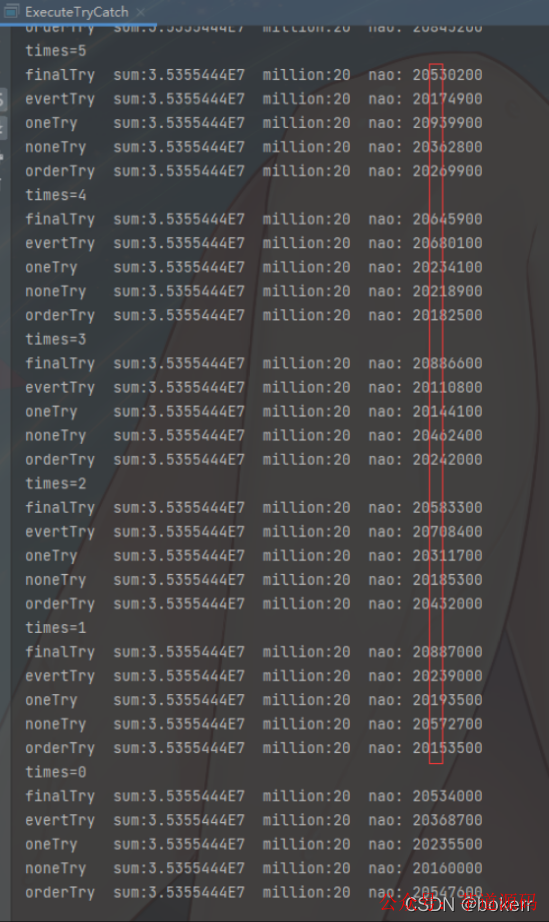
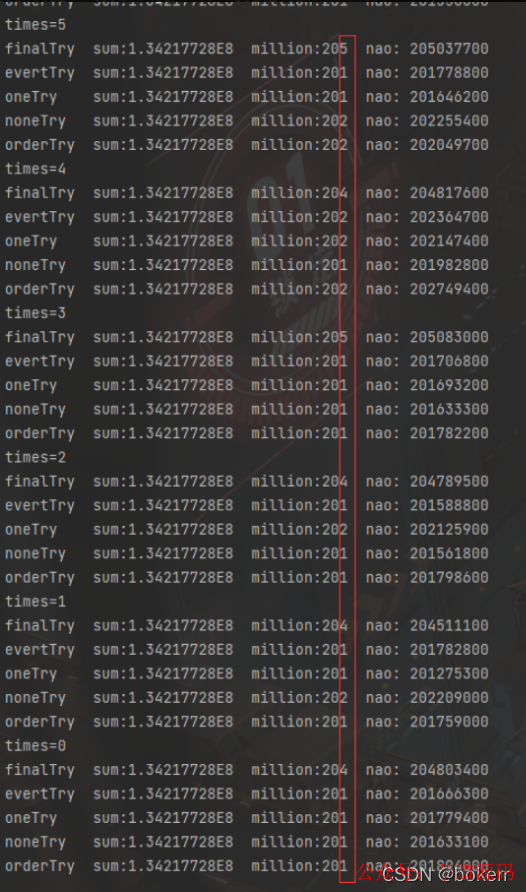
publicstaticvoidmain(String[] args){ int times = 50; ExecuteTryCatch executeTryCatch = new ExecuteTryCatch(); // 每个方法执行 50 次 while (--times >= 0){ System.out.println("times=".concat(String.valueOf(times))); executeTryCatch.executeMillionsEveryTryWithFinally(); executeTryCatch.executeMillionsEveryTry(); executeTryCatch.executeMillionsOneTry(); executeTryCatch.executeMillionsNoneTry(); executeTryCatch.executeMillionsTestReOrder(); } }
/** * 千万次浮点运算不使用 try catch * */ publicvoidexecuteMillionsNoneTry(){ float num = START_NUM; long start = System.nanoTime(); for (int i = 0; i < TIMES; ++i){ num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } long nao = System.nanoTime() - start; long million = nao / 1000000; System.out.println("noneTry sum:" + num + " million:" + million + " nao: " + nao); }
/** * 千万次浮点运算最外层使用 try catch * */ publicvoidexecuteMillionsOneTry(){ float num = START_NUM; long start = System.nanoTime(); try { for (int i = 0; i < TIMES; ++i){ num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } } catch (Exception e){
} long nao = System.nanoTime() - start; long million = nao / 1000000; System.out.println("oneTry sum:" + num + " million:" + million + " nao: " + nao); }
/** * 千万次浮点运算循环内使用 try catch * */ publicvoidexecuteMillionsEveryTry(){ float num = START_NUM; long start = System.nanoTime(); for (int i = 0; i < TIMES; ++i){ try { num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } catch (Exception e) {
