale:7,7 rto:204 rtt:0.273/0.04 ato:40 mss:33344 pmtu:65535 rcvmss:536 advmss:65483 cwnd:10 bytes_acked:2781 bytes_received:3941 segs_out:332 segs_in:170 data_segs_out:165 data_segs_in:165 send 9771.1Mbps lastsnd:4960 lastrcv:4960 lastack:4960 pacing_rate 19497.6Mbps delivery_rate 7621.5Mbps app_limited busy:60ms rcv_space:65535 rcv_ssthresh:66607 minrtt:0.035
ESTAB 0 27474 192.168.1.7:20880 192.168.1.5:60760
cubic wscale:7,7 rto:204 rtt:1.277/0.239 ato:40 mss:1448 pmtu:1500 rcvmss:1448 advmss:1448 cwnd:625 ssthresh:20 bytes_acked:96432644704 bytes_received:49286576300 segs_out:68505947 segs_in:36666870 data_segs_out:67058676 data_segs_in:35833689 send 5669.5Mbps pacing_rate 6801.4Mbps delivery_rate 627.4Mbps app_limited busy:1340536ms rwnd_limited:400372ms(29.9%) sndbuf_limited:433724ms(32.4%) unacked:70 retrans:0/5 rcv_rtt:1.308 rcv_space:336692 rcv_ssthresh:2095692 notsent:6638 minrtt:0.097
通过netstat -nat也能查看当前tcp socket的一些信息,比如Recv-Q, Send-Q。
(base) niuxinli@ubuntu:~$ netstat -nat
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:20880 0.0.0.0:* LISTEN
tcp 0 36 192.168.1.7:22 192.168.1.4:58931 ESTABLISHED
tcp 0 0 192.168.1.7:36666 192.168.1.7:2181 ESTABLISHED
tcp 0 65160 192.168.1.7:20880 192.168.1.5:60760 ESTABLISHED
可以看以下Recv-Q和Send-Q的具体含义:
Recv-Q
Established: The count of bytes not copied by the user program connected to this socket.
Send-Q
Established: The count of bytes not acknowledged by the remote host.
Recv-Q是已经到了接受缓冲区,但是还没被应用代码读走的数据。Send-Q是已经到了发送缓冲区,但是对方还没有回复Ack的数据。这两种数据正常一般不会堆积,如果堆积了,可能就有问题了。
第一组实验:单连接,改变TCP缓冲区
结果:
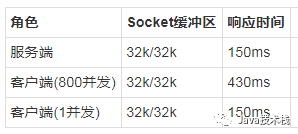
继续调大缓冲区
我们用netstat或者ss命令可以看到当前的socket情况,下面的第二列是Send-Q大小,是写入缓冲区还没有被对端确认的数据,发送缓冲区最大时64k左右,说明缓冲区不够用。

继续增大缓冲区,到4M,我们可以看到,响应时间进一步下降,但是还是在传输上浪费了不少时间,因为服务端应用层没有压力。
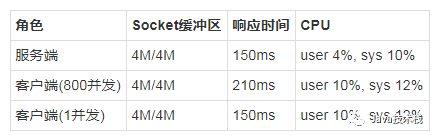
服务端和客户端的TCP情况如下,缓冲区都没有满
 客户端
客户端这个时候,再怎么调大TCP缓冲区,也是没用的,因为瓶颈不在这了,而在于连接数。因为在Dubbo中,一个连接会绑定到一个NioWorker线程上,读写都由这一个连接完成,传输的速度超过了单个线程的读写能力,所以我们看到在客户端,大量的数据挤压在接收缓冲区,没被读走,这样对端的传输速率也会慢下来。
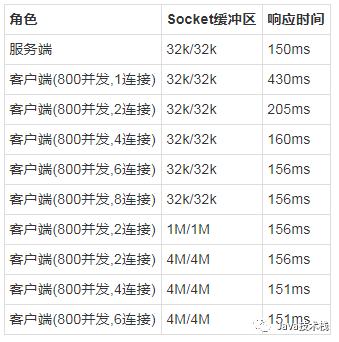
第二组实验:多连接,固定缓冲区
服务端的纯业务函数响应时间很稳定,在缓冲区较小的时候,调大连接数虽然能让时间降下来,但是并不能到最优,所以缓冲区不能设置太小,Linux一般默认是4M,在4M的时候,4个连接基本上已经能把响应时间降到最低了。
结论
要想充分利用网络带宽, 缓冲区不能太小,如果太小有可能一次传输的报文就大于了缓冲区,严重影响传输效率。但是太大了也没有用,还需要多个连接数才能够充分利用CPU资源,连接数起码要超过CPU核数。







关注Java技术栈看更多干货
