
MSRA读博五年|自己主导的第一篇SOSP

新智元报道
新智元报道
作者:李博杰
【新智元导读】长文预警:《MSRA 读博五年》系列之二,约13000字,未完待续……
发表在 SOSP 2017 上的 KV-Direct 是我的第二篇(第一作者)论文。因为第一篇 SIGCOMM 论文 ClickNP 是谭博手把手带我做的,KV-Direct 也是我自己主导的第一篇论文。
SIGCOMM 之后做什么
SIGCOMM 论文投稿之后,谭博说,下一个项目我需要自己去想方向。
做编译器还是做应用?
我们深知 ClickNP 还有很多问题,目前支持的编译优化过于简单,希望从编程语言的角度提升编译器的可靠性。与此同时,我们把 ClickNP 作为组内网络研究的一个公共平台,孵化更多的研究创意。
我自然就沿着两个方向去探索,一个是扩展 ClickNP 来让它更容易编程、更高效;另一个是利用 ClickNP 这个平台来开发新型的网络功能,去加速网络里的各种中间件。那时,我们在并行探索很多中间件,例如加密解密、机器学习、消息队列、七层(HTTP)负载均衡器、键-值存储,这些都可以用 FPGA 来加速。
为了提高 ClickNP 的可编程性,我开始从学校里物色好的苗子加入 MSRA 实习。李弈帅在本科期间,就对编程语言和形式化方法很感兴趣。他是我推荐来到 MSRA 实习的第一位学生。春季学期开始,李弈帅就来 MSRA 开始实习,也恰好完成他的本科毕业设计。他为 ClickNP 系统提出了几个关键的优化,新增了一些简化编程的语法,修正了一些蹩脚的语法。
但是,由于工作量的原因,我们并没有对编译框架做大的重构,仍然在使用简单的语法制导翻译,没有使用 clang 这种专业的编译器框架,也没有中间语言。因此,每次新增编译优化的时候都显得比较 ad-hoc。
由于 OpenCL 经常遇到奇奇怪怪的问题,我就萌生了自己做一个高层次综合(HLS)工具的想法,从 OpenCL 直接生成 Verilog。我的想法很简单,对于网络领域的应用场景,我们所做的就是把一段 C 代码中的循环全部展开,变成了一大块组合逻辑,只要在合适的位置插入寄存器,就能变成一条吞吐量极高、每个时钟周期都能处理一次输入的流水线。如果代码中有访问全局状态,那么这种循环依赖就决定了依赖路径上寄存器的最大数量,也就是时钟频率的上限。
但是谭博并不同意我自己做 HLS 工具的想法,因为我们并不是专业的 FPGA 研究者,这样的工作创新性不足,更多是在填补现有 HLS 工具的 「坑」,是一个工程问题,不管在 FPGA 还是网络领域都难以发表顶级论文。
由于 FPGA 卡的烧写经常出现问题,我就天天到机房里面插拔 FPGA 卡,有时候直接在机房里面就地调试。因此,我就又像本科在少院机房的时候一样,经常吹着冷风,忍着 80 多分贝的噪音,在机房里面一泡一两个小时。
 我和 MSRA 网络组的服务器,是 MSRA 写宣传稿的时候给我拍的,我经常用这张照片
我和 MSRA 网络组的服务器,是 MSRA 写宣传稿的时候给我拍的,我经常用这张照片HTTPS 加速器的故事
FPGA 除了适合用来处理网络报文,还很适合用来做计算。在网络领域什么场景需要的计算多呢?那自然是加密和压缩了。产品部门已经做了压缩,我们自然就选择了加密。
崔天一是我在科大 LUG 认识的技术大牛,跟我一样也是曾经的少院学生会技术部部长,大二担任 LUG 的 CFO,大三担任 LUG 会长。大二下学期,他对 MSRA 很感兴趣,我就推荐他来做暑期实习。在这两个月的实习期内,崔天一与我一起做基于 FPGA 的 HTTPS 加速器。
 谭博和MSRA的学生们,左起:陆元伟、崔天一、谭焜、李博杰、Jeongseok Son(孙正锡)
谭博和MSRA的学生们,左起:陆元伟、崔天一、谭焜、李博杰、Jeongseok Son(孙正锡)理论上说,如果 FPGA 的面积无限大,AES、RSA 之类的加密算法都很容易实现。这些算法的循环次数都是固定的,只要完全循环展开,理论上就能每个时钟周期处理一个报文分片(flit)。
但是这样的流水线需要的芯片面积大到无法接受,因为循环次数太多了。AES 一个块的加密流水线有十几次 S 盒的翻转,这块数字逻辑大概占到 FPGA 总面积的 20%~30%。因为我们所用的 FPGA 上有 40% 的空间需要留给 Hard IP 和网络、PCIe 报文处理的基础框架,可用于业务逻辑的空间只有不到 60%,此时用将近一半的空间做 AES 就显得太多了。
RSA 的复杂度则完全是另一个数量级了。RSA-2048 需要 2048 次模乘和加法,每次模乘又是 2048 位乘 2048 位,即使在 CPU 上执行,一次 RSA-2048 也需要 800 万次乘法。如果把所有循环展开成一条流水线,数字逻辑的规模将是 FPGA 面积的上万倍。
