
一站式大数据解决方案分析与设计实践:BI无缝整合Apache Kylin


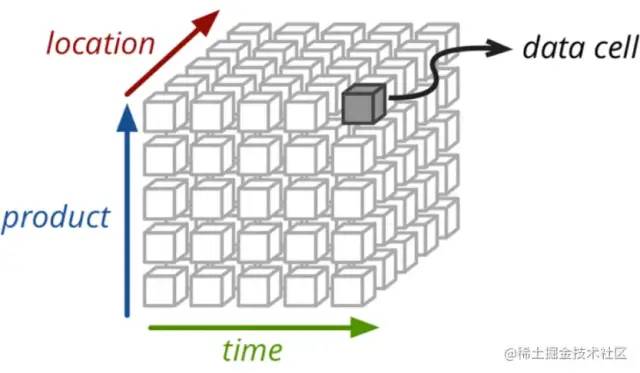


研发目标

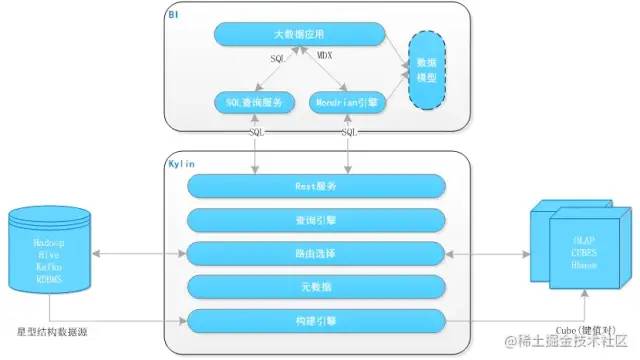
设计架构

附注1
Mondrian为一个OLAP引擎,而且是一个ROLAP引擎,实现了以下规范:
MDX(多维查询语言,相当于数据库的SQL)
XMLA(通过SOAP使用OLAP)
olap4j(Java API规范,相当于JDBC关系数据库)
附注1:
数据应用,包括智能报告、支持生成SQL或多维分析查询MDX语句组件、托拉拽自助式分析可视化组件等
Mondrian Schema,数据多维分析模型
Mondrian引擎,根据Schema生成标准SQL
目标数据源,包括关系型数据源、非关系型数据源、企业数据仓库
功能架构设计

附注1:
存储引擎,Kylin默认使用分布式、面向列的开源数据库Hbase作为存储库引擎,基于Apache Kylin插件架构实现数据库存储接入。
Presto,分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
用户/权限
数据模型
CUBE配置

Cube功能改造:
页面,布局、样式统一、中文显示
用户权限,统一安全认证
Cube管理查询
构建引擎,计算引擎默认选择Flink作为构建引擎
Cube运行监控
Apache Kylin通过日志和报警对任务进行监控、了解整体的运行情况,Kylin支持显示每个构建任务的进度条和构建状态,并可以展开明细,列出任务的每一步详细信息,数据模型下总Cube数,及空间占用。

状态 禁用(Disabled) 只有定义,没有构建数据 错误(ERROR) 报错并停止后续执行 准备(Ready) 构建完成可以提供查询服务。 执行控制 恢复(Resume) 在上次错误位置恢复执行 放弃(Discard) 如要修改Cube或重新开始构建,可以放弃此次构建。 构建(Build) 全量构建,增量构建采用 刷新(Refresh) 对相应分区(Segment)历史数据进行重建 合并(Merge) 合分区(Segment),提高查询性能
数据查询
Cube构建好以后,状态变为“READY”,就可以进行查询,查询语言为标准SQL SELECT语句。
只有当查询的模式跟Cube定义相匹配的时候,Kylin才能够使用Cube的数据来完成查询,“Group by”的列和“Where”条件里的列,必须是维度中定义的列,而SQL中的度量应跟Cube中定的义的度量一致。


存储引擎

推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
评论