} } long nao = System.nanoTime() - start; long million = nao / 1000000; System.out.println("evertTry sum:" + num + " million:" + million + " nao: " + nao); }
/** * 千万次浮点运算循环内使用 try catch,并使用 finally * */ publicvoidexecuteMillionsEveryTryWithFinally(){ float num = START_NUM; long start = System.nanoTime(); for (int i = 0; i < TIMES; ++i){ try { num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } catch (Exception e) {
} finally { num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } } long nao = System.nanoTime() - start; long million = nao / 1000000; System.out.println("finalTry sum:" + num + " million:" + million + " nao: " + nao); }
/** * 千万次浮点运算,循环内使用多个 try catch * */ publicvoidexecuteMillionsTestReOrder(){ float num = START_NUM; long start = System.nanoTime(); for (int i = 0; i < TIMES; ++i){ try { num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; } catch (Exception e) { }
try { num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } catch (Exception e){}
try { num = num + STEP_NUM + 1f; num = num + STEP_NUM + 2f; } catch (Exception e) { } try {
num = num + STEP_NUM + 3f; num = num + STEP_NUM + 4f; num = num + STEP_NUM + 5f; } catch (Exception e) {} } long nao = System.nanoTime() - start; long million = nao / 1000000; System.out.println("orderTry sum:" + num + " million:" + million + " nao: " + nao); }



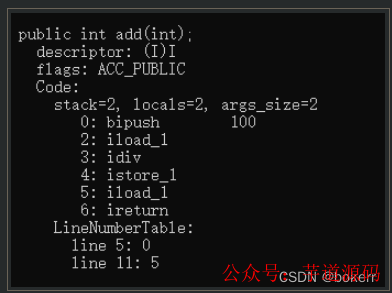
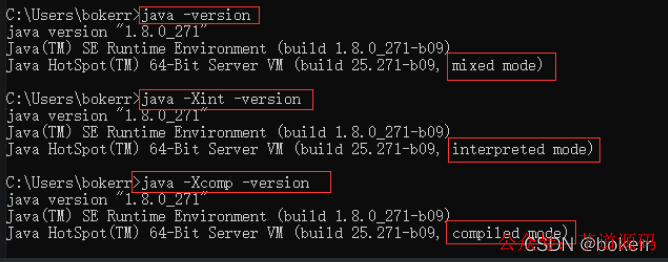
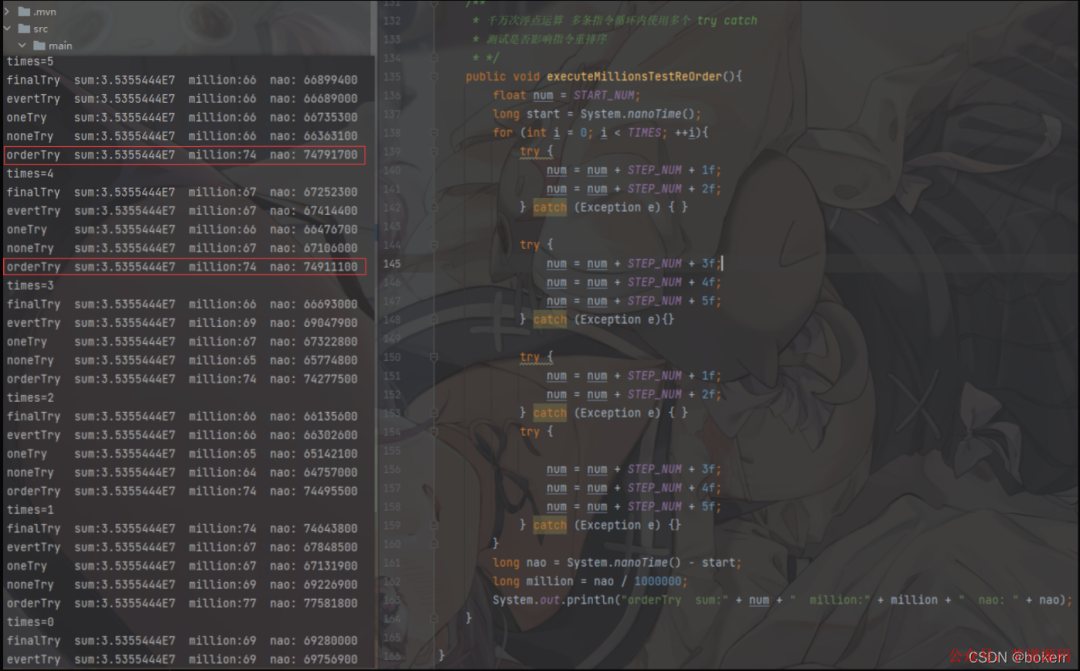 结合测试代码发现,即使百万次循环计算,每个循环内都使用了
结合测试代码发现,即使百万次循环计算,每个循环内都使用了