除了芯片面积的问题,逻辑依赖也是要考虑的另一个因素。例如,在 AES 加密算法中,如果采用有些加密模式(例如 CBC 模式),报文的各个分片之间是有依赖关系的,第二个分片的计算输入依赖第一个分片的计算输出,这样整条流水线就 「流不起来」,单条网络连接的吞吐量还是上不去。因此,就需要多条网络连接并行处理才能占满 FPGA 流水线的处理能力,这就要求我们记录每条连接的中间处理状态。
基于 FPGA 实现 HTTPS 加速器的挑战,主要就是如何把这些巨大的数字逻辑拆分成可以复用的小块,并且保存计算过程中的中间状态。
当时崔天一和我就整天在研究蒙哥马利模乘(Montgomery Modular Multiplication),把 2048 乘 2048 位的计算拆成 256 位乘 256 位的小块。实现 2048 位的减法也是颇费功夫的,直接在 OpenCL 里面写一个 2048 位的减法,性能直接就 「爆炸」 了,是需要拆分的。由于 OpenCL 不便于控制生成的 Verilog 代码,对于核心的计算模块,我们就利用了 ClickNP 的 Verilog 模块(element)功能,用 Verilog 直接编写。
最终,HTTPS 加速器的原型可以实现每秒 12000 次 RSA-2048 加密或者加密操作,这相当于 20 个 CPU 核全速并行工作的性能。对于 AES 这种对称加密,也可以达到 100 Gbps 以上的吞吐量(但由于以太网 Hard IP 的带宽限制只能达到 40 Gbps)。
崔天一和我用 VideoScribe 制作了一个演示视频,在微软 Hackathon 2016 上演示了 HTTPS 加速器项目,并从全球数千个 Hackathon 项目中脱颖而出,获得了云与企业组(Cloud and Enterprise Category)的全球第二名,为天一为期两个月的暑期实习画上了一个圆满的句号。
HTTPS 加速器虽然解决了不少工程问题,但我们感觉它学术上的创新不足以发表顶级论文。一年后,崔天一又回到了 MSRA 我们组实习,和我一起完成了我的第三个研究工作,这就是后面的故事了。
机器学习加速器的探索
AI 一直是微软研究院的战略方向之一,整个 Catapult FPGA 团队在探索 Bing 搜索和数据中心网络之后,也在探索 FPGA 如何用在 AI 上。学术界将 FPGA 用于 AI 训练和推理的文章已经连篇累牍,因此我们考虑的重点是如何利用高速网络来加速 FPGA AI。
FPGA 做 AI 推理当时有一个很大的局限,就是内存的带宽。当时我们的 FPGA 还没有 HBM 这么高速的内存,只有 DDR4 内存,带宽有限。AI 推理中,模型的大小是明显超过 FPGA 内部的片上高速缓存(SRAM)容量的,因此 AI 推理的过程需要在片上高速缓存与 DDR 内存之间反复换入换出,性能低下。
我想到,能否利用多块 FPGA 组成的集群,把深度神经网络模型拆分成若干块,使得每一块都能放进 FPGA 内部的高速缓存?这样,需要通过网络传递的就是各块之间的中间结果,但经过计算,对于我们使用的模型,传输这些中间结果所需的带宽并不会成为瓶颈。
我兴奋地把这个发现报告给我们硬件研究组的主管徐宁仪老师,他说,我想到的方法叫做 「模型并行」。在一些场景下,这种 「模型并行」 的方法确实相比传统的 「数据并行」 方法能取得更高的性能。尽管这并不算是一个理论创新,但徐宁仪老师说,把整个模型都放进 FPGA 内部的高速缓存这个想法是有点意思的。这就像是把很多块 FPGA 利用高速网络互联,当成了一块 FPGA 来用。
一般我们都说,多台机器组成的集群难以实现线性加速比,也就是说机器多了,通信和协同的代价高了,平均每台机器的产出就少了。但这种 「模型并行」 的方法在 FPGA 数量足够多到能够在片上容纳下整个模型时,可以实现 「超线性」 加速比,也就是其中每个 FPGA 的平均产出相比单个使用数据并行方法的 FPGA 更高。
解决了访问模型的内存带宽问题,FPGA 的算力就可以充分释放出来。我们做了一个思想实验:微软 Azure 数据中心每台服务器都部署了一块 FPGA,最初只是用来加速网络虚拟化。如果把整个数据中心的 10 万块 FPGA 的算力都像一台计算机一样集中调度起来,只需要不到 0.1 秒,就可以翻译完成整个维基百科。它也在微软的一场官方发布会上作为一个业务场景做了演示。
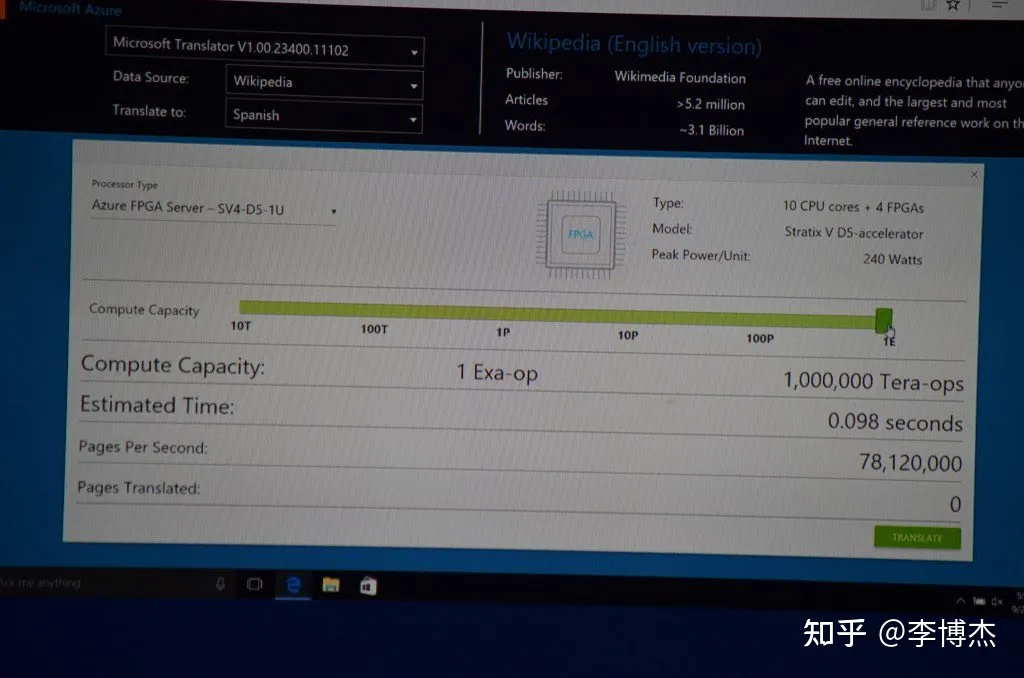 微软用 FPGA 加速机器翻译的 demo,如果把整个数据中心 1 Exa Ops 的算力都用起来,只需要不到 0.1 秒就可以翻译完整个维基百科
微软用 FPGA 加速机器翻译的 demo,如果把整个数据中心 1 Exa Ops 的算力都用起来,只需要不到 0.1 秒就可以翻译完整个维基百科KV-Direct:我的第二篇论文
我的第二篇论文 KV-Direct 是跟阮震元作为共同第一作者,他也是我从科大推荐到 MSRA 实习的大神,跟崔天一几乎是同时入职的。因为阮神是大三暑假加入的,他在 MSRA 的实习期长达一年,直到毕业。
用 FPGA 加速键-值存储
键-值存储(Key-Value Store)是系统领域一个很典型的中间件,简单来说就是 C++ 里面的 unordered_map 或者 Python 里面的 dict,但是它并不在本地内存里,而是在分布式系统里的其他主机上,需要通过网络来访问。Memcached、Redis 都是典型的键值存储,但它们的性能相比本地的 unordered_map 却慢了几十倍甚至上百倍。其根本原因就在厚重的软件网络协议栈里,网络通信的开销远远大于访问内存中的一个值。我们就想,如果使用 FPGA 做一个键-值存储,在 FPGA 上用 ClickNP 做一个极简的通信协议栈,它的性能一定很好。
后来,我才知道系统领域有一篇经典文章《Scalability! but at what COST?》,是三位本来在微软硅谷研究院,后来被集体裁员的的大佬合著的。它讲的就是系统研究领域的一些分布式系统号称可扩放性(scalability)很好,但上百个 CPU 核的性能还不如单个 CPU 核上自己写的单线程程序。
清华的陈文光教授也发现了这个现象,他说,早年他做 HPC 领域的研究,性能提升 1% 都很不容易。后来发现图计算的这些系统性能实在太差了,一优化就是几十上百倍的性能提升。
键-值存储领域也是如此,Redis、Memcached 这些工业界常用的系统主要性能瓶颈都不在访问键值上,而是在厚重的内核网络协议栈里。学术界大佬们的嗅觉是敏锐的,他们已经沿着两条路做了优化。一条路是用 RDMA 取代 TCP/IP,另一条路是用 DPDK 等高性能报文处理框架。在 RDMA 这条路上,学术界还探索了使用纯双边语义、单边和双边结合的语义等多种方案。
用 FPGA 来实现键-值存储,性能肯定高,但有什么学术上的挑战和贡献呢?有了 ClickNP 编译器改进、HTTPS 加速器、机器学习推理加速等三个项目的经验,我认识到,要想发表顶级论文,问题重要、性能好是不够的,还要足够有挑战,解决的方法足够创新,不能太 straight-forward。
华为一位资深规划大师说,公司项目的立项都是三段论:问题很严重,技术很牛逼,效果很显著。这个逻辑对学术研究也是适用的。
一开始,我想到学术界现有的高性能键值存储一般只支持 Memcached 这样的 get/put,不支持 Redis 的 list、map 等高级语义,就想着把语义更丰富作为一个卖点。谭博说,这样太工程了,可能吃力不讨好。
谭博说,我需要逐渐培养自己的 research taste。每个研究者都有自己独特的 research taste,就是如何认知和评价已有的研究工作和未来的研究方向。例如,有些人比较喜欢偏理论的研究,有些人喜欢偏系统的研究。随着研究的深入,也需要逐步了解其他主要研究者的 research taste,这样就可以投稿到更合适的会议,并根据潜在审稿人的 research taste 来修改论文。
送别谭博
2016 年 9 月 22 日,星期四,谭博突然跟我们实习生说,明天就是他在微软的最后一天了。我倒是没有感觉很意外,因为之前就有人透露了谭博可能要去华为的风声,但是我并不清楚具体时间,只是感觉太快了,太突然了。
下午,谭博在茶水间跟我聊天,问我以后准备做什么方向,编程语言还是系统。我想了一下,还是做系统吧。谭博赞同我的选择,说 MSRA 在编程语言方面没有积累,在系统方面有比较多的积累,后面做 networked systems(网络系统)是个不错的方向。这段在茶水间两三分钟的聊天,就决定了我博士的道路。随后,谭博就把我介绍给了张霖涛导师,系统组的首席研究员。谭博在普林斯顿访学时,霖涛导师正在普林斯顿读博士,他们就成为了好友。
周五,我们几个实习生帮谭博收拾行李,其中光专利石就好几十块,像元素周期表一样码了满满一面墙,搬了好几趟才搬完。专利石是微软给专利申请人的一个纪念,是一块正方体形状大约一公斤的岩石,上面刻着专利的名字、申请人和申请时间。(想看图的可以搜索 「Microsoft patent cube」)
谭博给我们交接工作的细节我已经不记得了,只记得他教诲我们的两点:
1. 研究在于去伪存真,在于追求真理。这也是谭博此前经常给我们讲的。已发表的论文不一定就是真理,我们需要分析型思考(analytical thinking)。
2. 研究不在数量多,关键要有代表作。聊起一个研究者,大家最先想起来的就是他的几个代表作。
 谭博和我在 MSRA 留影
谭博和我在 MSRA 留影 谭博的学生们在 MSRA 留影,左起:阮震元、李博杰、孟梦、陆元伟、裴昶华
谭博的学生们在 MSRA 留影,左起:阮震元、李博杰、孟梦、陆元伟、裴昶华这中间还有个小插曲。周四晚上,我妈给我打电话,让我赶紧回家,第二天准备用我的名字买一套房子。我瞬间懵了,我父母之前从来没有跟我说过这事呀。原来,那段时间刚好是石家庄房价暴涨,他们也耐不住性子了,也想搭上这趟快车。我说,我也有个重要的事情,谭博要走了,明天我们还要交接工作,不方便请假呀。
于是,周六一大早,我就回到石家庄去,我爸开着车载着我、我妈和我奶奶,手里还拎着几十万现金,在各个楼盘之间转悠。我爸想买个别墅,但家庭的财力不允许,就得背上沉重的负债。周日,他们还是决定买个普通的平层,一下午就把购房合同和贷款都办好了。晚上,我就回到了北京,一点没耽误工作。
人自己就不可以预料,一个人的命运,当然要靠自我奋斗,但是也要考虑到历史的进程。我绝对不知道北京后来的限购政策,认房又认贷,认的还是全国的贷。就是这套房子让我在北京买房的时候变成了二套,需要付的首付从 40% 变成了 80%,一下子压力大了很多。更麻烦的是,这套房子后来虽然按期交房了,但房产证一直办不下来,导致我在北京买房时想把它卖掉都不行,变成了无法交易的固定资产。
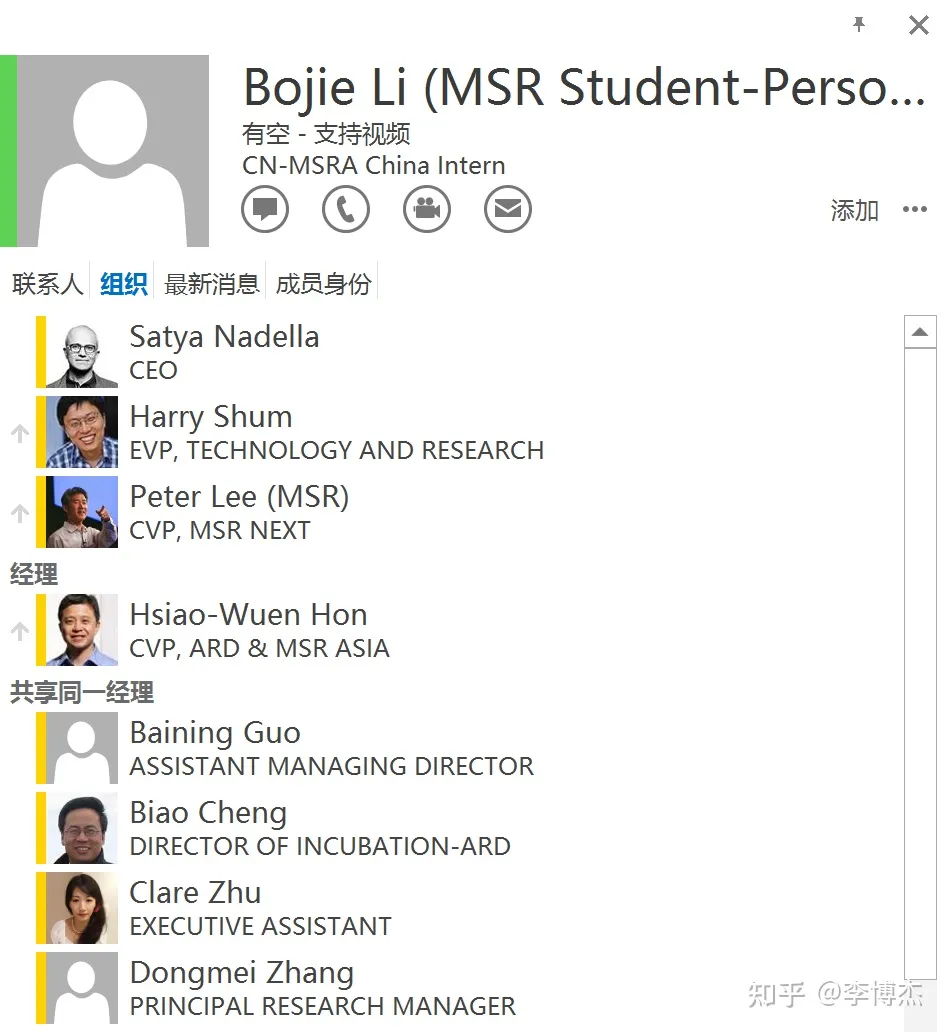 谭博走后,我作为他的下属,在组织树中临时 「升了一级」,挂在了洪院长名下,这是我在组织树上距离 CEO 最近的时刻
谭博走后,我作为他的下属,在组织树中临时 「升了一级」,挂在了洪院长名下,这是我在组织树上距离 CEO 最近的时刻MSRA 的 「饭团」
在 MSRA,我们实习生们经常聚在一起吃饭。微软北京当时有 4 个餐厅,一号楼三楼是有好几条餐线的食堂,二楼是点菜的 「云+端」(Cloud + Client)中餐厅和(忘了什么名字的)西餐厅,二号楼三楼还有一个自助餐厅。因为西餐厅和自助餐厅比较贵,我们一般中午是在食堂吃饭,晚上在 「云+端」 中餐厅一起聚餐,那个点菜的餐厅人均下来也不贵。
 MSRA 饭团游蟒山,后排左起:陆元伟(球王)、Taekyung Heo、杨泽、肖文聪(聪老师)、王韵、Xiaoyi Chen,前排左起:李博杰、曹士杰、张茹、韩震华
MSRA 饭团游蟒山,后排左起:陆元伟(球王)、Taekyung Heo、杨泽、肖文聪(聪老师)、王韵、Xiaoyi Chen,前排左起:李博杰、曹士杰、张茹、韩震华我们饭团经常一起出去玩,比如聚餐(过生日)、爬山、唱 K、滑雪等等。最早的时候饭团里主要是联合培养的博士生,后来一些相对短期的实习生也加入进来,一桌盛不下了,就逐渐分裂成了各个楼层的饭团,比如我们就在 12 楼的饭团里。其他楼层的饭团还凑成过几对。
 MSRA 饭团在 MSRA 的 logo 前合影
MSRA 饭团在 MSRA 的 logo 前合影 MSRA 饭团在微软 2 号楼下的微软 logo 前合影
MSRA 饭团在微软 2 号楼下的微软 logo 前合影 MSRA 饭团在 MSRA 的 sky garden 合影
MSRA 饭团在 MSRA 的 sky garden 合影 MSRA 饭团在 MSRA 的 logo 前合影
MSRA 饭团在 MSRA 的 logo 前合影
讲通 KV-Direct 的故事
暑假期间,阮震元和我就基于 ClickNP 实现了键值存储的基本功能。我们意识到,FPGA 上的 DDR 容量有限,如果数据都放在 FPGA 板上的 DDR 中,那么键值存储的容量将只有 4 GB 或 8 GB(取决于我们两种不同版本的 FPGA 板子)。而主机上的 DDR 空间高达 256 GB。因此我们就希望把数据放在主机内存中,FPGA 从网络上接收键值操作,通过 PCIe 来访问主机内存,再通过网络回复结果。
这样一来,就有了好几个挑战。首先是 PCIe 带宽有限。网卡的 PCIe 带宽一般是设计得稍大于网络带宽的,例如我们的 FPGA,PCIe 是 2 个 Gen3 x8,由于板子的工程原因只能使用一个 Gen3 x8,也就是理论带宽只有 64 Gbps;网络带宽则是 40 Gbps。也就是说,如果一个键值操作使用的 PCIe 带宽是它本身大小的 2 倍以上,那么网络带宽就是打不满的,PCIe 将成为瓶颈。更重要的是,PCIe 小报文的性能很差,在优化前,一个 Gen3 x8 只能做到 30 M op/s 左右,这样的性能相比学术界最好的系统相差甚远,无论是基于 RDMA 的还是基于 DPDK 的。
为此,我们决定先优化 PCIe 的小报文性能。既然 Mellanox 网卡能做到,为什么我们的 FPGA 就不能做到?这是因为我们的 FPGA 平台主要把 PCIe 作为控制面,并不打算用 PCIe 传输大量数据,因此并没有为 PCIe 小报文性能优化。看来,只能我们自己动手,去啃 PCIe 的 spec,优化 FPGA 平台上负责 PCIe 处理的 Verilog 代码了(PCIe 事务层是用 Verilog 实现的,链路层和物理层是在 Hard IP 中实现的)。
最关键的优化是流水线化 TLP 的处理过程。原来每处理一个 PCIe 报文(TLP)需要至少 5 个时钟周期,来走完处理的各个阶段。处理完成上一个 TLP 之前,下一个 TLP 不能开始处理。我们把整个处理过程流水线化,使得处理一个 PCIe TLP 报文的关键路径只需 2 个时钟周期,这样在 200 MHz 的时钟频率下,理论上就能达到 100 M op/s 的吞吐量。另外一个优化是增加并发 DMA 请求的支持能力,这比较简单,增加等待 FIFO 的深度,并且配置 Hard IP 的参数就行了。为了让 ClickNP 中的代码能够直接访问主机内存,我们为 ClickNP 增加了 PCIe 通道,可以通过发送读写命令的方式,直接转换成 PCIe TLP 来访问主机内存。
这些工作有数千行 Verilog 代码,但因为听起来比较工程化,在 KV-Direct 论文中根本没有呈现。我们为此付出了几个人月的开发和调试工作。我们在把 Verilog 代码优化到极致后,PCIe 小报文性能上去了一些,但还是达不到预期,最后我们发现了性能瓶颈的根源,总结在了 KV-Direct 论文的 2.4 节和 Figure 3 中。首先,PCIe 有流控机制,可能是由于 Hard IP 的原因,FPGA 的 PCIe 响应时延比较高,导致触发流控机制限流,并发度不足。其次,对于 PCIe read,我们 FPGA 的 Hard IP 只支持 64 个 tag(并发请求的标记),导致并发度进一步被限制到了 64。因此,通过 PCIe 做小数据读写的吞吐量分别只有大约 60 M op/s 和 80 M op/s。系统研究中总是有很多这类搭平台的基础性工作,本身没有什么科研上的创新性,但又是做出有价值研究工作必不可少的准备。
认识到 PCIe 带宽有限、小报文性能较差这一点,减少 PCIe 读写操作的数量就显得尤为重要。这跟通过 RDMA 单边操作来访问远端内存的键-值存储系统所面临的挑战是比较类似的。阮震元是一个特别聪明的师弟,跟他说一个 idea,很快就能 get 到;给他提一个难题,经常能想到巧妙的解法。他讲话速度跟我一样,特别快,有时候我们不能 get 到他的意思,他就暗戳戳地嘲笑我们不太聪明。
为了减少 PCIe 读写操作的数量,首先,阮震元和我设计了一套精巧的哈希表和内存分配器来尽量减少 PCIe 读写操作的数量,实现大多数情况下内联键值的读操作仅需 1 次 PCIe 读操作,写操作仅需 1 次 PCIe 读操作和 1 次 PCIe 写操作。特别重要的是,即使在内存利用率较高时,仍然能够达到较低的平均 PCIe 读写操作数量。
其次,我们想到了之前因为容量较小而被 「抛弃」 的 DDR,想把 DDR 用来辅助主机内存。但这并不是一件容易的事情,因为 DDR 的带宽跟 PCIe 在同一个数量级上,而 DDR 的容量远小于主机内存。如果把 DDR 当作主机内存的缓存,那么系统性能不但不会提升,反而可能有所下降,因为查询缓存的代价太高了。如果只是把 DDR 作为主机内存的容量扩展,那么因为 DDR 的容量太小了,它能够分担的工作量太少,主机内存仍然是吞吐量瓶颈,DDR 增加的处理能力只是杯水车薪。阮震元跟我苦思冥想了很久,终于设计出一套缓存和负载均衡相结合的思路,把 DDR 作为主机内存一部分区域的缓存,从而把 DDR 的带宽用起来。
第二个挑战是 PCIe 延迟较高。在我们的 FPGA 平台上,通过 PCIe 读取主机内存大约需要 1 us 的时延,这是比理论时延高不少的,但这可能是 Hard IP 的原因,我们也无能为力。在这 1 us 的时间中,会到达数十个甚至上百个键值操作请求。其中有些键值操作可能是有依赖关系的,例如先写入一个值,再读取一个值,这就要求读取到的是写入后的新值。为了避免阻塞流水线,我们设计了一个乱序执行引擎来解决这种有数据依赖的情况。
KV-Direct 的合作者们:霖涛导师、阮神、球王和聪老师
系统组里,陆元伟(球王)和肖文聪(聪老师)是我的好友,也是系统组为数不多的联合培养学生。球王和我的导师原来都是谭博,谭博走后,球王的导师是熊勇强老师,我的导师是张霖涛老师。聪老师的导师是时任系统组主任的周礼栋老师,现在已经是 MSRA 的院长了。加上我的师弟阮震元,我们四位学生一起合作 KV-Direct 这篇论文。
在 KV-Direct 项目中,代码大部分是阮震元开发的,很多关键的设计也是阮震元提出的,因此我把他列为共同第一作者。阮神作为一位大四学生,能够有这么强的科研能力,是让我挺吃惊的。他毕业后来到 UCLA 师从 FPGA 大师 Jason Cong(丛京生)读了硕士,后来又到 MIT 跟着 Frans Kaashoek 读博,目前已经在 OSDI、NSDI 等顶会上发表了超过 5 篇 paper,确实非常厉害。
在 MSRA,优秀的人往往会吸引更优秀的人。郭沫若奖学金是中科大的最高奖学金,全校每年只评选 15 名本科生,而跟着我实习的科大同学出了 5 位郭沫若奖得主。我自己的成绩则很差,GPA 只有 3.3,排名只是中等偏上。跟着我实习的师弟们(是的,没有师妹)GPA 恐怕没有低于 3.7 的,都是学术和技术兼优的。我觉得这些大佬们愿意来跟我实习,一是发过一篇 SIGCOMM,二是在科大 LUG 的影响力比较大。
 张霖涛导师(右)、我(左)和一起实习的王子博(中)
张霖涛导师(右)、我(左)和一起实习的王子博(中)霖涛导师每周会让我们汇报一次进展,每个月跟我有一次一对一的讨论。他也经常请我们在公司餐厅或者外面的餐厅吃饭。他请我们请多了,有时候我们都不好意思了。在一对一讨论或者吃饭的时候,霖涛导师经常给我们讲很多他原创的理论。
比如最出名的是他的 「三十年」 理论:要解决一个难题,就去读三十年前的文章。比如神经网络,最早就是上世纪 80 年代提出的,2010 年左右重新火了起来。近十年、二十年的创新作者还活跃在科研一线,如果他当年的方法能解决现在的问题,他自己早就解决了。但三十年前的创新作者大多数都已经不在一线了,这时候封存在故纸堆里的老方法可能就有用了。另外,在很多领域,系统架构也是螺旋式发展的,例如瘦客户端和胖客户端、集中式和分布式、统一指令集和异构计算等,当前新的架构在上一个历史周期里可能都是玩剩的。
霖涛导师还说,事情的发展很多时候不符合他的预料。比如他读博士的时候觉得 1 um 以下的光刻因为衍射就很难做了,结果半导体行业这么多钱砸进来,硬是做到几纳米了。王坚去阿里搞云的时候,他觉得这帮人没有做过系统研究,肯定搞不出云来,结果阿里云越做越牛逼了。这也不是他一个人的预测,而是领域内很多专家的预测。因此,最不靠谱的事情就是预测未来。
KV-Direct 的实验
尽管我们已经把 KV-Direct 的单卡性能优化到了极致,单张卡的性能仍然局限于 PCIe 带宽和网络带宽,不可能做到太高。如果这样投稿出去,审稿人可能乍一看,认为跟现有工作的性能相比也没提升多少。
我想把 CPU 的 PCIe 性能榨干,搞一个键值存储性能的大新闻。一个 Xeon E5 CPU 有 40 个 PCIe lane,双路服务器就是 80 个,理论上可以支持 10 块 FPGA。既然做 AI 训练的机器都是 8 块卡,为什么我们不能在一台服务器上插多块 FPGA 卡呢?可惜,我们组当时并没有能插 8 卡的主机,申购 8 卡主机需要漫长的流程,赶不上论文投稿了。
我首先想到的是把现有 2U 服务器的 PCIe 插槽用来多插几张卡。但 2U 服务器的 PCIe 插槽很多是 PCIe Gen3 x16 的,我们一张卡只能用 x8,剩下的 x8 就浪费了。此外,我们的 FPGA 卡是全高半长的,有些 PCIe 槽位是半高的,放不进去 FPGA 卡。为此,我跑到中关村的海龙电子城买了几条 PCIe 转接线和 bifurcation 扩展卡。回到 MSRA 机房,我把机箱的盖子打开,把用了转接线的卡用静电袋隔开之后直接摞在上面,就像超载的大卡车。
 在组里的 2U 服务器上插了 8 块 FPGA 卡
在组里的 2U 服务器上插了 8 块 FPGA 卡只插了两块卡,BIOS 在自检的时候就蓝屏了,说其中有的卡 PCIe training error,我重新刷了 BIOS 解决了这个问题,两块卡总算是能正常运行了。等到所有 8 块卡都插上了,设备管理器也认出 8 块卡了,但运行性能测试的时候,忽然闻到一股焦糊味,主板烧了。大概我是 MSRA 系统组第一个把主板烧了的,也可能是最后一个。万幸,宝贵的 FPGA 都没有损坏。
霖涛导师说,可能是主板的供电不足,他要是提前知道了,就不会让我烧主板了。然后就给我一本从美国带回来的 PCIe 总线的大厚书,让我学习。
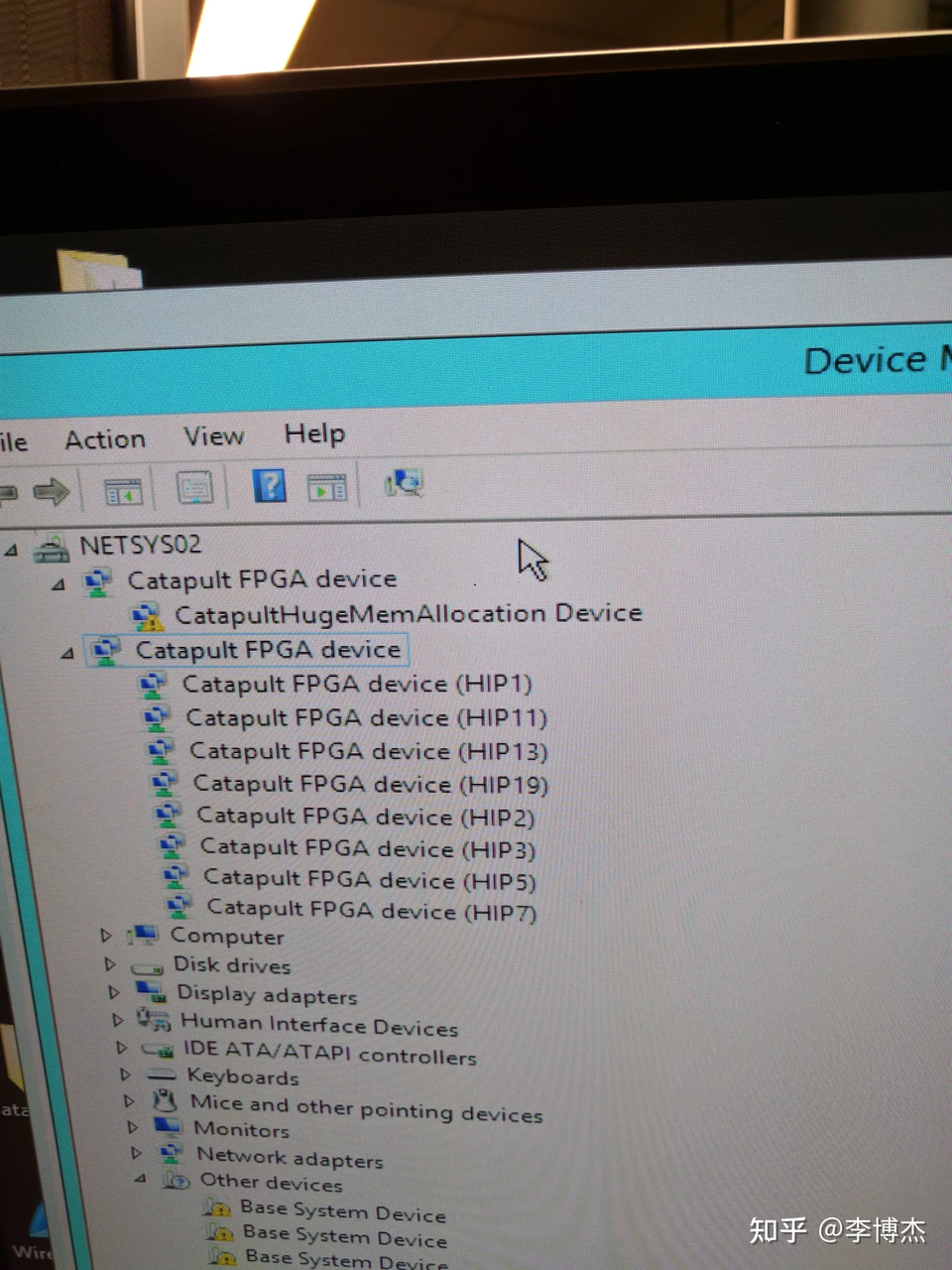 8 块 FPGA 卡第一次也是最后一次都认出来了,因为随后跑性能测试的时候主板就烧了
8 块 FPGA 卡第一次也是最后一次都认出来了,因为随后跑性能测试的时候主板就烧了那怎么解决多卡服务器的问题呢?我想到了闲鱼。虽然一台 4U 的 8 卡主机配下来要十几万,但能支持 10 块卡的主板在闲鱼上只要 2000 块钱,我就自掏腰包买了一块;顺带买了两个二手 Xeon E5 2650 V2 CPU,一个 1000;16 条二手 8 GB DDR3 内存,一共 2400 块;再从矿机机房里拽出来一个 500 块钱的巨龙电源,以及一些散热风扇,这一台 8 卡机器攒下来只用了大约 7000 元。
把一块 FPGA 插上去,运行良好,再插上一块,还是没问题,最后 10 块 FPGA 都插满了,运行仍然很丝滑。PCIe 基本上打满了,但主机的 DDR 确实还没有打满,这印证了我们的猜测。
 KV-Direct 的主板,2000 块钱闲鱼上淘的
KV-Direct 的主板,2000 块钱闲鱼上淘的 KV-Direct 插上 FPGA 之前的准系统,仅仅价值 7000 块钱
KV-Direct 插上 FPGA 之前的准系统,仅仅价值 7000 块钱谁又能想到呢,当时世界上最快的单机键值存储系统竟然是搭建在一台 7000 块钱的二手准系统上的,当然这没有计入 10 块 FPGA 的价格,FPGA 比准系统贵多了。
 KV-Direct 实验环境,10 张卡达到了每秒 12 亿次键值操作
KV-Direct 实验环境,10 张卡达到了每秒 12 亿次键值操作KV-Direct 的写作
在写作 KV-Direct 的时候,我们需要回答的一个问题是,为什么需要这么高性能的键值存储呢?如果只是传统的 Web 服务,对键值存储的性能没有这么高的要求,节约下来的成本也不是很多。霖涛导师和聪老师给我了一个重要的输入:大数据计算类的应用对键值存储有很高的吞吐量要求,例如机器学习中的参数服务器(parameter server)。图计算中存储点和边虽然目前用的都是自定义数据结构,理论上也可以用键值存储。这样,做一个比学术界最先进的键值存储还快 10 倍的系统,就有价值了。
霖涛导师帮我们修改论文的时候,真的是字面意义的一个字一个字地改。霖涛导师的英文水平很高,平时开会的时候,他可以毫不费力地用英文跟老外交流。读他改过的论文,我也是在学习英语。比如节约内存访问次数,霖涛导师一改,就成了 be frugal on memory accesses。论文 2.2 节的标题本来是 Challenges of High-Performance KVS Systems,他改成了 Achilles’ Heel of High-Performance KVS Systems。这段的首句 Building a high performance KVS is a non-trivial exercise of optimizing various software and hardware components in a computer system. 一下子就把格局打开了。
说到这个 「exercise」,霖涛导师经常跟我们说,很多顶会上的论文就是博士生的 exercise,学生都需要发论文毕业,不能要求每篇文章水平都很高。先学会发论文,解决别人设定好的问题;然后再学怎么发现新问题,怎么把解决方案应用到实际中去。我们就处于连发论文都还没学会的阶段呢。毕竟霖涛导师是国际物理竞赛金牌,论文上万引用量,早期工作都拿了 test of time award(时间检验奖)的,是从硅谷研究院第一批回国来 MSRA 的首席研究员。
SOSP deadline 那天,霖涛导师跟我们一起熬了一整夜,一起修改论文。早上 8 点,deadline 到了,霖涛导师说,走,我请你们吃早餐去。霖涛导师就带着我们一起去西部马华牛肉面吃了个早餐,然后分头回家补觉了。
 KV-Direct 四人组赶完 SOSP deadline 后在 MSRA 的电梯里,左起:肖文聪、陆元伟、阮震元、李博杰
KV-Direct 四人组赶完 SOSP deadline 后在 MSRA 的电梯里,左起:肖文聪、陆元伟、阮震元、李博杰SOSP 2017 会议
SOSP 和 OSDI 是计算机系统领域两个最顶级的会议,操作系统和分布式系统历史上很多经典的工作都是在 SOSP 和 OSDI 上发表的。2017 年,MSRA 的周礼栋院长和上海交大的陈海波教授共同把 SOSP 请到了中国上海,这也是 SOSP 第一次来到中国。
 SOSP 2017 中科大老师同学留影
SOSP 2017 中科大老师同学留影在这次 SOSP 上,除了主会场 KV-Direct 的报告,我们还演示了很多其他研究成果,包括崔天一和我合作的 IPC-Direct(后来的 SocksDirect)、左格非和我合作的全序消息散播。这些项目的故事将在后文中详细展开。聪老师和球王也分别展示了各自的研究成果。
SOSP 之后,我在复旦大学作报告的时候,就讲到,我的学术成果其实都是我们团队取得的,特别是依赖我从科大吸引来的优秀同学们。科大 LUG 这几届的骨干基本上都被我给挖空了,有的来我们组实习,有的被我推荐到其他组去实习,后来在 MSRA 实习的 LUG 小伙伴们都能凑齐一桌饭了。
 截至 2017 年 10 月,我在 MSRA 的科大合作同学们,没有这些优秀的同学,我是绝对无法取得这些研究成果的
截至 2017 年 10 月,我在 MSRA 的科大合作同学们,没有这些优秀的同学,我是绝对无法取得这些研究成果的在科大的学术报告上与老婆相识
按照科大对联合培养博士生的要求,每位联合培养博士生至少需要在学校作一次学术报告。李向阳院长实验室的谈海生老师邀请我作报告并在报告后跟实验室的同学们作一次学术交流,我感到非常荣幸。
2017 年 11 月 2 日,我在科大作了题为《用可编程硬件加速数据中心基础架构》的学术报告,主要内容就是 ClickNP 和 KV-Direct 两篇论文,加上本文前面提到的 HTTPS、AI 加速等工作,希望用 FPGA 作为数据中心的加速平面,互联各种异构计算设备和存储设备,打破传统以 CPU 为中心的数据中心架构。
 我在科大的《用可编程硬件加速数据中心基础架构》报告海报
我在科大的《用可编程硬件加速数据中心基础架构》报告海报
科大邀请我作学术报告后,谈海生老师、华蓓老师给我颁发纪念奖杯。华蓓老师是我本科毕业设计的导师。纪念奖杯上写着 「李博杰博士」,但我当时还没取得博士学位,同学们就调侃我,学校已经钦定你能毕业了 :)
谁能预料,这一天我将见到今天的老婆呢?孟佳颖是谈海生老师的学生,当天来听报告了,也参加了学术交流。那次本来是谈老师的组会,一听我要来,张兰老师那边的三个女生也就来了。谈老师组的女生只有孟佳颖和刘柳燕,张兰老师组里来的是薛爽爽,李雁南和李安然。谈老师介绍李雁南的时候,说她就是阮震元的女朋友(我早就知道),她还觉得这样介绍不太好。
当时我虽然加了大家的微信,但以我脸盲的程度,就没记住几个人。作报告的时候,我把论文集落在了会议室里。当时刘慧琪师弟联系我拿论文集,但我去拿论文集的时候,一见到他,却问:你就是孟佳颖吗?我也不知道我怎么就把孟佳颖脱口而出了,莫名其妙搞错了性别,成了谈老师实验室里的一个笑话。当天孟佳颖确实在 QQ 上找我要了报告的 PPT,再没别的联系了。也许这就是命中注定的缘分吧。
 谈海生老师邀请我与他的学生们作学术交流
谈海生老师邀请我与他的学生们作学术交流 谈海生老师邀请我与他的学生们作学术交流
谈海生老师邀请我与他的学生们作学术交流还有一件巧合的事情,当天晚上是我跟前任分手之后第一次也是最后一次见面。当时我说,虽然分手一年半了,还总是忘不了她。她就说,再找一个可能就好了。
开题答辩挂了,我有女朋友了
11 月我和佳颖只是加了微信,并没有后续联系。12 月 1 日,她来找我问科研上的问题,我过了一天才回复,她又过了一天才回我,但就这样聊起了科研。其实我平时挺忙的,微信上的信息经常好几天都不回,有时候未读消息能堆积好几十条,不知道为什么那天突然就有兴趣聊天了。后面两周我们都没联系。
12 月 18 日,我回学校办理开题答辩的手续,听关于开题要求的讲座。当时佳颖也去参加了这个讲座。她说当时看到有一个人很像我,但是不确定,后来实验室的其他人说那确实就是我。佳颖在微信上找我求证,然后我们就又聊起来了,随后我们就联系得越来越多了,几乎没有断过。
来年 1 月 10 日,我再次回到学校来做开题答辩。当时,我并没有把开题答辩想得很严肃,开题报告中的插图很多是 PPT 的截图,格式也不太符合学校的要求。一位答辩评委老师问,你的论文里也是把 PPT 直接截图放上去的吗?李院长说,这两篇论文(ClickNP 和 KV-Direct)这么讲就浪费了,得把这几个工作讲成一整个故事;现在只是拼凑在一起,像是做了一大堆工程。最后,我的开题就没有通过。
不过,当天晚上是我跟佳颖第一次单独见面。我们去了之心城,吃了新辣道鱼火锅,还看了电影。第一次单独见面之前,为了防止脸盲,我专门看了看她的照片,因此远远地就认出她来,给她打招呼了。自此之后,我们的感情就快速升温。过年前(2 月 10 日到 2 月 14 日),我们就跑到太原、平遥和介休,一起逛了平遥古城、乔家大院。在平遥古城的时候,佳颖的小手就总是冻得通红,我想给她暖手,后面就变成牵手了。情人节那天恰好是除夕,我们在太原一起逛街,然后各回各的老家。2 月 19 日,我们在家的时候,就在视频里表白了。
6 月,我的第二次开题终于通过了。那次我参考了师兄开题报告的格式,并且认真思考了博士论文应该讲成怎样的一个故事。我把博士论文的标题略作修改,改为《基于可编程网卡的高性能数据中心系统》,把 FPGA 泛化为可编程网卡的概念,并且提出用可编程网卡实现云计算数据中心计算、网络、内存存储节点的全栈加速,包括虚拟网络、网络功能、数据结构、操作系统通信原语等。
本文经授权转载,若二次转载请联系原作者。
参考资料:
https://zhuanlan.zhihu.com/p/647942394

